 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCST-former: Multidimensional Attention-based Transformer for Sound Event Localization and Detection in Real Scenes
Apr 17, 2025Sound event localization and detection (SELD) is a task for the classification of sound events and the identification of direction of arrival (DoA) utilizing multichannel acoustic signals. For effective classification and localization, a channel-spectro-temporal transformer (CST-former) was suggested. CST-former employs multidimensional attention mechanisms across the spatial, spectral, and temporal domains to enlarge the model's capacity to learn the domain information essential for event detection and DoA estimation over time. In this work, we present an enhanced version of CST-former with multiscale unfolded local embedding (MSULE) developed to capture and aggregate domain information over multiple time-frequency scales. Also, we propose finetuning and post-processing techniques beneficial for conducting the SELD task over limited training datasets. In-depth ablation studies of the proposed architecture and detailed analysis on the proposed modules are carried out to validate the efficacy of multidimensional attentions on the SELD task. Empirical validation through experimentation on STARSS22 and STARSS23 datasets demonstrates the remarkable performance of CST-former and post-processing techniques without using external data.
CST-former: Transformer with Channel-Spectro-Temporal Attention for Sound Event Localization and Detection
Dec 20, 2023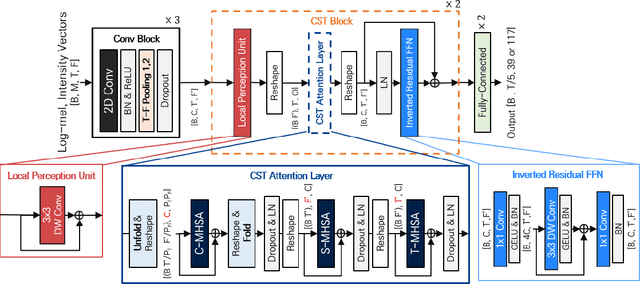
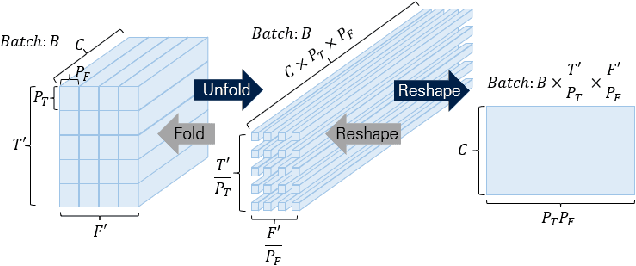
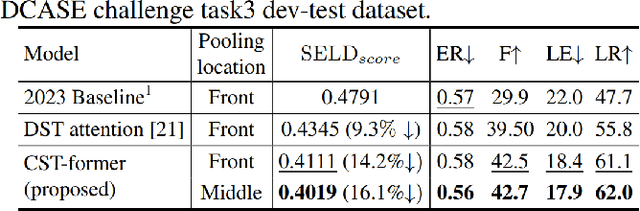
Sound event localization and detection (SELD) is a task for the classification of sound events and the localization of direction of arrival (DoA) utilizing multichannel acoustic signals. Prior studies employ spectral and channel information as the embedding for temporal attention. However, this usage limits the deep neural network from extracting meaningful features from the spectral or spatial domains. Therefore, our investigation in this paper presents a novel framework termed the Channel-Spectro-Temporal Transformer (CST-former) that bolsters SELD performance through the independent application of attention mechanisms to distinct domains. The CST-former architecture employs distinct attention mechanisms to independently process channel, spectral, and temporal information. In addition, we propose an unfolded local embedding (ULE) technique for channel attention (CA) to generate informative embedding vectors including local spectral and temporal information. Empirical validation through experimentation on the 2022 and 2023 DCASE Challenge task3 datasets affirms the efficacy of employing attention mechanisms separated across each domain and the benefit of ULE, in enhancing SELD performance.
Divided spectro-temporal attention for sound event localization and detection in real scenes for DCASE2023 challenge
Jun 05, 2023
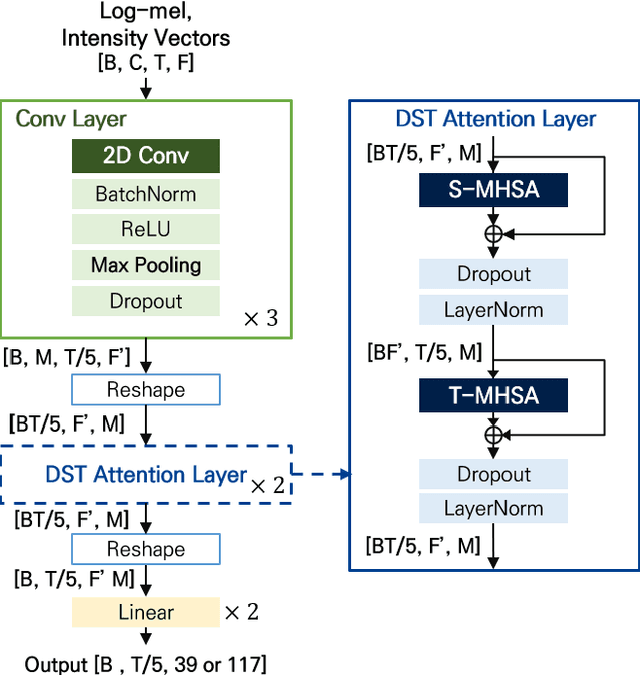


Localizing sounds and detecting events in different room environments is a difficult task, mainly due to the wide range of reflections and reverberations. When training neural network models with sounds recorded in only a few room environments, there is a tendency for the models to become overly specialized to those specific environments, resulting in overfitting. To address this overfitting issue, we propose divided spectro-temporal attention. In comparison to the baseline method, which utilizes a convolutional recurrent neural network (CRNN) followed by a temporal multi-head self-attention layer (MHSA), we introduce a separate spectral attention layer that aggregates spectral features prior to the temporal MHSA. To achieve efficient spectral attention, we reduce the frequency pooling size in the convolutional encoder of the baseline to obtain a 3D tensor that incorporates information about frequency, time, and channel. As a result, we can implement spectral attention with channel embeddings, which is not possible in the baseline method dealing with only temporal context in the RNN and MHSA layers. We demonstrate that the proposed divided spectro-temporal attention significantly improves the performance of sound event detection and localization scores for real test data from the STARSS23 development dataset. Additionally, we show that various data augmentations, such as frameshift, time masking, channel swapping, and moderate mix-up, along with the use of external data, contribute to the overall improvement in SELD performance.