 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQueryCheetah: Fast Automated Discovery of Attribute Inference Attacks Against Query-Based Systems
Sep 03, 2024



Query-based systems (QBSs) are one of the key approaches for sharing data. QBSs allow analysts to request aggregate information from a private protected dataset. Attacks are a crucial part of ensuring QBSs are truly privacy-preserving. The development and testing of attacks is however very labor-intensive and unable to cope with the increasing complexity of systems. Automated approaches have been shown to be promising but are currently extremely computationally intensive, limiting their applicability in practice. We here propose QueryCheetah, a fast and effective method for automated discovery of privacy attacks against QBSs. We instantiate QueryCheetah on attribute inference attacks and show it to discover stronger attacks than previous methods while being 18 times faster than the state-of-the-art automated approach. We then show how QueryCheetah allows system developers to thoroughly evaluate the privacy risk, including for various attacker strengths and target individuals. We finally show how QueryCheetah can be used out-of-the-box to find attacks in larger syntaxes and workarounds around ad-hoc defenses.
A Zero Auxiliary Knowledge Membership Inference Attack on Aggregate Location Data
Jun 26, 2024
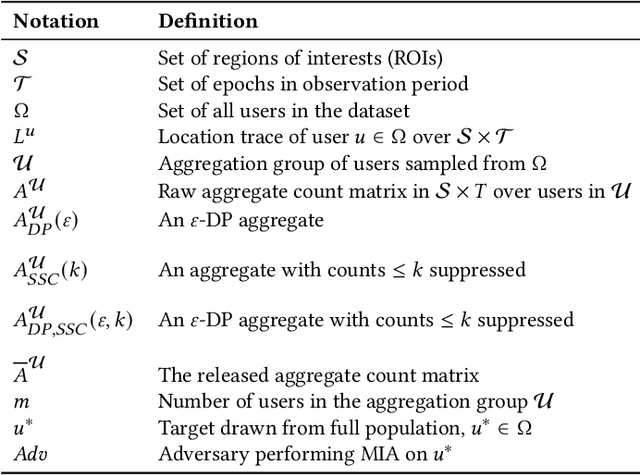

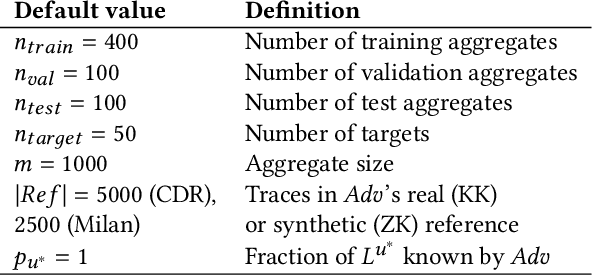
Location data is frequently collected from populations and shared in aggregate form to guide policy and decision making. However, the prevalence of aggregated data also raises the privacy concern of membership inference attacks (MIAs). MIAs infer whether an individual's data contributed to the aggregate release. Although effective MIAs have been developed for aggregate location data, these require access to an extensive auxiliary dataset of individual traces over the same locations, which are collected from a similar population. This assumption is often impractical given common privacy practices surrounding location data. To measure the risk of an MIA performed by a realistic adversary, we develop the first Zero Auxiliary Knowledge (ZK) MIA on aggregate location data, which eliminates the need for an auxiliary dataset of real individual traces. Instead, we develop a novel synthetic approach, such that suitable synthetic traces are generated from the released aggregate. We also develop methods to correct for bias and noise, to show that our synthetic-based attack is still applicable when privacy mechanisms are applied prior to release. Using two large-scale location datasets, we demonstrate that our ZK MIA matches the state-of-the-art Knock-Knock (KK) MIA across a wide range of settings, including popular implementations of differential privacy (DP) and suppression of small counts. Furthermore, we show that ZK MIA remains highly effective even when the adversary only knows a small fraction (10%) of their target's location history. This demonstrates that effective MIAs can be performed by realistic adversaries, highlighting the need for strong DP protection.
Re-pseudonymization Strategies for Smart Meter Data Are Not Robust to Deep Learning Profiling Attacks
Apr 05, 2024



Smart meters, devices measuring the electricity and gas consumption of a household, are currently being deployed at a fast rate throughout the world. The data they collect are extremely useful, including in the fight against climate change. However, these data and the information that can be inferred from them are highly sensitive. Re-pseudonymization, i.e., the frequent replacement of random identifiers over time, is widely used to share smart meter data while mitigating the risk of re-identification. We here show how, in spite of re-pseudonymization, households' consumption records can be pieced together with high accuracy in large-scale datasets. We propose the first deep learning-based profiling attack against re-pseudonymized smart meter data. Our attack combines neural network embeddings, which are used to extract features from weekly consumption records and are tailored to the smart meter identification task, with a nearest neighbor classifier. We evaluate six neural networks architectures as the embedding model. Our results suggest that the Transformer and CNN-LSTM architectures vastly outperform previous methods as well as other architectures, successfully identifying the correct household 73.4% of the time among 5139 households based on electricity and gas consumption records (54.5% for electricity only). We further show that the features extracted by the embedding model maintain their effectiveness when transferred to a set of users disjoint from the one used to train the model. Finally, we extensively evaluate the robustness of our results. Taken together, our results strongly suggest that even frequent re-pseudonymization strategies can be reversed, strongly limiting their ability to prevent re-identification in practice.
Synthetic is all you need: removing the auxiliary data assumption for membership inference attacks against synthetic data
Jul 04, 2023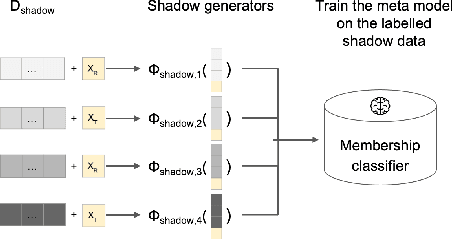
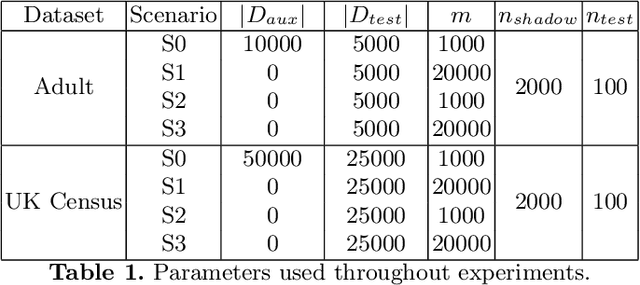
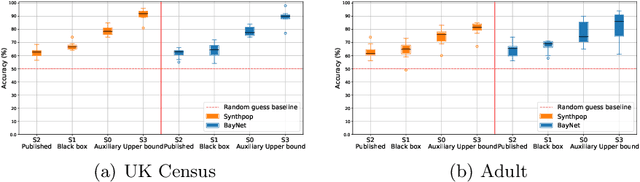
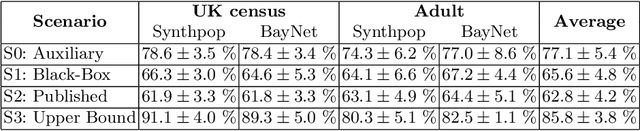
Synthetic data is emerging as the most promising solution to share individual-level data while safeguarding privacy. Membership inference attacks (MIAs), based on shadow modeling, have become the standard to evaluate the privacy of synthetic data. These attacks, however, currently assume the attacker to have access to an auxiliary dataset sampled from a similar distribution as the training dataset. This often is a very strong assumption that would make an attack unlikely to happen in practice. We here show how this assumption can be removed and how MIAs can be performed using only the synthetic data. More specifically, in three different attack scenarios using only synthetic data, our results demonstrate that MIAs are still successful, across two real-world datasets and two synthetic data generators. These results show how the strong hypothesis made when auditing synthetic data releases - access to an auxiliary dataset - can be relaxed to perform an actual attack.
Achilles' Heels: Vulnerable Record Identification in Synthetic Data Publishing
Jun 17, 2023Synthetic data is seen as the most promising solution to share individual-level data while preserving privacy. Shadow modeling-based membership inference attacks (MIAs) have become the standard approach to evaluate the privacy risk of synthetic data. While very effective, they require a large number of datasets to be created and models trained to evaluate the risk posed by a single record. The privacy risk of a dataset is thus currently evaluated by running MIAs on a handful of records selected using ad-hoc methods. We here propose what is, to the best of our knowledge, the first principled vulnerable record identification technique for synthetic data publishing, leveraging the distance to a record's closest neighbors. We show our method to strongly outperform previous ad-hoc methods across datasets and generators. We also show evidence of our method to be robust to the choice of MIA and to specific choice of parameters. Finally, we show it to accurately identify vulnerable records when synthetic data generators are made differentially private. The choice of vulnerable records is as important as more accurate MIAs when evaluating the privacy of synthetic data releases, including from a legal perspective. We here propose a simple yet highly effective method to do so. We hope our method will enable practitioners to better estimate the risk posed by synthetic data publishing and researchers to fairly compare ever improving MIAs on synthetic data.
Re-aligning Shadow Models can Improve White-box Membership Inference Attacks
Jun 08, 2023



Machine learning models have been shown to leak sensitive information about their training datasets. As models are being increasingly used, on devices, to automate tasks and power new applications, there have been concerns that such white-box access to its parameters, as opposed to the black-box setting which only provides query access to the model, increases the attack surface. Directly extending the shadow modelling technique from the black-box to the white-box setting has been shown, in general, not to perform better than black-box only attacks. A key reason is misalignment, a known characteristic of deep neural networks. We here present the first systematic analysis of the causes of misalignment in shadow models and show the use of a different weight initialisation to be the main cause of shadow model misalignment. Second, we extend several re-alignment techniques, previously developed in the model fusion literature, to the shadow modelling context, where the goal is to re-align the layers of a shadow model to those of the target model.We show re-alignment techniques to significantly reduce the measured misalignment between the target and shadow models. Finally, we perform a comprehensive evaluation of white-box membership inference attacks (MIA). Our analysis reveals that (1) MIAs suffer from misalignment between shadow models, but that (2) re-aligning the shadow models improves, sometimes significantly, MIA performance. On the CIFAR10 dataset with a false positive rate of 1\%, white-box MIA using re-aligned shadow models improves the true positive rate by 4.5\%.Taken together, our results highlight that on-device deployment increase the attack surface and that the newly available information can be used by an attacker.
QuerySnout: Automating the Discovery of Attribute Inference Attacks against Query-Based Systems
Nov 09, 2022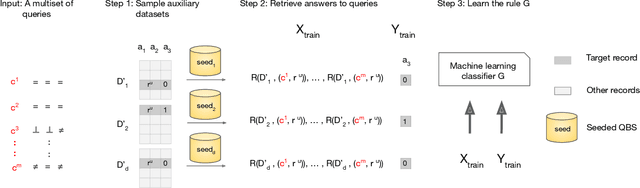
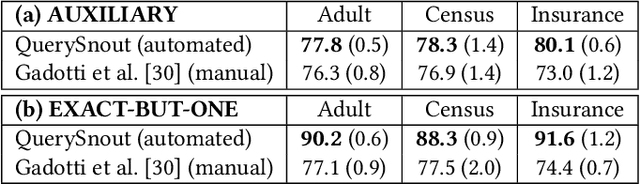
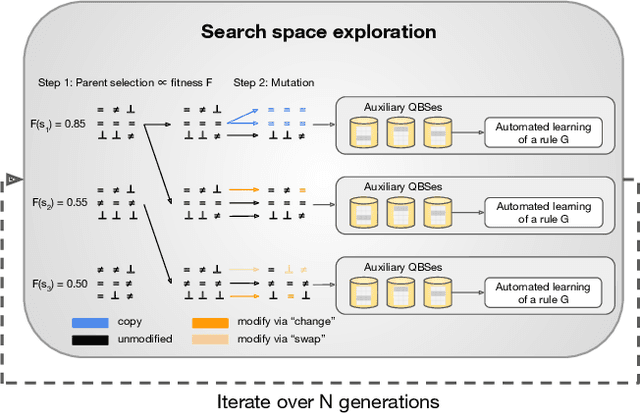
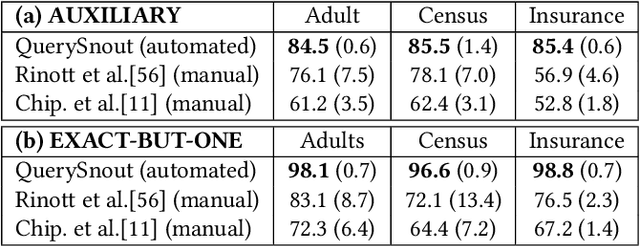
Although query-based systems (QBS) have become one of the main solutions to share data anonymously, building QBSes that robustly protect the privacy of individuals contributing to the dataset is a hard problem. Theoretical solutions relying on differential privacy guarantees are difficult to implement correctly with reasonable accuracy, while ad-hoc solutions might contain unknown vulnerabilities. Evaluating the privacy provided by QBSes must thus be done by evaluating the accuracy of a wide range of privacy attacks. However, existing attacks require time and expertise to develop, need to be manually tailored to the specific systems attacked, and are limited in scope. In this paper, we develop QuerySnout (QS), the first method to automatically discover vulnerabilities in QBSes. QS takes as input a target record and the QBS as a black box, analyzes its behavior on one or more datasets, and outputs a multiset of queries together with a rule to combine answers to them in order to reveal the sensitive attribute of the target record. QS uses evolutionary search techniques based on a novel mutation operator to find a multiset of queries susceptible to lead to an attack, and a machine learning classifier to infer the sensitive attribute from answers to the queries selected. We showcase the versatility of QS by applying it to two attack scenarios, three real-world datasets, and a variety of protection mechanisms. We show the attacks found by QS to consistently equate or outperform, sometimes by a large margin, the best attacks from the literature. We finally show how QS can be extended to QBSes that require a budget, and apply QS to a simple QBS based on the Laplace mechanism. Taken together, our results show how powerful and accurate attacks against QBSes can already be found by an automated system, allowing for highly complex QBSes to be automatically tested "at the pressing of a button".
WikiCREM: A Large Unsupervised Corpus for Coreference Resolution
Aug 23, 2019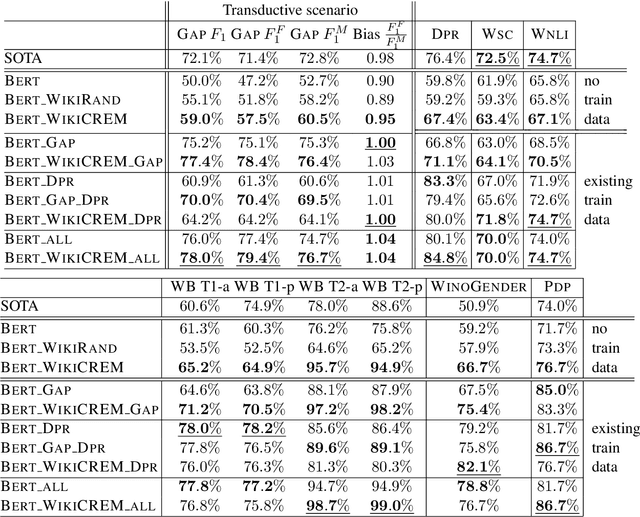
Pronoun resolution is a major area of natural language understanding. However, large-scale training sets are still scarce, since manually labelling data is costly. In this work, we introduce WikiCREM (Wikipedia CoREferences Masked) a large-scale, yet accurate dataset of pronoun disambiguation instances. We use a language-model-based approach for pronoun resolution in combination with our WikiCREM dataset. We compare a series of models on a collection of diverse and challenging coreference resolution problems, where we match or outperform previous state-of-the-art approaches on 6 out of 7 datasets, such as GAP, DPR, WNLI, PDP, WinoBias, and WinoGender. We release our model to be used off-the-shelf for solving pronoun disambiguation.
A Surprisingly Robust Trick for Winograd Schema Challenge
May 15, 2019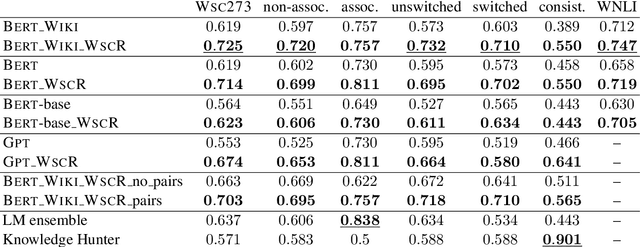
The Winograd Schema Challenge (WSC) dataset WSC273 and its inference counterpart WNLI are popular benchmarks for natural language understanding and commonsense reasoning. In this paper, we show that the performance of three language models on WSC273 strongly improves when fine-tuned on a similar pronoun disambiguation problem dataset (denoted WSCR). We additionally generate a large unsupervised WSC-like dataset. By fine-tuning the BERT language model both on the introduced and on the WSCR dataset, we achieve overall accuracies of 72.2% and 71.9% on WSC273 and WNLI, improving the previous state-of-the-art solutions by 8.5% and 6.8%, respectively. Furthermore, our fine-tuned models are also consistently more robust on the "complex" subsets of WSC273, introduced by Trichelair et al. (2018).