 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEMamba++: A General Speech Restoration Framework Leveraging Global, Local, and Periodic Spectral Patterns
Mar 12, 2026General speech restoration demands techniques that can interpret complex speech structures under various distortions. While State-Space Models like SEMamba have advanced the state-of-the-art in speech denoising, they are not inherently optimized for critical speech characteristics, such as spectral periodicity or multi-resolution frequency analysis. In this work, we introduce an architecture tailored to incorporate speech-specific features as inductive biases. In particular, we propose Frequency GLP, a frequency feature extraction block that effectively and efficiently leverages the properties of frequency bins. Then, we design a multi-resolution parallel time-frequency dual-processing block to capture diverse spectral patterns, and a learnable mapping to further enhance model performance. With all our ideas combined, the proposed SEMamba++ achieves the best performance among multiple baseline models while remaining computationally efficient.
RAF: Relativistic Adversarial Feedback For Universal Speech Synthesis
Mar 12, 2026We propose Relativistic Adversarial Feedback (RAF), a novel training objective for GAN vocoders that improves in-domain fidelity and generalization to unseen scenarios. Although modern GAN vocoders employ advanced architectures, their training objectives often fail to promote generalizable representations. RAF addresses this problem by leveraging speech self-supervised learning models to assist discriminators in evaluating sample quality, encouraging the generator to learn richer representations. Furthermore, we utilize relativistic pairing for real and fake waveforms to improve the modeling of the training data distribution. Experiments across multiple datasets show consistent gains in both objective and subjective metrics on GAN-based vocoders. Importantly, the RAF-trained BigVGAN-base outperforms the LSGAN-trained BigVGAN in perceptual quality using only 12\% of the parameters. Comparative studies further confirm the effectiveness of RAF as a training framework for GAN vocoders.
DISPATCH: Distilling Selective Patches for Speech Enhancement
Sep 19, 2025In speech enhancement, knowledge distillation (KD) compresses models by transferring a high-capacity teacher's knowledge to a compact student. However, conventional KD methods train the student to mimic the teacher's output entirely, which forces the student to imitate the regions where the teacher performs poorly and to apply distillation to the regions where the student already performs well, which yields only marginal gains. We propose Distilling Selective Patches (DISPatch), a KD framework for speech enhancement that applies the distillation loss to spectrogram patches where the teacher outperforms the student, as determined by a Knowledge Gap Score. This approach guides optimization toward areas with the most significant potential for student improvement while minimizing the influence of regions where the teacher may provide unreliable instruction. Furthermore, we introduce Multi-Scale Selective Patches (MSSP), a frequency-dependent method that uses different patch sizes across low- and high-frequency bands to account for spectral heterogeneity. We incorporate DISPatch into conventional KD methods and observe consistent gains in compact students. Moreover, integrating DISPatch and MSSP into a state-of-the-art frequency-dependent KD method considerably improves performance across all metrics.
Sound Separation and Classification with Object and Semantic Guidance
Sep 19, 2025The spatial semantic segmentation task focuses on separating and classifying sound objects from multichannel signals. To achieve two different goals, conventional methods fine-tune a large classification model cascaded with the separation model and inject classified labels as separation clues for the next iteration step. However, such integration is not ideal, in that fine-tuning over a smaller dataset loses the diversity of large classification models, features from the source separation model are different from the inputs of the pretrained classifier, and injected one-hot class labels lack semantic depth, often leading to error propagation. To resolve these issues, we propose a Dual-Path Classifier (DPC) architecture that combines object features from a source separation model with semantic representations acquired from a pretrained classification model without fine-tuning. We also introduce a Semantic Clue Encoder (SCE) that enriches the semantic depth of injected clues. Our system achieves a state-of-the-art 11.19 dB CA-SDRi and enhanced semantic fidelity on the DCASE 2025 task4 evaluation set, surpassing the top-rank performance of 11.00 dB. These results highlight the effectiveness of integrating separator-derived features and rich semantic clues.
CST-former: Multidimensional Attention-based Transformer for Sound Event Localization and Detection in Real Scenes
Apr 17, 2025Sound event localization and detection (SELD) is a task for the classification of sound events and the identification of direction of arrival (DoA) utilizing multichannel acoustic signals. For effective classification and localization, a channel-spectro-temporal transformer (CST-former) was suggested. CST-former employs multidimensional attention mechanisms across the spatial, spectral, and temporal domains to enlarge the model's capacity to learn the domain information essential for event detection and DoA estimation over time. In this work, we present an enhanced version of CST-former with multiscale unfolded local embedding (MSULE) developed to capture and aggregate domain information over multiple time-frequency scales. Also, we propose finetuning and post-processing techniques beneficial for conducting the SELD task over limited training datasets. In-depth ablation studies of the proposed architecture and detailed analysis on the proposed modules are carried out to validate the efficacy of multidimensional attentions on the SELD task. Empirical validation through experimentation on STARSS22 and STARSS23 datasets demonstrates the remarkable performance of CST-former and post-processing techniques without using external data.
3D Room Geometry Inference from Multichannel Room Impulse Response using Deep Neural Network
Jan 19, 2024Room geometry inference (RGI) aims at estimating room shapes from measured room impulse responses (RIRs) and has received lots of attention for its importance in environment-aware audio rendering and virtual acoustic representation of a real venue. A lot of estimation models utilizing time difference of arrival (TDoA) or time of arrival (ToA) information in RIRs have been proposed. However, an estimation model should be able to handle more general features and complex relations between reflections to cope with various room shapes and uncertainties such as the unknown number of walls. In this study, we propose a deep neural network that can estimate various room shapes without prior assumptions on the shape or number of walls. The proposed model consists of three sub-networks: a feature extractor, parameter estimation, and evaluation networks, which extract key features from RIRs, estimate parameters, and evaluate the confidence of estimated parameters, respectively. The network is trained by about 40,000 RIRs simulated in rooms of different shapes using a single source and spherical microphone array and tested for rooms of unseen shapes and dimensions. The proposed algorithm achieves almost perfect accuracy in finding the true number of walls and shows negligible errors in room shapes.
* 5 pages, 2 figures, Proceedings of the 24th International Congress on Acoustics
CST-former: Transformer with Channel-Spectro-Temporal Attention for Sound Event Localization and Detection
Dec 20, 2023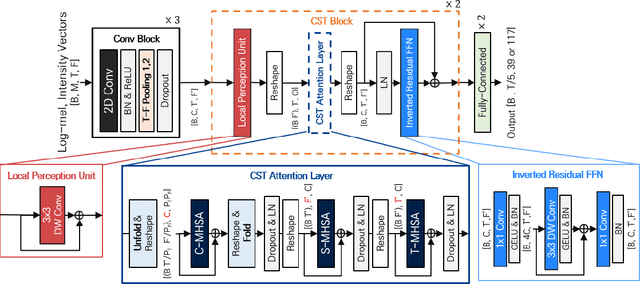
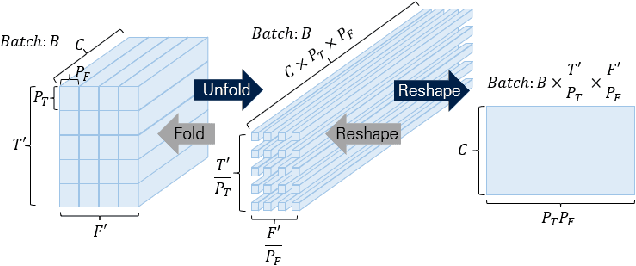
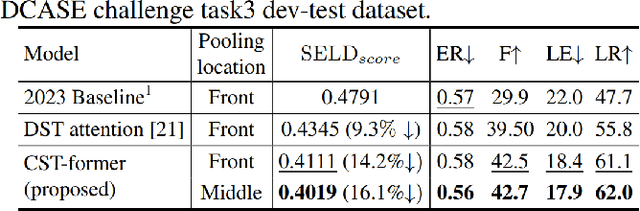
Sound event localization and detection (SELD) is a task for the classification of sound events and the localization of direction of arrival (DoA) utilizing multichannel acoustic signals. Prior studies employ spectral and channel information as the embedding for temporal attention. However, this usage limits the deep neural network from extracting meaningful features from the spectral or spatial domains. Therefore, our investigation in this paper presents a novel framework termed the Channel-Spectro-Temporal Transformer (CST-former) that bolsters SELD performance through the independent application of attention mechanisms to distinct domains. The CST-former architecture employs distinct attention mechanisms to independently process channel, spectral, and temporal information. In addition, we propose an unfolded local embedding (ULE) technique for channel attention (CA) to generate informative embedding vectors including local spectral and temporal information. Empirical validation through experimentation on the 2022 and 2023 DCASE Challenge task3 datasets affirms the efficacy of employing attention mechanisms separated across each domain and the benefit of ULE, in enhancing SELD performance.
EchoScan: Scanning Complex Indoor Geometries via Acoustic Echoes
Oct 18, 2023



Accurate estimation of indoor space geometries is vital for constructing precise digital twins, whose broad industrial applications include navigation in unfamiliar environments and efficient evacuation planning, particularly in low-light conditions. This study introduces EchoScan, a deep neural network model that utilizes acoustic echoes to perform room geometry inference. Conventional sound-based techniques rely on estimating geometry-related room parameters such as wall position and room size, thereby limiting the diversity of inferable room geometries. Contrarily, EchoScan overcomes this limitation by directly inferring room floorplans and heights, thereby enabling it to handle rooms with arbitrary shapes, including curved walls. The key innovation of EchoScan is its ability to analyze the complex relationship between low- and high-order reflections in room impulse responses (RIRs) using a multi-aggregation module. The analysis of high-order reflections also enables it to infer complex room shapes when echoes are unobservable from the position of an audio device. Herein, EchoScan was trained and evaluated using RIRs synthesized from complex environments, including the Manhattan and Atlanta layouts, employing a practical audio device configuration compatible with commercial, off-the-shelf devices. Compared with vision-based methods, EchoScan demonstrated outstanding geometry estimation performance in rooms with various shapes.
Noisy-ArcMix: Additive Noisy Angular Margin Loss Combined With Mixup Anomalous Sound Detection
Oct 10, 2023Unsupervised anomalous sound detection (ASD) aims to identify anomalous sounds by learning the features of normal operational sounds and sensing their deviations. Recent approaches have focused on the self-supervised task utilizing the classification of normal data, and advanced models have shown that securing representation space for anomalous data is important through representation learning yielding compact intra-class and well-separated intra-class distributions. However, we show that conventional approaches often fail to ensure sufficient intra-class compactness and exhibit angular disparity between samples and their corresponding centers. In this paper, we propose a training technique aimed at ensuring intra-class compactness and increasing the angle gap between normal and abnormal samples. Furthermore, we present an architecture that extracts features for important temporal regions, enabling the model to learn which time frames should be emphasized or suppressed. Experimental results demonstrate that the proposed method achieves the best performance giving 0.90%, 0.83%, and 2.16% improvement in terms of AUC, pAUC, and mAUC, respectively, compared to the state-of-the-art method on DCASE 2020 Challenge Task2 dataset.
RGI-Net: 3D Room Geometry Inference from Room Impulse Responses in the Absence of First-order Echoes
Sep 04, 2023



Room geometry is important prior information for implementing realistic 3D audio rendering. For this reason, various room geometry inference (RGI) methods have been developed by utilizing the time of arrival (TOA) or time difference of arrival (TDOA) information in room impulse responses. However, the conventional RGI technique poses several assumptions, such as convex room shapes, the number of walls known in priori, and the visibility of first-order reflections. In this work, we introduce the deep neural network (DNN), RGI-Net, which can estimate room geometries without the aforementioned assumptions. RGI-Net learns and exploits complex relationships between high-order reflections in room impulse responses (RIRs) and, thus, can estimate room shapes even when the shape is non-convex or first-order reflections are missing in the RIRs. The network takes RIRs measured from a compact audio device equipped with a circular microphone array and a single loudspeaker, which greatly improves its practical applicability. RGI-Net includes the evaluation network that separately evaluates the presence probability of walls, so the geometry inference is possible without prior knowledge of the number of walls.