 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrototype Transformer: Towards Language Model Architectures Interpretable by Design
Feb 12, 2026While state-of-the-art language models (LMs) surpass the vast majority of humans in certain domains, their reasoning remains largely opaque, undermining trust in their output. Furthermore, while autoregressive LMs can output explicit reasoning, their true reasoning process is opaque, which introduces risks like deception and hallucination. In this work, we introduce the Prototype Transformer (ProtoT) -- an autoregressive LM architecture based on prototypes (parameter vectors), posed as an alternative to the standard self-attention-based transformers. ProtoT works by means of two-way communication between the input sequence and the prototypes, and we show that this leads to the prototypes automatically capturing nameable concepts (e.g. "woman") during training. They provide the potential to interpret the model's reasoning and allow for targeted edits of its behavior. Furthermore, by design, the prototypes create communication channels that aggregate contextual information at different time scales, aiding interpretability. In terms of computation scalability, ProtoT scales linearly with sequence length vs the quadratic scalability of SOTA self-attention transformers. Compared to baselines, ProtoT scales well with model and data size, and performs well on text generation and downstream tasks (GLUE). ProtoT exhibits robustness to input perturbations on par or better than some baselines, but differs from them by providing interpretable pathways showing how robustness and sensitivity arises. Reaching close to the performance of state-of-the-art architectures, ProtoT paves the way to creating well-performing autoregressive LMs interpretable by design.
Predictive Coding beyond Gaussian Distributions
Nov 07, 2022



A large amount of recent research has the far-reaching goal of finding training methods for deep neural networks that can serve as alternatives to backpropagation (BP). A prominent example is predictive coding (PC), which is a neuroscience-inspired method that performs inference on hierarchical Gaussian generative models. These methods, however, fail to keep up with modern neural networks, as they are unable to replicate the dynamics of complex layers and activation functions. In this work, we solve this problem by generalizing PC to arbitrary probability distributions, enabling the training of architectures, such as transformers, that are hard to approximate with only Gaussian assumptions. We perform three experimental analyses. First, we study the gap between our method and the standard formulation of PC on multiple toy examples. Second, we test the reconstruction quality on variational autoencoders, where our method reaches the same reconstruction quality as BP. Third, we show that our method allows us to train transformer networks and achieve a performance comparable with BP on conditional language models. More broadly, this method allows neuroscience-inspired learning to be applied to multiple domains, since the internal distributions can be flexibly adapted to the data, tasks, and architectures used.
Bird-Eye Transformers for Text Generation Models
Oct 08, 2022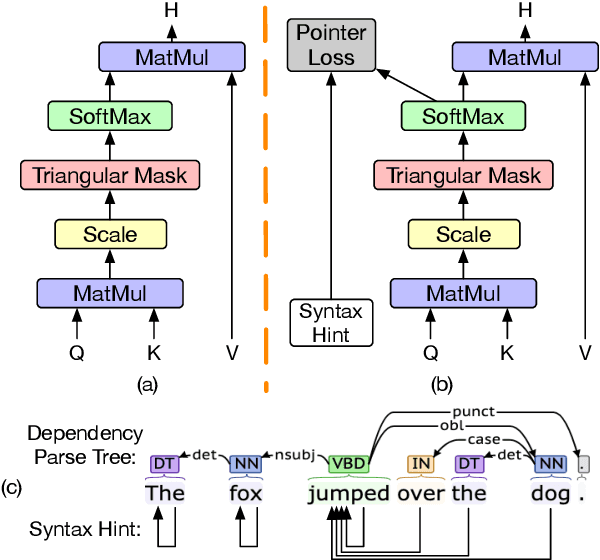
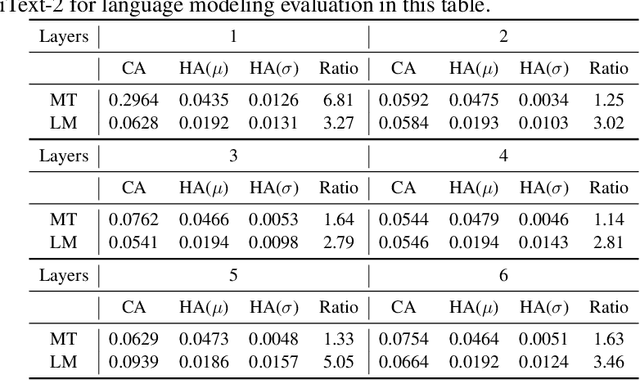
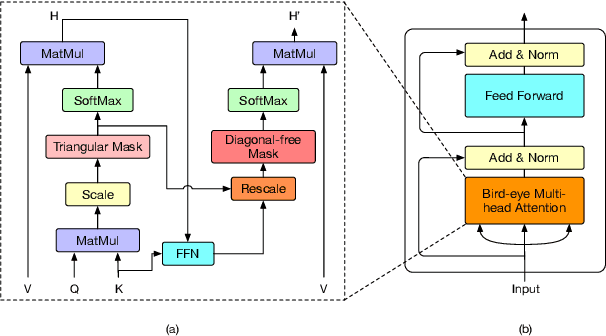
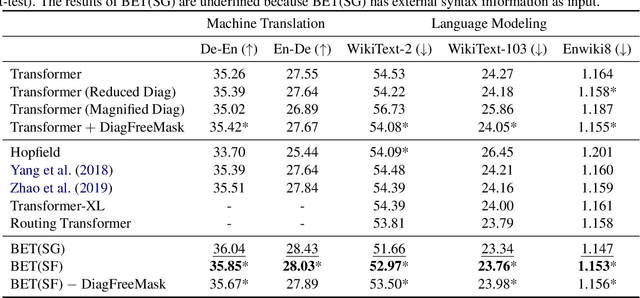
Transformers have become an indispensable module for text generation models since their great success in machine translation. Previous works attribute the~success of transformers to the query-key-value dot-product attention, which provides a robust inductive bias by the fully connected token graphs. However, we found that self-attention has a severe limitation. When predicting the (i+1)-th token, self-attention only takes the i-th token as an information collector, and it tends to give a high attention weight to those tokens similar to itself. Therefore, most of the historical information that occurred before the i-th token is not taken into consideration. Based on this observation, in this paper, we propose a new architecture, called bird-eye transformer(BET), which goes one step further to improve the performance of transformers by reweighting self-attention to encourage it to focus more on important historical information. We have conducted experiments on multiple text generation tasks, including machine translation (2 datasets) and language models (3 datasets). These experimental~results show that our proposed model achieves a better performance than the baseline transformer architectures on~all~datasets. The code is released at: \url{https://sites.google.com/view/bet-transformer/home}.
Few-Shot Out-of-Domain Transfer Learning of Natural Language Explanations
Dec 12, 2021

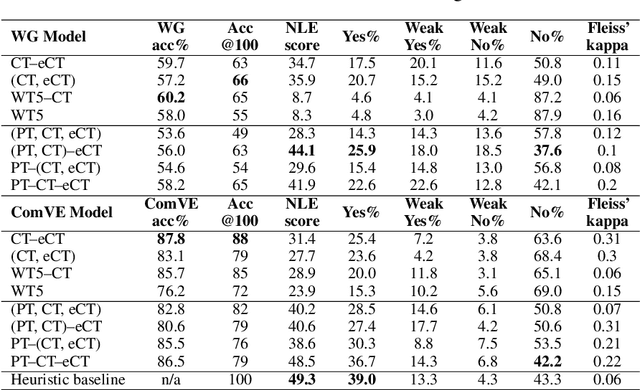
Recently, there has been an increasing interest in models that generate natural language explanations (NLEs) for their decisions. However, training a model to provide NLEs requires the acquisition of task-specific NLEs, which is time- and resource-consuming. A potential solution is the out-of-domain transfer of NLEs from a domain with a large number of NLEs to a domain with scarce NLEs but potentially a large number of labels, via few-shot transfer learning. In this work, we introduce three vanilla approaches for few-shot transfer learning of NLEs for the case of few NLEs but abundant labels, along with an adaptation of an existing vanilla fine-tuning approach. We transfer explainability from the natural language inference domain, where a large dataset of human-written NLEs exists (e-SNLI), to the domains of (1) hard cases of pronoun resolution, where we introduce a small dataset of NLEs on top of the WinoGrande dataset (small-e-WinoGrande), and (2) commonsense validation (ComVE). Our results demonstrate that the transfer of NLEs outperforms the single-task methods, and establish the best strategies out of the four identified training regimes. We also investigate the scalability of the best methods, both in terms of training data and model size.
Does the Objective Matter? Comparing Training Objectives for Pronoun Resolution
Oct 06, 2020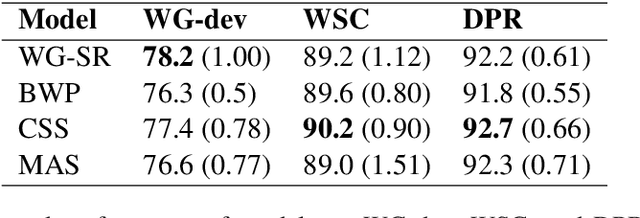
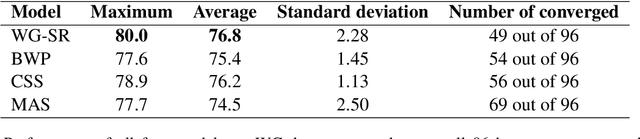
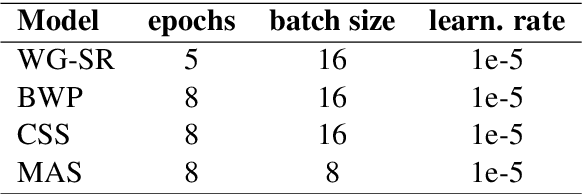
Hard cases of pronoun resolution have been used as a long-standing benchmark for commonsense reasoning. In the recent literature, pre-trained language models have been used to obtain state-of-the-art results on pronoun resolution. Overall, four categories of training and evaluation objectives have been introduced. The variety of training datasets and pre-trained language models used in these works makes it unclear whether the choice of training objective is critical. In this work, we make a fair comparison of the performance and seed-wise stability of four models that represent the four categories of objectives. Our experiments show that the objective of sequence ranking performs the best in-domain, while the objective of semantic similarity between candidates and pronoun performs the best out-of-domain. We also observe a seed-wise instability of the model using sequence ranking, which is not the case when the other objectives are used.
WikiCREM: A Large Unsupervised Corpus for Coreference Resolution
Aug 23, 2019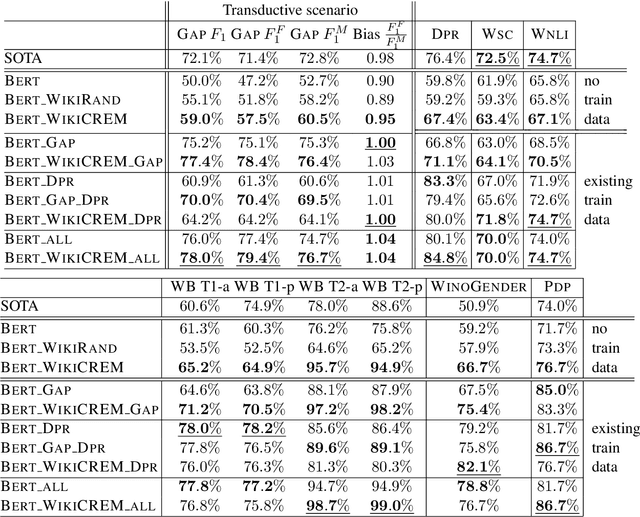
Pronoun resolution is a major area of natural language understanding. However, large-scale training sets are still scarce, since manually labelling data is costly. In this work, we introduce WikiCREM (Wikipedia CoREferences Masked) a large-scale, yet accurate dataset of pronoun disambiguation instances. We use a language-model-based approach for pronoun resolution in combination with our WikiCREM dataset. We compare a series of models on a collection of diverse and challenging coreference resolution problems, where we match or outperform previous state-of-the-art approaches on 6 out of 7 datasets, such as GAP, DPR, WNLI, PDP, WinoBias, and WinoGender. We release our model to be used off-the-shelf for solving pronoun disambiguation.
A Surprisingly Robust Trick for Winograd Schema Challenge
May 15, 2019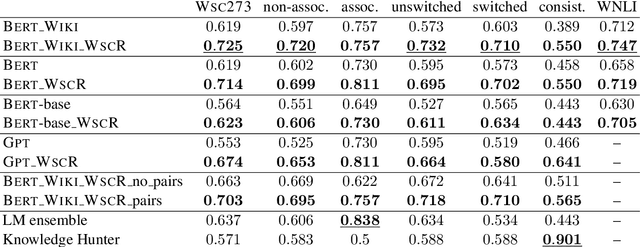
The Winograd Schema Challenge (WSC) dataset WSC273 and its inference counterpart WNLI are popular benchmarks for natural language understanding and commonsense reasoning. In this paper, we show that the performance of three language models on WSC273 strongly improves when fine-tuned on a similar pronoun disambiguation problem dataset (denoted WSCR). We additionally generate a large unsupervised WSC-like dataset. By fine-tuning the BERT language model both on the introduced and on the WSCR dataset, we achieve overall accuracies of 72.2% and 71.9% on WSC273 and WNLI, improving the previous state-of-the-art solutions by 8.5% and 6.8%, respectively. Furthermore, our fine-tuned models are also consistently more robust on the "complex" subsets of WSC273, introduced by Trichelair et al. (2018).