 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM$^2$M: A general method to perform various data analysis tasks from a differentially private sketch
Nov 25, 2022



Differential privacy is the standard privacy definition for performing analyses over sensitive data. Yet, its privacy budget bounds the number of tasks an analyst can perform with reasonable accuracy, which makes it challenging to deploy in practice. This can be alleviated by private sketching, where the dataset is compressed into a single noisy sketch vector which can be shared with the analysts and used to perform arbitrarily many analyses. However, the algorithms to perform specific tasks from sketches must be developed on a case-by-case basis, which is a major impediment to their use. In this paper, we introduce the generic moment-to-moment (M$^2$M) method to perform a wide range of data exploration tasks from a single private sketch. Among other things, this method can be used to estimate empirical moments of attributes, the covariance matrix, counting queries (including histograms), and regression models. Our method treats the sketching mechanism as a black-box operation, and can thus be applied to a wide variety of sketches from the literature, widening their ranges of applications without further engineering or privacy loss, and removing some of the technical barriers to the wider adoption of sketches for data exploration under differential privacy. We validate our method with data exploration tasks on artificial and real-world data, and show that it can be used to reliably estimate statistics and train classification models from private sketches.
TAPAS: a Toolbox for Adversarial Privacy Auditing of Synthetic Data
Nov 12, 2022
Personal data collected at scale promises to improve decision-making and accelerate innovation. However, sharing and using such data raises serious privacy concerns. A promising solution is to produce synthetic data, artificial records to share instead of real data. Since synthetic records are not linked to real persons, this intuitively prevents classical re-identification attacks. However, this is insufficient to protect privacy. We here present TAPAS, a toolbox of attacks to evaluate synthetic data privacy under a wide range of scenarios. These attacks include generalizations of prior works and novel attacks. We also introduce a general framework for reasoning about privacy threats to synthetic data and showcase TAPAS on several examples.
QuerySnout: Automating the Discovery of Attribute Inference Attacks against Query-Based Systems
Nov 09, 2022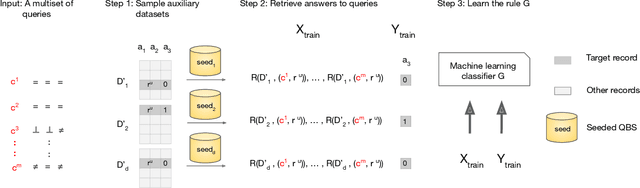
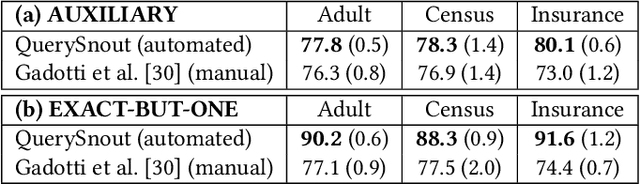
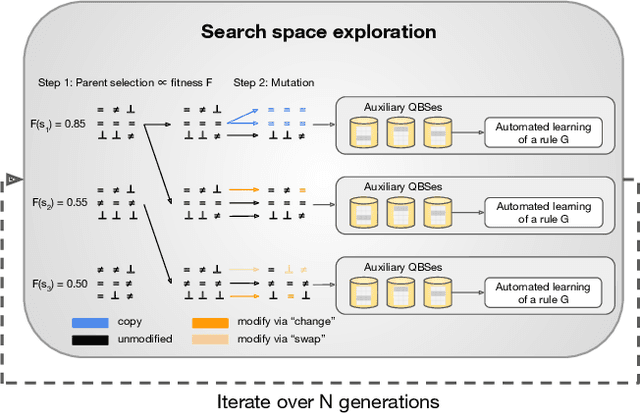
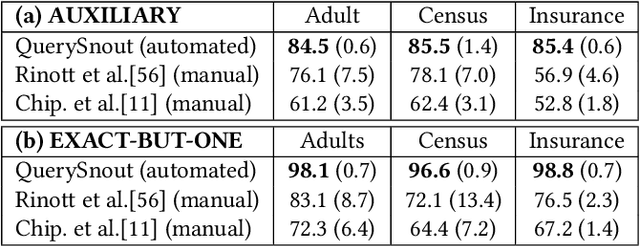
Although query-based systems (QBS) have become one of the main solutions to share data anonymously, building QBSes that robustly protect the privacy of individuals contributing to the dataset is a hard problem. Theoretical solutions relying on differential privacy guarantees are difficult to implement correctly with reasonable accuracy, while ad-hoc solutions might contain unknown vulnerabilities. Evaluating the privacy provided by QBSes must thus be done by evaluating the accuracy of a wide range of privacy attacks. However, existing attacks require time and expertise to develop, need to be manually tailored to the specific systems attacked, and are limited in scope. In this paper, we develop QuerySnout (QS), the first method to automatically discover vulnerabilities in QBSes. QS takes as input a target record and the QBS as a black box, analyzes its behavior on one or more datasets, and outputs a multiset of queries together with a rule to combine answers to them in order to reveal the sensitive attribute of the target record. QS uses evolutionary search techniques based on a novel mutation operator to find a multiset of queries susceptible to lead to an attack, and a machine learning classifier to infer the sensitive attribute from answers to the queries selected. We showcase the versatility of QS by applying it to two attack scenarios, three real-world datasets, and a variety of protection mechanisms. We show the attacks found by QS to consistently equate or outperform, sometimes by a large margin, the best attacks from the literature. We finally show how QS can be extended to QBSes that require a budget, and apply QS to a simple QBS based on the Laplace mechanism. Taken together, our results show how powerful and accurate attacks against QBSes can already be found by an automated system, allowing for highly complex QBSes to be automatically tested "at the pressing of a button".
Synthetic Data -- what, why and how?
May 06, 2022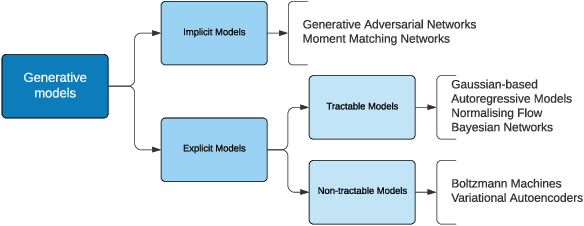
This explainer document aims to provide an overview of the current state of the rapidly expanding work on synthetic data technologies, with a particular focus on privacy. The article is intended for a non-technical audience, though some formal definitions have been given to provide clarity to specialists. This article is intended to enable the reader to quickly become familiar with the notion of synthetic data, as well as understand some of the subtle intricacies that come with it. We do believe that synthetic data is a very useful tool, and our hope is that this report highlights that, while drawing attention to nuances that can easily be overlooked in its deployment.