 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Capabilities of LLM Encoders for Image-Text Retrieval in Chest X-rays
Sep 17, 2025



Vision-language pretraining has advanced image-text alignment, yet progress in radiology remains constrained by the heterogeneity of clinical reports, including abbreviations, impression-only notes, and stylistic variability. Unlike general-domain settings where more data often leads to better performance, naively scaling to large collections of noisy reports can plateau or even degrade model learning. We ask whether large language model (LLM) encoders can provide robust clinical representations that transfer across diverse styles and better guide image-text alignment. We introduce LLM2VEC4CXR, a domain-adapted LLM encoder for chest X-ray reports, and LLM2CLIP4CXR, a dual-tower framework that couples this encoder with a vision backbone. LLM2VEC4CXR improves clinical text understanding over BERT-based baselines, handles abbreviations and style variation, and achieves strong clinical alignment on report-level metrics. LLM2CLIP4CXR leverages these embeddings to boost retrieval accuracy and clinically oriented scores, with stronger cross-dataset generalization than prior medical CLIP variants. Trained on 1.6M CXR studies from public and private sources with heterogeneous and noisy reports, our models demonstrate that robustness -- not scale alone -- is the key to effective multimodal learning. We release models to support further research in medical image-text representation learning.
Self-Supervised Autoencoder Network for Robust Heart Rate Extraction from Noisy Photoplethysmogram: Applying Blind Source Separation to Biosignal Analysis
Apr 12, 2025Biosignals can be viewed as mixtures measuring particular physiological events, and blind source separation (BSS) aims to extract underlying source signals from mixtures. This paper proposes a self-supervised multi-encoder autoencoder (MEAE) to separate heartbeat-related source signals from photoplethysmogram (PPG), enhancing heart rate (HR) detection in noisy PPG data. The MEAE is trained on PPG signals from a large open polysomnography database without any pre-processing or data selection. The trained network is then applied to a noisy PPG dataset collected during the daily activities of nine subjects. The extracted heartbeat-related source signal significantly improves HR detection as compared to the original PPG. The absence of pre-processing and the self-supervised nature of the proposed method, combined with its strong performance, highlight the potential of BSS in biosignal analysis.
Emulating Self-attention with Convolution for Efficient Image Super-Resolution
Mar 09, 2025In this paper, we tackle the high computational overhead of transformers for lightweight image super-resolution. (SR). Motivated by the observations of self-attention's inter-layer repetition, we introduce a convolutionized self-attention module named Convolutional Attention (ConvAttn) that emulates self-attention's long-range modeling capability and instance-dependent weighting with a single shared large kernel and dynamic kernels. By utilizing the ConvAttn module, we significantly reduce the reliance on self-attention and its involved memory-bound operations while maintaining the representational capability of transformers. Furthermore, we overcome the challenge of integrating flash attention into the lightweight SR regime, effectively mitigating self-attention's inherent memory bottleneck. We scale up window size to 32$\times$32 with flash attention rather than proposing an intricated self-attention module, significantly improving PSNR by 0.31dB on Urban100$\times$2 while reducing latency and memory usage by 16$\times$ and 12.2$\times$. Building on these approaches, our proposed network, termed Emulating Self-attention with Convolution (ESC), notably improves PSNR by 0.27 dB on Urban100$\times$4 compared to HiT-SRF, reducing the latency and memory usage by 3.7$\times$ and 6.2$\times$, respectively. Extensive experiments demonstrate that our ESC maintains the ability for long-range modeling, data scalability, and the representational power of transformers despite most self-attentions being replaced by the ConvAttn module.
SoRA: Singular Value Decomposed Low-Rank Adaptation for Domain Generalizable Representation Learning
Dec 05, 2024



Domain generalization (DG) aims to adapt a model using one or multiple source domains to ensure robust performance in unseen target domains. Recently, Parameter-Efficient Fine-Tuning (PEFT) of foundation models has shown promising results in the context of DG problem. Nevertheless, existing PEFT methods still struggle to strike a balance between preserving generalizable components of the pre-trained model and learning task-specific features. To gain insights into the distribution of generalizable components, we begin by analyzing the pre-trained weights through the lens of singular value decomposition. Building on these insights, we introduce Singular Value Decomposed Low-Rank Adaptation (SoRA), an approach that selectively tunes minor singular components while keeping the residual parts frozen. SoRA effectively retains the generalization ability of the pre-trained model while efficiently acquiring task-specific skills. Furthermore, we freeze domain-generalizable blocks and employ an annealing weight decay strategy, thereby achieving an optimal balance in the delicate trade-off between generalizability and discriminability. SoRA attains state-of-the-art results on multiple benchmarks that span both domain generalized semantic segmentation to domain generalized object detection. In addition, our methods introduce no additional inference overhead or regularization loss, maintain compatibility with any backbone or head, and are designed to be versatile, allowing easy integration into a wide range of tasks.
Implicit Grid Convolution for Multi-Scale Image Super-Resolution
Aug 19, 2024Recently, Super-Resolution (SR) achieved significant performance improvement by employing neural networks. Most SR methods conventionally train a single model for each targeted scale, which increases redundancy in training and deployment in proportion to the number of scales targeted. This paper challenges this conventional fixed-scale approach. Our preliminary analysis reveals that, surprisingly, encoders trained at different scales extract similar features from images. Furthermore, the commonly used scale-specific upsampler, Sub-Pixel Convolution (SPConv), exhibits significant inter-scale correlations. Based on these observations, we propose a framework for training multiple integer scales simultaneously with a single model. We use a single encoder to extract features and introduce a novel upsampler, Implicit Grid Convolution~(IGConv), which integrates SPConv at all scales within a single module to predict multiple scales. Our extensive experiments demonstrate that training multiple scales with a single model reduces the training budget and stored parameters by one-third while achieving equivalent inference latency and comparable performance. Furthermore, we propose IGConv$^{+}$, which addresses spectral bias and input-independent upsampling and uses ensemble prediction to improve performance. As a result, SRFormer-IGConv$^{+}$ achieves a remarkable 0.25dB improvement in PSNR at Urban100$\times$4 while reducing the training budget, stored parameters, and inference cost compared to the existing SRFormer.
MetaMixer Is All You Need
Jun 04, 2024



Transformer, composed of self-attention and Feed-Forward Network, has revolutionized the landscape of network design across various vision tasks. FFN is a versatile operator seamlessly integrated into nearly all AI models to effectively harness rich representations. Recent works also show that FFN functions like key-value memories. Thus, akin to the query-key-value mechanism within self-attention, FFN can be viewed as a memory network, where the input serves as query and the two projection weights operate as keys and values, respectively. We hypothesize that the importance lies in query-key-value framework itself rather than in self-attention. To verify this, we propose converting self-attention into a more FFN-like efficient token mixer with only convolutions while retaining query-key-value framework, namely FFNification. Specifically, FFNification replaces query-key and attention coefficient-value interactions with large kernel convolutions and adopts GELU activation function instead of softmax. The derived token mixer, FFNified attention, serves as key-value memories for detecting locally distributed spatial patterns, and operates in the opposite dimension to the ConvNeXt block within each corresponding sub-operation of the query-key-value framework. Building upon the above two modules, we present a family of Fast-Forward Networks. Our FFNet achieves remarkable performance improvements over previous state-of-the-art methods across a wide range of tasks. The strong and general performance of our proposed method validates our hypothesis and leads us to introduce MetaMixer, a general mixer architecture that does not specify sub-operations within the query-key-value framework. We show that using only simple operations like convolution and GELU in the MetaMixer can achieve superior performance.
Partial Large Kernel CNNs for Efficient Super-Resolution
Apr 18, 2024Recently, in the super-resolution (SR) domain, transformers have outperformed CNNs with fewer FLOPs and fewer parameters since they can deal with long-range dependency and adaptively adjust weights based on instance. In this paper, we demonstrate that CNNs, although less focused on in the current SR domain, surpass Transformers in direct efficiency measures. By incorporating the advantages of Transformers into CNNs, we aim to achieve both computational efficiency and enhanced performance. However, using a large kernel in the SR domain, which mainly processes large images, incurs a large computational overhead. To overcome this, we propose novel approaches to employing the large kernel, which can reduce latency by 86\% compared to the naive large kernel, and leverage an Element-wise Attention module to imitate instance-dependent weights. As a result, we introduce Partial Large Kernel CNNs for Efficient Super-Resolution (PLKSR), which achieves state-of-the-art performance on four datasets at a scale of $\times$4, with reductions of 68.1\% in latency and 80.2\% in maximum GPU memory occupancy compared to SRFormer-light.
Arbitrary-Scale Downscaling of Tidal Current Data Using Implicit Continuous Representation
Jan 31, 2024Numerical models have long been used to understand geoscientific phenomena, including tidal currents, crucial for renewable energy production and coastal engineering. However, their computational cost hinders generating data of varying resolutions. As an alternative, deep learning-based downscaling methods have gained traction due to their faster inference speeds. But most of them are limited to only inference fixed scale and overlook important characteristics of target geoscientific data. In this paper, we propose a novel downscaling framework for tidal current data, addressing its unique characteristics, which are dissimilar to images: heterogeneity and local dependency. Moreover, our framework can generate any arbitrary-scale output utilizing a continuous representation model. Our proposed framework demonstrates significantly improved flow velocity predictions by 93.21% (MSE) and 63.85% (MAE) compared to the Baseline model while achieving a remarkable 33.2% reduction in FLOPs.
DeFTAN-II: Efficient Multichannel Speech Enhancement with Subgroup Processing
Aug 30, 2023



In this work, we present DeFTAN-II, an efficient multichannel speech enhancement model based on transformer architecture and subgroup processing. Despite the success of transformers in speech enhancement, they face challenges in capturing local relations, reducing the high computational complexity, and lowering memory usage. To address these limitations, we introduce subgroup processing in our model, combining subgroups of locally emphasized features with other subgroups containing original features. The subgroup processing is implemented in several blocks of the proposed network. In the proposed split dense blocks extracting spatial features, a pair of subgroups is sequentially concatenated and processed by convolution layers to effectively reduce the computational complexity and memory usage. For the F- and T-transformers extracting temporal and spectral relations, we introduce cross-attention between subgroups to identify relationships between locally emphasized and non-emphasized features. The dual-path feedforward network then aggregates attended features in terms of the gating of local features processed by dilated convolutions. Through extensive comparisons with state-of-the-art multichannel speech enhancement models, we demonstrate that DeFTAN-II with subgroup processing outperforms existing methods at significantly lower computational complexity. Moreover, we evaluate the model's generalization capability on real-world data without fine-tuning, which further demonstrates its effectiveness in practical scenarios.
DeFT-AN: Dense Frequency-Time Attentive Network for Multichannel Speech Enhancement
Dec 15, 2022
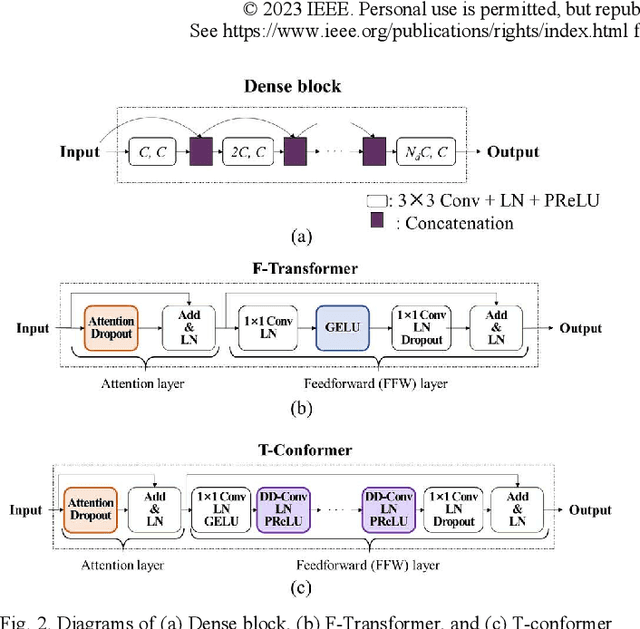


In this study, we propose a dense frequency-time attentive network (DeFT-AN) for multichannel speech enhancement. DeFT-AN is a mask estimation network that predicts a complex spectral masking pattern for suppressing the noise and reverberation embedded in the short-time Fourier transform (STFT) of an input signal. The proposed mask estimation network incorporates three different types of blocks for aggregating information in the spatial, spectral, and temporal dimensions. It utilizes a spectral transformer with a modified feed-forward network and a temporal conformer with sequential dilated convolutions. The use of dense blocks and transformers dedicated to the three different characteristics of audio signals enables more comprehensive denoising and dereverberation. The remarkable performance of DeFT-AN over state-of-the-art multichannel models is demonstrated based on two popular noisy and reverberant datasets in terms of various metrics for speech quality and intelligibility.