 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning applied to Insurance Portfolio Pursuit
Aug 02, 2024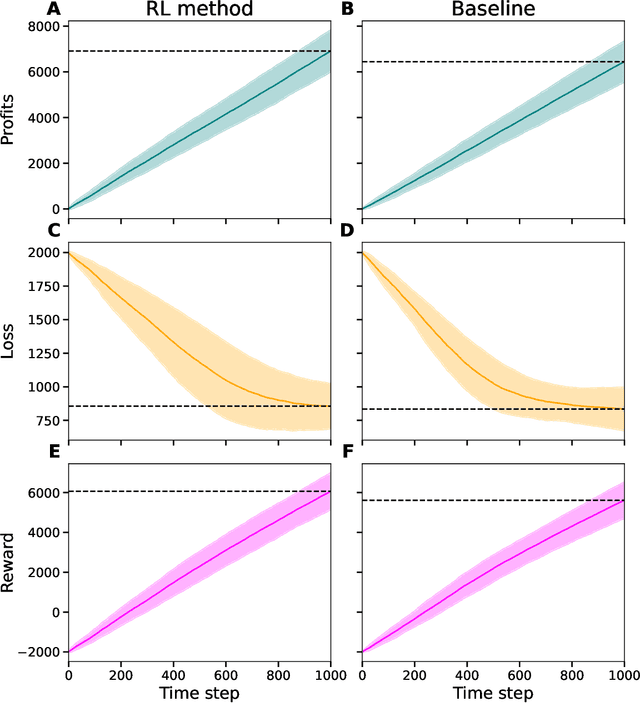

When faced with a new customer, many factors contribute to an insurance firm's decision of what offer to make to that customer. In addition to the expected cost of providing the insurance, the firm must consider the other offers likely to be made to the customer, and how sensitive the customer is to differences in price. Moreover, firms often target a specific portfolio of customers that could depend on, e.g., age, location, and occupation. Given such a target portfolio, firms may choose to modulate an individual customer's offer based on whether the firm desires the customer within their portfolio. We term the problem of modulating offers to achieve a desired target portfolio the portfolio pursuit problem. Having formulated the portfolio pursuit problem as a sequential decision making problem, we devise a novel reinforcement learning algorithm for its solution. We test our method on a complex synthetic market environment, and demonstrate that it outperforms a baseline method which mimics current industry approaches to portfolio pursuit.
TAPAS: a Toolbox for Adversarial Privacy Auditing of Synthetic Data
Nov 12, 2022
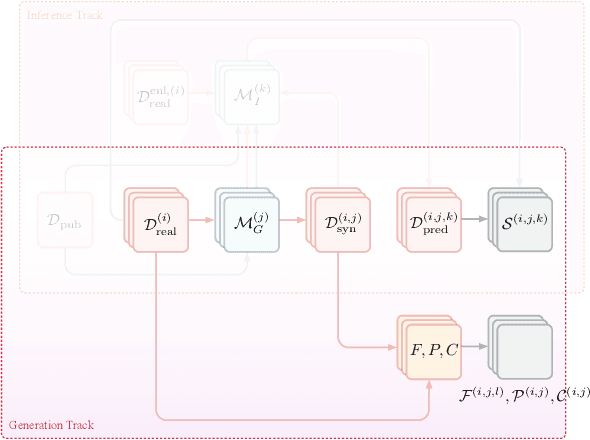
Personal data collected at scale promises to improve decision-making and accelerate innovation. However, sharing and using such data raises serious privacy concerns. A promising solution is to produce synthetic data, artificial records to share instead of real data. Since synthetic records are not linked to real persons, this intuitively prevents classical re-identification attacks. However, this is insufficient to protect privacy. We here present TAPAS, a toolbox of attacks to evaluate synthetic data privacy under a wide range of scenarios. These attacks include generalizations of prior works and novel attacks. We also introduce a general framework for reasoning about privacy threats to synthetic data and showcase TAPAS on several examples.
Synthetic Data -- what, why and how?
May 06, 2022
This explainer document aims to provide an overview of the current state of the rapidly expanding work on synthetic data technologies, with a particular focus on privacy. The article is intended for a non-technical audience, though some formal definitions have been given to provide clarity to specialists. This article is intended to enable the reader to quickly become familiar with the notion of synthetic data, as well as understand some of the subtle intricacies that come with it. We do believe that synthetic data is a very useful tool, and our hope is that this report highlights that, while drawing attention to nuances that can easily be overlooked in its deployment.
To Impute or not to Impute? -- Missing Data in Treatment Effect Estimation
Feb 04, 2022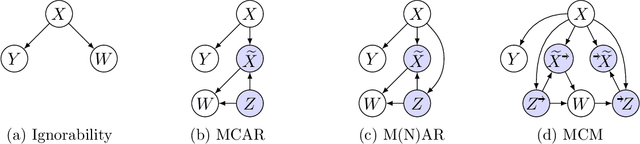
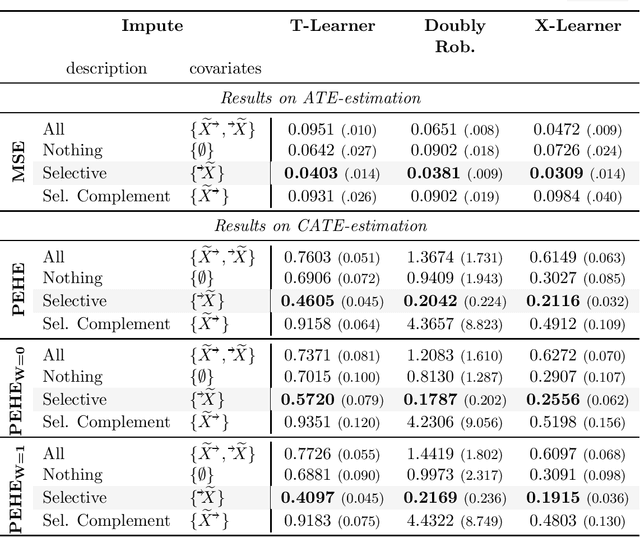
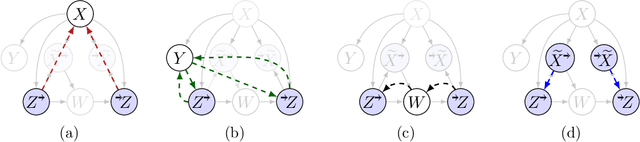
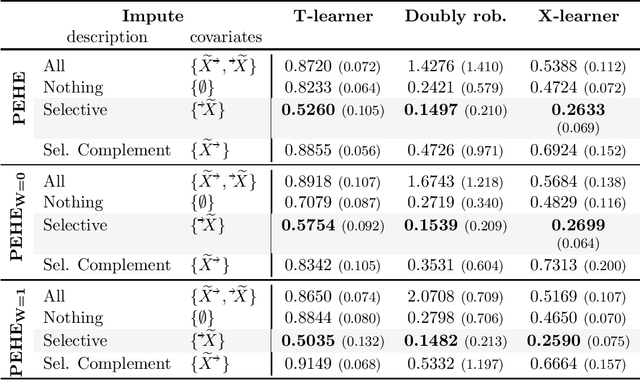
Missing data is a systemic problem in practical scenarios that causes noise and bias when estimating treatment effects. This makes treatment effect estimation from data with missingness a particularly tricky endeavour. A key reason for this is that standard assumptions on missingness are rendered insufficient due to the presence of an additional variable, treatment, besides the individual and the outcome. Having a treatment variable introduces additional complexity with respect to why some variables are missing that is not fully explored by previous work. In our work we identify a new missingness mechanism, which we term mixed confounded missingness (MCM), where some missingness determines treatment selection and other missingness is determined by treatment selection. Given MCM, we show that naively imputing all data leads to poor performing treatment effects models, as the act of imputation effectively removes information necessary to provide unbiased estimates. However, no imputation at all also leads to biased estimates, as missingness determined by treatment divides the population in distinct subpopulations, where estimates across these populations will be biased. Our solution is selective imputation, where we use insights from MCM to inform precisely which variables should be imputed and which should not. We empirically demonstrate how various learners benefit from selective imputation compared to other solutions for missing data.
Synthetic Data: Opening the data floodgates to enable faster, more directed development of machine learning methods
Dec 08, 2020Many ground-breaking advancements in machine learning can be attributed to the availability of a large volume of rich data. Unfortunately, many large-scale datasets are highly sensitive, such as healthcare data, and are not widely available to the machine learning community. Generating synthetic data with privacy guarantees provides one such solution, allowing meaningful research to be carried out "at scale" - by allowing the entirety of the machine learning community to potentially accelerate progress within a given field. In this article, we provide a high-level view of synthetic data: what it means, how we might evaluate it and how we might use it.
Hide-and-Seek Privacy Challenge
Jul 24, 2020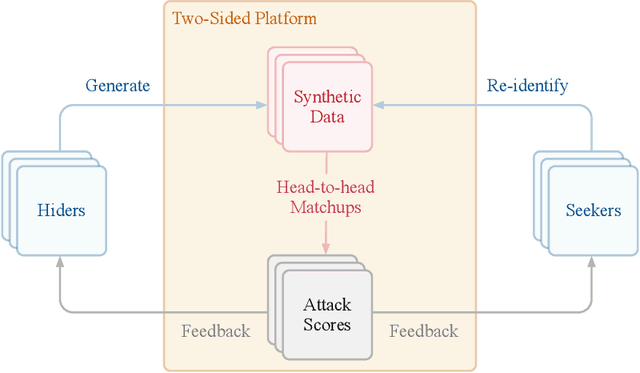
The clinical time-series setting poses a unique combination of challenges to data modeling and sharing. Due to the high dimensionality of clinical time series, adequate de-identification to preserve privacy while retaining data utility is difficult to achieve using common de-identification techniques. An innovative approach to this problem is synthetic data generation. From a technical perspective, a good generative model for time-series data should preserve temporal dynamics, in the sense that new sequences respect the original relationships between high-dimensional variables across time. From the privacy perspective, the model should prevent patient re-identification by limiting vulnerability to membership inference attacks. The NeurIPS 2020 Hide-and-Seek Privacy Challenge is a novel two-tracked competition to simultaneously accelerate progress in tackling both problems. In our head-to-head format, participants in the synthetic data generation track (i.e. "hiders") and the patient re-identification track (i.e. "seekers") are directly pitted against each other by way of a new, high-quality intensive care time-series dataset: the AmsterdamUMCdb dataset. Ultimately, we seek to advance generative techniques for dense and high-dimensional temporal data streams that are (1) clinically meaningful in terms of fidelity and predictivity, as well as (2) capable of minimizing membership privacy risks in terms of the concrete notion of patient re-identification.
Estimating the Effects of Continuous-valued Interventions using Generative Adversarial Networks
Feb 27, 2020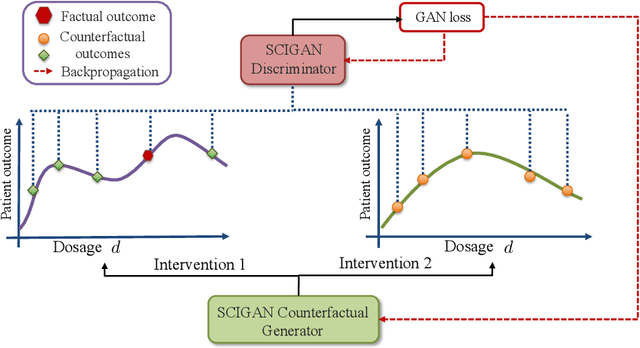
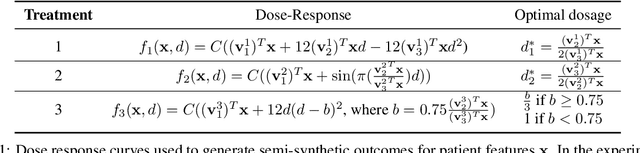
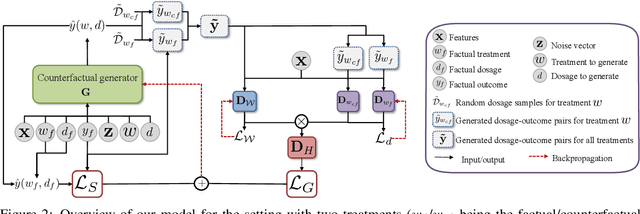
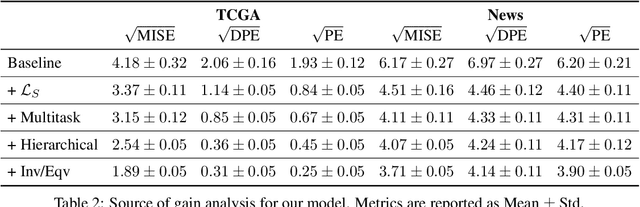
While much attention has been given to the problem of estimating the effect of discrete interventions from observational data, relatively little work has been done in the setting of continuous-valued interventions, such as treatments associated with a dosage parameter. In this paper, we tackle this problem by building on a modification of the generative adversarial networks (GANs) framework. Our model, SCIGAN, is flexible and capable of simultaneously estimating counterfactual outcomes for several different continuous interventions. The key idea is to use a significantly modified GAN model to learn to generate counterfactual outcomes, which can then be used to learn an inference model, using standard supervised methods, capable of estimating these counterfactuals for a new sample. To address the challenges presented by shifting to continuous interventions, we propose a novel architecture for our discriminator - we build a hierarchical discriminator that leverages the structure of the continuous intervention setting. Moreover, we provide theoretical results to support our use of the GAN framework and of the hierarchical discriminator. In the experiments section, we introduce a new semi-synthetic data simulation for use in the continuous intervention setting and demonstrate improvements over the existing benchmark models.
Contextual Constrained Learning for Dose-Finding Clinical Trials
Feb 24, 2020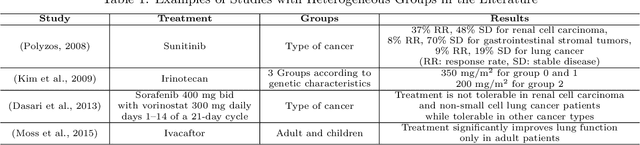

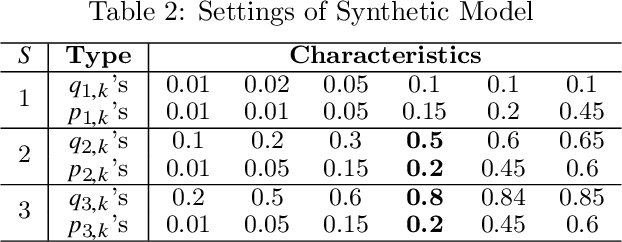
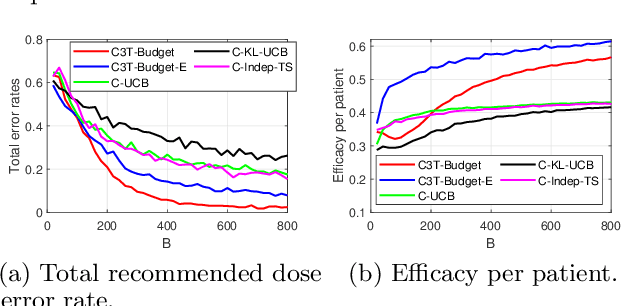
Clinical trials in the medical domain are constrained by budgets. The number of patients that can be recruited is therefore limited. When a patient population is heterogeneous, this creates difficulties in learning subgroup specific responses to a particular drug and especially for a variety of dosages. In addition, patient recruitment can be difficult by the fact that clinical trials do not aim to provide a benefit to any given patient in the trial. In this paper, we propose C3T-Budget, a contextual constrained clinical trial algorithm for dose-finding under both budget and safety constraints. The algorithm aims to maximize drug efficacy within the clinical trial while also learning about the drug being tested. C3T-Budget recruits patients with consideration of the remaining budget, the remaining time, and the characteristics of each group, such as the population distribution, estimated expected efficacy, and estimation credibility. In addition, the algorithm aims to avoid unsafe dosages. These characteristics are further illustrated in a simulated clinical trial study, which corroborates the theoretical analysis and demonstrates an efficient budget usage as well as a balanced learning-treatment trade-off.
Estimating Counterfactual Treatment Outcomes over Time Through Adversarially Balanced Representations
Feb 10, 2020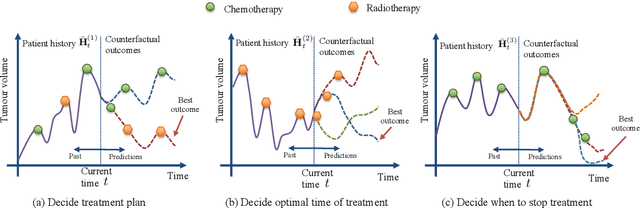
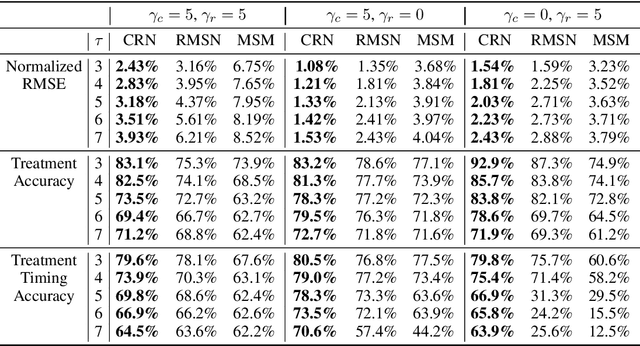
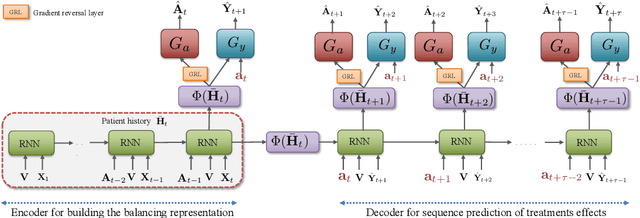

Identifying when to give treatments to patients and how to select among multiple treatments over time are important medical problems with a few existing solutions. In this paper, we introduce the Counterfactual Recurrent Network (CRN), a novel sequence-to-sequence model that leverages the increasingly available patient observational data to estimate treatment effects over time and answer such medical questions. To handle the bias from time-varying confounders, covariates affecting the treatment assignment policy in the observational data, CRN uses domain adversarial training to build balancing representations of the patient history. At each timestep, CRN constructs a treatment invariant representation which removes the association between patient history and treatment assignments and thus can be reliably used for making counterfactual predictions. On a simulated model of tumour growth, with varying degree of time-dependent confounding, we show how our model achieves lower error in estimating counterfactuals and in choosing the correct treatment and timing of treatment than current state-of-the-art methods.
ASAC: Active Sensing using Actor-Critic models
Jun 16, 2019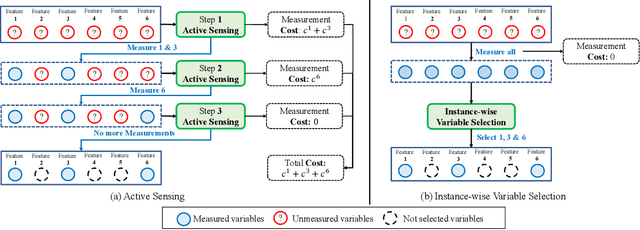

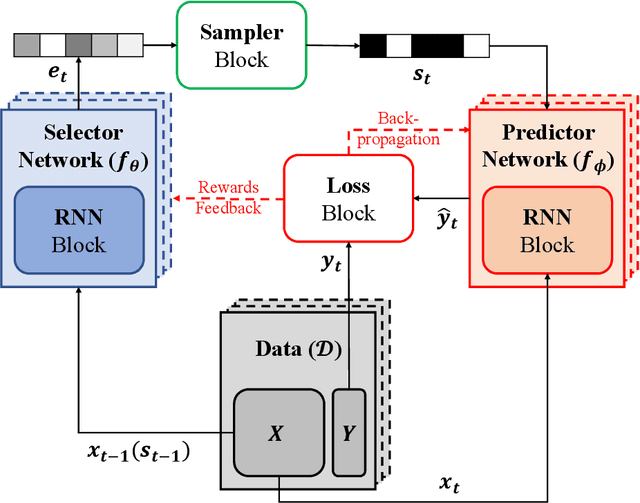

Deciding what and when to observe is critical when making observations is costly. In a medical setting where observations can be made sequentially, making these observations (or not) should be an active choice. We refer to this as the active sensing problem. In this paper, we propose a novel deep learning framework, which we call ASAC (Active Sensing using Actor-Critic models) to address this problem. ASAC consists of two networks: a selector network and a predictor network. The selector network uses previously selected observations to determine what should be observed in the future. The predictor network uses the observations selected by the selector network to predict a label, providing feedback to the selector network (well-selected variables should be predictive of the label). The goal of the selector network is then to select variables that balance the cost of observing the selected variables with their predictive power; we wish to preserve the conditional label distribution. During training, we use the actor-critic models to allow the loss of the selector to be "back-propagated" through the sampling process. The selector network "acts" by selecting future observations to make. The predictor network acts as a "critic" by feeding predictive errors for the selected variables back to the selector network. In our experiments, we show that ASAC significantly outperforms state-of-the-arts in two real-world medical datasets.