 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA-LAMP: Agentic LLM-Based Framework for Automated MDP Modeling and Policy Generation
Dec 12, 2025Applying reinforcement learning (RL) to real-world tasks requires converting informal descriptions into a formal Markov decision process (MDP), implementing an executable environment, and training a policy agent. Automating this process is challenging due to modeling errors, fragile code, and misaligned objectives, which often impede policy training. We introduce an agentic large language model (LLM)-based framework for automated MDP modeling and policy generation (A-LAMP), that automatically translates free-form natural language task descriptions into an MDP formulation and trained policy. The framework decomposes modeling, coding, and training into verifiable stages, ensuring semantic alignment throughout the pipeline. Across both classic control and custom RL domains, A-LAMP consistently achieves higher policy generation capability than a single state-of-the-art LLM model. Notably, even its lightweight variant, which is built on smaller language models, approaches the performance of much larger models. Failure analysis reveals why these improvements occur. In addition, a case study also demonstrates that A-LAMP generates environments and policies that preserve the task's optimality, confirming its correctness and reliability.
Self-Improving Interference Management Based on Deep Learning With Uncertainty Quantification
Jan 24, 2024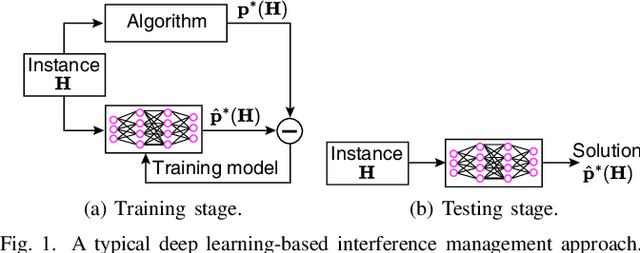
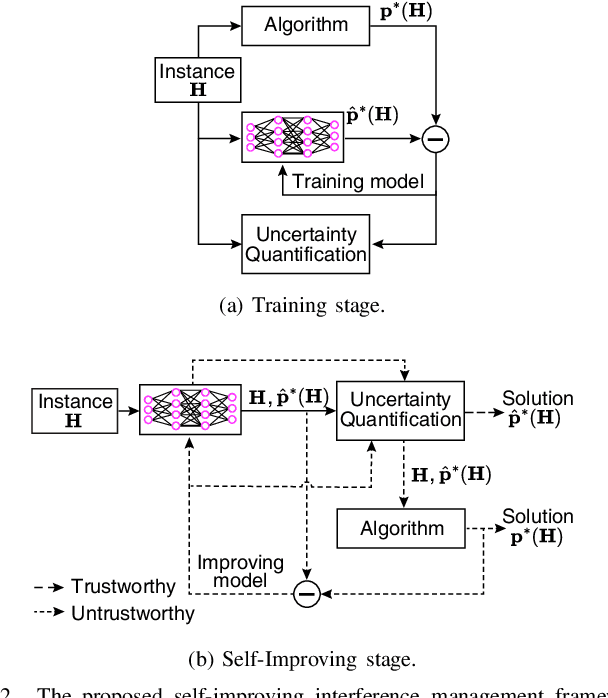
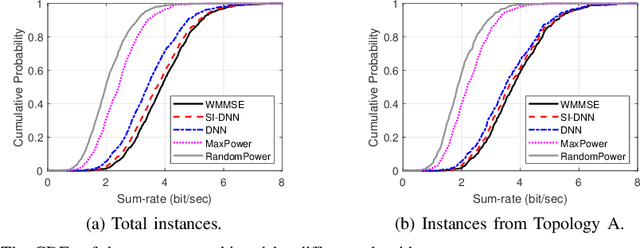
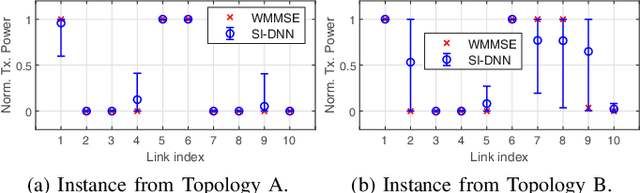
This paper presents a groundbreaking self-improving interference management framework tailored for wireless communications, integrating deep learning with uncertainty quantification to enhance overall system performance. Our approach addresses the computational challenges inherent in traditional optimization-based algorithms by harnessing deep learning models to predict optimal interference management solutions. A significant breakthrough of our framework is its acknowledgment of the limitations inherent in data-driven models, particularly in scenarios not adequately represented by the training dataset. To overcome these challenges, we propose a method for uncertainty quantification, accompanied by a qualifying criterion, to assess the trustworthiness of model predictions. This framework strategically alternates between model-generated solutions and traditional algorithms, guided by a criterion that assesses the prediction credibility based on quantified uncertainties. Experimental results validate the framework's efficacy, demonstrating its superiority over traditional deep learning models, notably in scenarios underrepresented in the training dataset. This work marks a pioneering endeavor in harnessing self-improving deep learning for interference management, through the lens of uncertainty quantification.
Dynamic Joint Scheduling of Anycast Transmission and Modulation in Hybrid Unicast-Multicast SWIPT-Based IoT Sensor Networks
Jul 17, 2023The separate receiver architecture with a time- or power-splitting mode, widely used for simultaneous wireless information and power transfer (SWIPT), has a major drawback: Energy-intensive local oscillators and mixers need to be installed in the information decoding (ID) component to downconvert radio frequency (RF) signals to baseband signals, resulting in high energy consumption. As a solution to this challenge, an integrated receiver (IR) architecture has been proposed, and, in turn, various SWIPT modulation schemes compatible with the IR architecture have been developed. However, to the best of our knowledge, no research has been conducted on modulation scheduling in SWIPT-based IoT sensor networks while taking into account the IR architecture. Accordingly, in this paper, we address this research gap by studying the problem of joint scheduling for unicast/multicast, IoT sensor, and modulation (UMSM) in a time-slotted SWIPT-based IoT sensor network system. To this end, we leverage mathematical modeling and optimization techniques, such as the Lagrangian duality and stochastic optimization theory, to develop an UMSM scheduling algorithm that maximizes the weighted sum of average unicast service throughput and harvested energy of IoT sensors, while ensuring the minimum average throughput of both multicast and unicast, as well as the minimum average harvested energy of IoT sensors. Finally, we demonstrate through extensive simulations that our UMSM scheduling algorithm achieves superior energy harvesting (EH) and throughput performance while ensuring the satisfaction of specified constraints well.
Collaborative Policy Learning for Dynamic Scheduling Tasks in Cloud-Edge-Terminal IoT Networks Using Federated Reinforcement Learning
Jul 02, 2023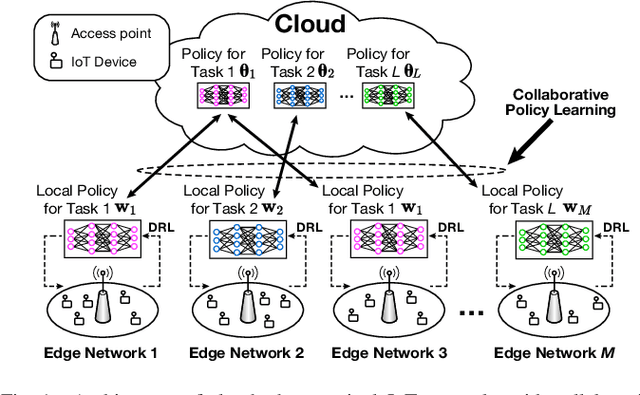
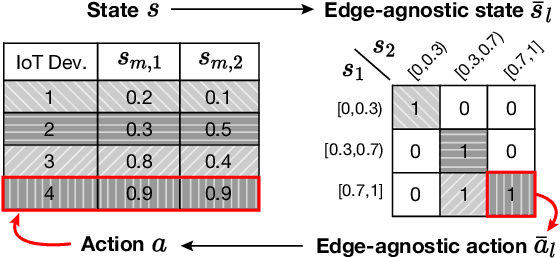
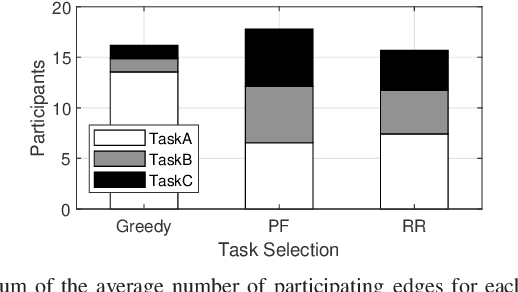
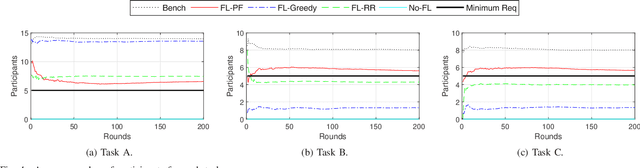
In this paper, we examine cloud-edge-terminal IoT networks, where edges undertake a range of typical dynamic scheduling tasks. In these IoT networks, a central policy for each task can be constructed at a cloud server. The central policy can be then used by the edges conducting the task, thereby mitigating the need for them to learn their own policy from scratch. Furthermore, this central policy can be collaboratively learned at the cloud server by aggregating local experiences from the edges, thanks to the hierarchical architecture of the IoT networks. To this end, we propose a novel collaborative policy learning framework for dynamic scheduling tasks using federated reinforcement learning. For effective learning, our framework adaptively selects the tasks for collaborative learning in each round, taking into account the need for fairness among tasks. In addition, as a key enabler of the framework, we propose an edge-agnostic policy structure that enables the aggregation of local policies from different edges. We then provide the convergence analysis of the framework. Through simulations, we demonstrate that our proposed framework significantly outperforms the approaches without collaborative policy learning. Notably, it accelerates the learning speed of the policies and allows newly arrived edges to adapt to their tasks more easily.
System-Agnostic Meta-Learning for MDP-based Dynamic Scheduling via Descriptive Policy
Jan 25, 2022
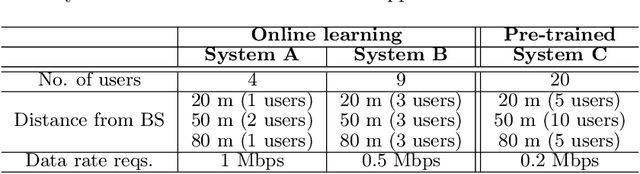
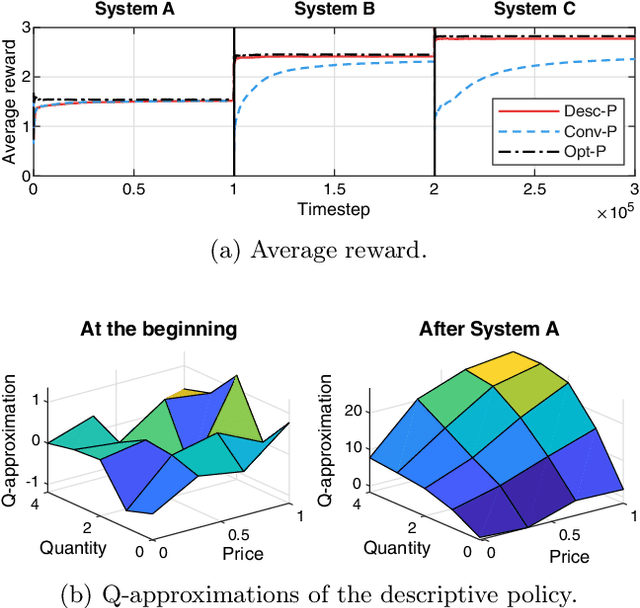
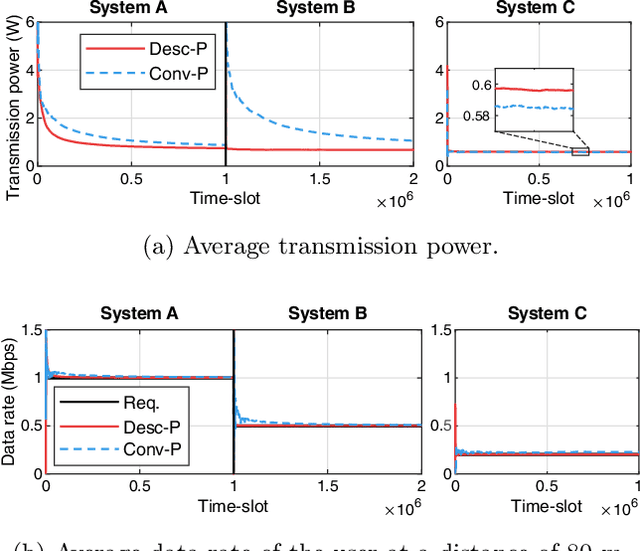
Dynamic scheduling is an important problem in applications from queuing to wireless networks. It addresses how to choose an item among multiple scheduling items in each timestep to achieve a long-term goal. Conventional approaches for dynamic scheduling find the optimal policy for a given specific system so that the policy from these approaches is usable only for the corresponding system characteristics. Hence, it is hard to use such approaches for a practical system in which system characteristics dynamically change. This paper proposes a novel policy structure for MDP-based dynamic scheduling, a descriptive policy, which has a system-agnostic capability to adapt to unseen system characteristics for an identical task (dynamic scheduling). To this end, the descriptive policy learns a system-agnostic scheduling principle--in a nutshell, "which condition of items should have a higher priority in scheduling". The scheduling principle can be applied to any system so that the descriptive policy learned in one system can be used for another system. Experiments with simple explanatory and realistic application scenarios demonstrate that it enables system-agnostic meta-learning with very little performance degradation compared with the system-specific conventional policies.
Adaptive Transmission Scheduling in Wireless Networks for Asynchronous Federated Learning
Mar 02, 2021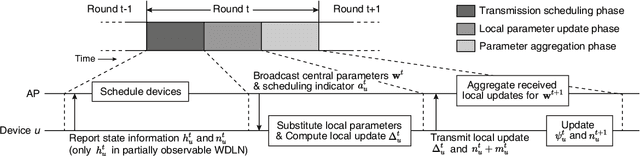
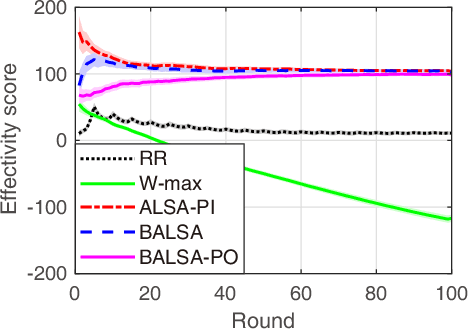
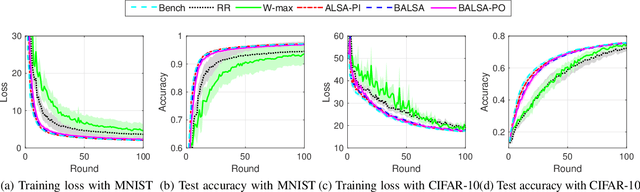
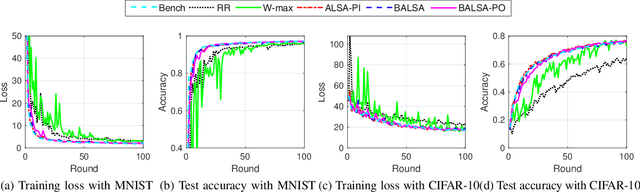
In this paper, we study asynchronous federated learning (FL) in a wireless distributed learning network (WDLN). To allow each edge device to use its local data more efficiently via asynchronous FL, transmission scheduling in the WDLN for asynchronous FL should be carefully determined considering system uncertainties, such as time-varying channel and stochastic data arrivals, and the scarce radio resources in the WDLN. To address this, we propose a metric, called an effectivity score, which represents the amount of learning from asynchronous FL. We then formulate an Asynchronous Learning-aware transmission Scheduling (ALS) problem to maximize the effectivity score and develop three ALS algorithms, called ALSA-PI, BALSA, and BALSA-PO, to solve it. If the statistical information about the uncertainties is known, the problem can be optimally and efficiently solved by ALSA-PI. Even if not, it can be still optimally solved by BALSA that learns the uncertainties based on a Bayesian approach using the state information reported from devices. BALSA-PO suboptimally solves the problem, but it addresses a more restrictive WDLN in practice, where the AP can observe a limited state information compared with the information used in BALSA. We show via simulations that the models trained by our ALS algorithms achieve performances close to that by an ideal benchmark and outperform those by other state-of-the-art baseline scheduling algorithms in terms of model accuracy, training loss, learning speed, and robustness of learning. These results demonstrate that the adaptive scheduling strategy in our ALS algorithms is effective to asynchronous FL.
SDF-Bayes: Cautious Optimism in Safe Dose-Finding Clinical Trials with Drug Combinations and Heterogeneous Patient Groups
Jan 26, 2021
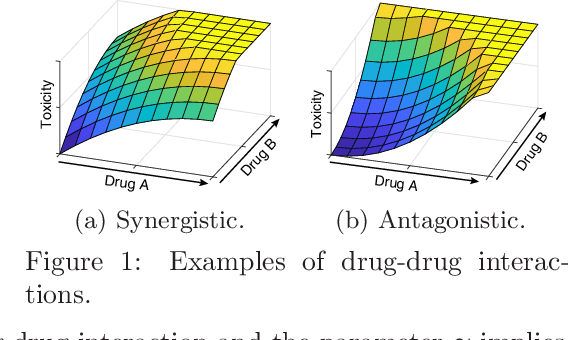


Phase I clinical trials are designed to test the safety (non-toxicity) of drugs and find the maximum tolerated dose (MTD). This task becomes significantly more challenging when multiple-drug dose-combinations (DC) are involved, due to the inherent conflict between the exponentially increasing DC candidates and the limited patient budget. This paper proposes a novel Bayesian design, SDF-Bayes, for finding the MTD for drug combinations in the presence of safety constraints. Rather than the conventional principle of escalating or de-escalating the current dose of one drug (perhaps alternating between drugs), SDF-Bayes proceeds by cautious optimism: it chooses the next DC that, on the basis of current information, is most likely to be the MTD (optimism), subject to the constraint that it only chooses DCs that have a high probability of being safe (caution). We also propose an extension, SDF-Bayes-AR, that accounts for patient heterogeneity and enables heterogeneous patient recruitment. Extensive experiments based on both synthetic and real-world datasets demonstrate the advantages of SDF-Bayes over state of the art DC trial designs in terms of accuracy and safety.
Robust Recursive Partitioning for Heterogeneous Treatment Effects with Uncertainty Quantification
Jun 14, 2020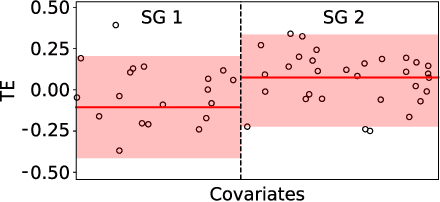

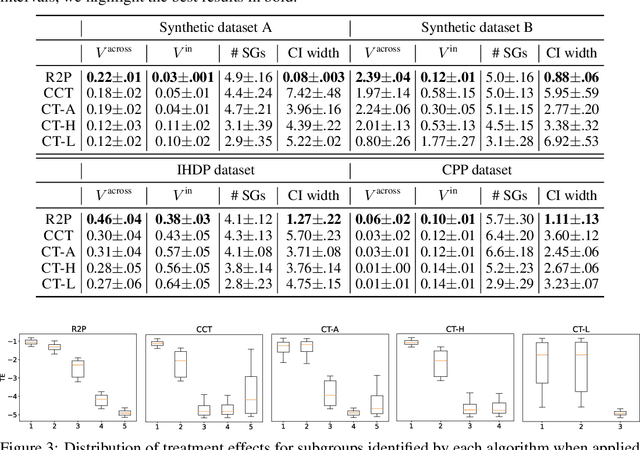
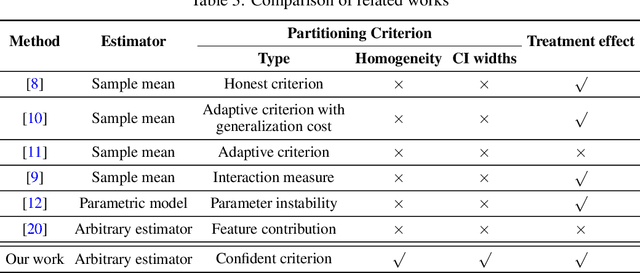
Subgroup analysis of treatment effects plays an important role in applications from medicine to public policy to recommender systems. It allows physicians (for example) to identify groups of patients for whom a given drug or treatment is likely to be effective and groups of patients for which it is not. Most of the current methods of subgroup analysis begin with a particular algorithm for estimating individualized treatment effects (ITE) and identify subgroups by maximizing the difference across subgroups of the average treatment effect in each subgroup. These approaches have several weaknesses: they rely on a particular algorithm for estimating ITE, they ignore (in)homogeneity within identified subgroups, and they do not produce good confidence estimates. This paper develops a new method for subgroup analysis, R2P, that addresses all these weaknesses. R2P uses an arbitrary, exogenously prescribed algorithm for estimating ITE and quantifies the uncertainty of the ITE estimation, using a construction that is more robust than other methods. Experiments using synthetic and semi-synthetic datasets (based on real data) demonstrate that R2P constructs partitions that are simultaneously more homogeneous within groups and more heterogeneous across groups than the partitions produced by other methods. Moreover, because R2P can employ any ITE estimator, it also produces much narrower confidence intervals with a prescribed coverage guarantee than other methods.
Contextual Constrained Learning for Dose-Finding Clinical Trials
Feb 24, 2020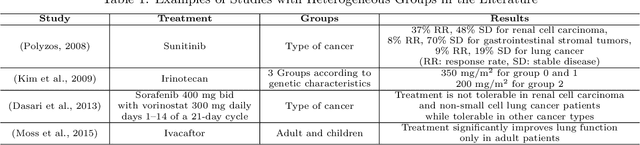

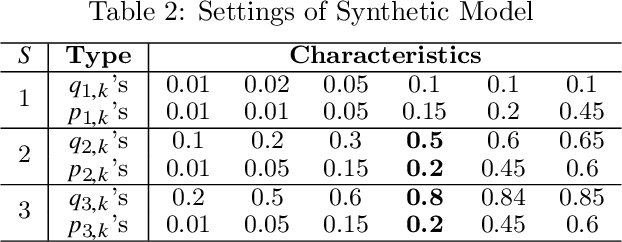
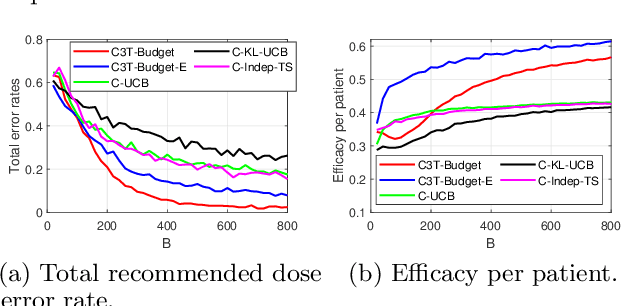
Clinical trials in the medical domain are constrained by budgets. The number of patients that can be recruited is therefore limited. When a patient population is heterogeneous, this creates difficulties in learning subgroup specific responses to a particular drug and especially for a variety of dosages. In addition, patient recruitment can be difficult by the fact that clinical trials do not aim to provide a benefit to any given patient in the trial. In this paper, we propose C3T-Budget, a contextual constrained clinical trial algorithm for dose-finding under both budget and safety constraints. The algorithm aims to maximize drug efficacy within the clinical trial while also learning about the drug being tested. C3T-Budget recruits patients with consideration of the remaining budget, the remaining time, and the characteristics of each group, such as the population distribution, estimated expected efficacy, and estimation credibility. In addition, the algorithm aims to avoid unsafe dosages. These characteristics are further illustrated in a simulated clinical trial study, which corroborates the theoretical analysis and demonstrates an efficient budget usage as well as a balanced learning-treatment trade-off.