 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Density Coding Scheme for SWIPT Systems
Mar 18, 2022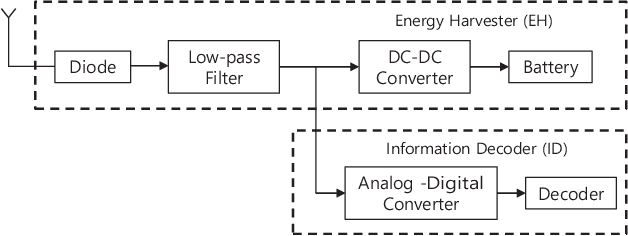
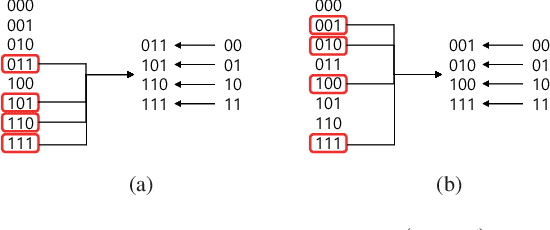
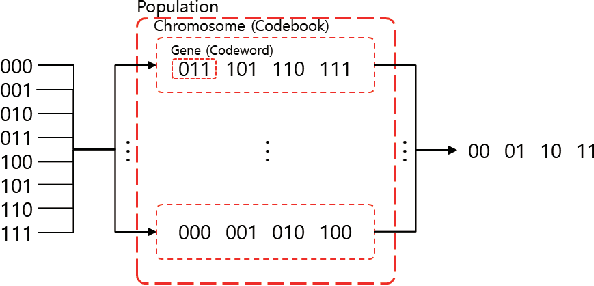
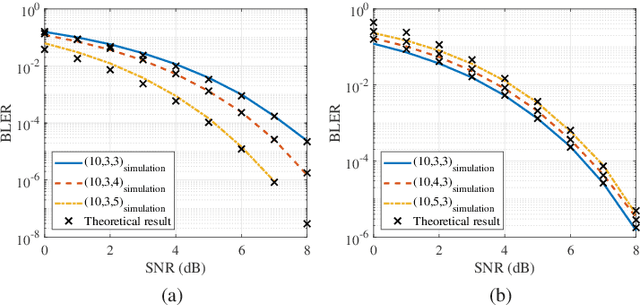
In this study, a novel coding scheme called highdensity coding based on high-density codebooks using a genetic local search algorithm is proposed. The high-density codebook maximizes the energy transfer capability by maximizing the ratio of 1 in the codebook while satisfying the conditions of a codeword with length n, a codebook with 2k codewords, and a minimum Hamming distance of the codebook of d. Furthermore, the proposed high-density codebook provides a trade-off between the throughput and harvested energy with respect to n, k, and d. The block error rate performances of the designed highdensity codebooks are derived theoretically and compared with the simulation results. The simulation results indicate that as d and k decrease, the throughput decreases by a maximum of 10% and 40%, whereas the harvested energy per time increases by a maximum of 40% and 100%, respectively. When n increases, the throughput decreases by a maximum of 30%, while the harvested energy per time increases by a maximum of 110%. With the proposed high-density coding scheme, the throughput and harvested energy at the user can be controlled adaptively according to the system requirements.
Adaptive Transmission Scheduling in Wireless Networks for Asynchronous Federated Learning
Mar 02, 2021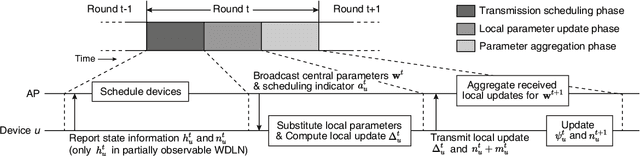
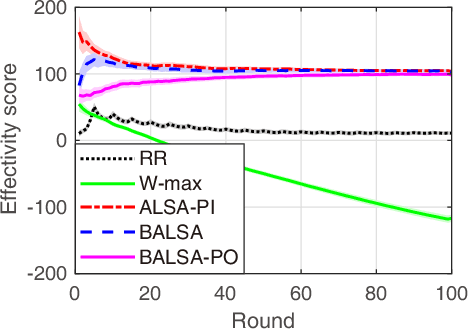
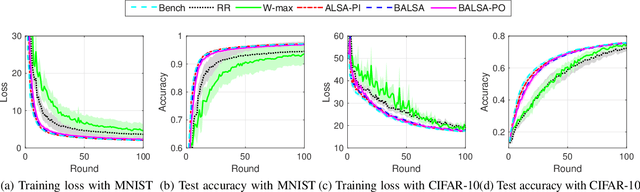
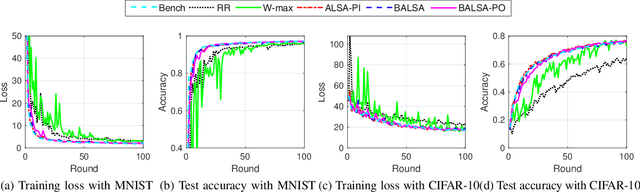
In this paper, we study asynchronous federated learning (FL) in a wireless distributed learning network (WDLN). To allow each edge device to use its local data more efficiently via asynchronous FL, transmission scheduling in the WDLN for asynchronous FL should be carefully determined considering system uncertainties, such as time-varying channel and stochastic data arrivals, and the scarce radio resources in the WDLN. To address this, we propose a metric, called an effectivity score, which represents the amount of learning from asynchronous FL. We then formulate an Asynchronous Learning-aware transmission Scheduling (ALS) problem to maximize the effectivity score and develop three ALS algorithms, called ALSA-PI, BALSA, and BALSA-PO, to solve it. If the statistical information about the uncertainties is known, the problem can be optimally and efficiently solved by ALSA-PI. Even if not, it can be still optimally solved by BALSA that learns the uncertainties based on a Bayesian approach using the state information reported from devices. BALSA-PO suboptimally solves the problem, but it addresses a more restrictive WDLN in practice, where the AP can observe a limited state information compared with the information used in BALSA. We show via simulations that the models trained by our ALS algorithms achieve performances close to that by an ideal benchmark and outperform those by other state-of-the-art baseline scheduling algorithms in terms of model accuracy, training loss, learning speed, and robustness of learning. These results demonstrate that the adaptive scheduling strategy in our ALS algorithms is effective to asynchronous FL.
SDF-Bayes: Cautious Optimism in Safe Dose-Finding Clinical Trials with Drug Combinations and Heterogeneous Patient Groups
Jan 26, 2021
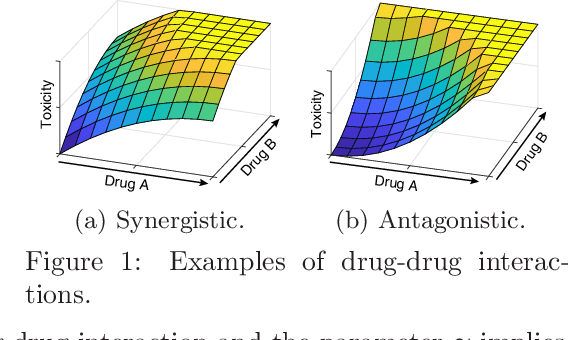


Phase I clinical trials are designed to test the safety (non-toxicity) of drugs and find the maximum tolerated dose (MTD). This task becomes significantly more challenging when multiple-drug dose-combinations (DC) are involved, due to the inherent conflict between the exponentially increasing DC candidates and the limited patient budget. This paper proposes a novel Bayesian design, SDF-Bayes, for finding the MTD for drug combinations in the presence of safety constraints. Rather than the conventional principle of escalating or de-escalating the current dose of one drug (perhaps alternating between drugs), SDF-Bayes proceeds by cautious optimism: it chooses the next DC that, on the basis of current information, is most likely to be the MTD (optimism), subject to the constraint that it only chooses DCs that have a high probability of being safe (caution). We also propose an extension, SDF-Bayes-AR, that accounts for patient heterogeneity and enables heterogeneous patient recruitment. Extensive experiments based on both synthetic and real-world datasets demonstrate the advantages of SDF-Bayes over state of the art DC trial designs in terms of accuracy and safety.
Robust Recursive Partitioning for Heterogeneous Treatment Effects with Uncertainty Quantification
Jun 14, 2020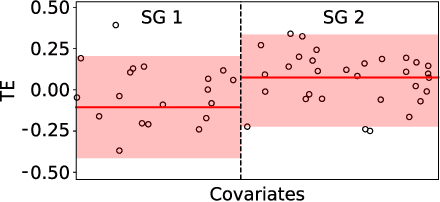

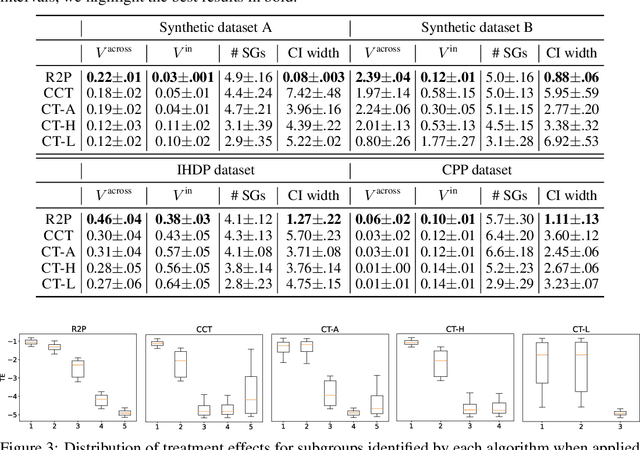
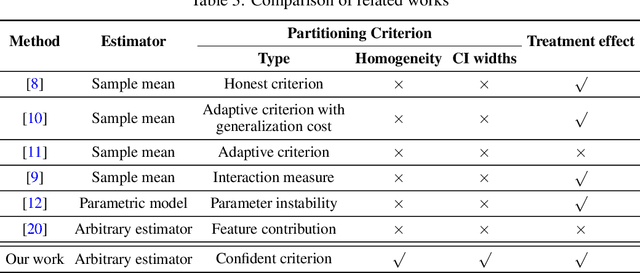
Subgroup analysis of treatment effects plays an important role in applications from medicine to public policy to recommender systems. It allows physicians (for example) to identify groups of patients for whom a given drug or treatment is likely to be effective and groups of patients for which it is not. Most of the current methods of subgroup analysis begin with a particular algorithm for estimating individualized treatment effects (ITE) and identify subgroups by maximizing the difference across subgroups of the average treatment effect in each subgroup. These approaches have several weaknesses: they rely on a particular algorithm for estimating ITE, they ignore (in)homogeneity within identified subgroups, and they do not produce good confidence estimates. This paper develops a new method for subgroup analysis, R2P, that addresses all these weaknesses. R2P uses an arbitrary, exogenously prescribed algorithm for estimating ITE and quantifies the uncertainty of the ITE estimation, using a construction that is more robust than other methods. Experiments using synthetic and semi-synthetic datasets (based on real data) demonstrate that R2P constructs partitions that are simultaneously more homogeneous within groups and more heterogeneous across groups than the partitions produced by other methods. Moreover, because R2P can employ any ITE estimator, it also produces much narrower confidence intervals with a prescribed coverage guarantee than other methods.