 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning machines for health and beyond
Mar 02, 2023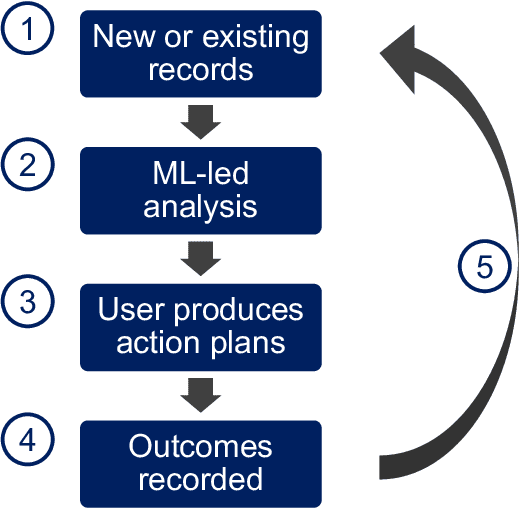

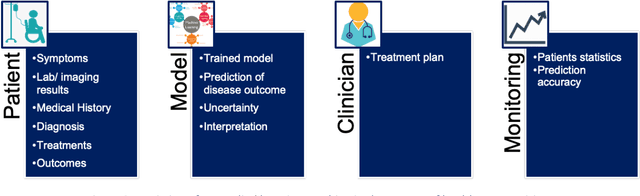
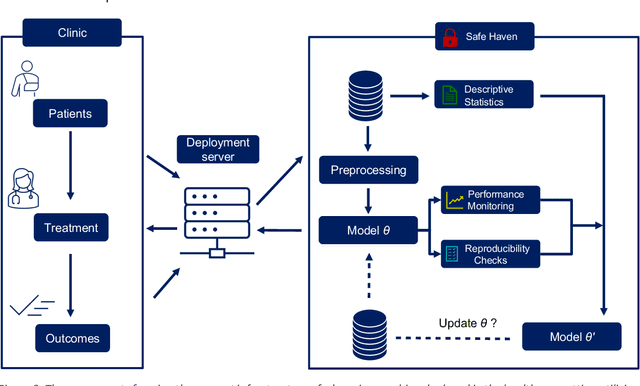
Machine learning techniques are effective for building predictive models because they are good at identifying patterns in large datasets. Development of a model for complex real life problems often stops at the point of publication, proof of concept or when made accessible through some mode of deployment. However, a model in the medical domain risks becoming obsolete as soon as patient demographic changes. The maintenance and monitoring of predictive models post-publication is crucial to guarantee their safe and effective long term use. As machine learning techniques are effectively trained to look for patterns in available datasets, the performance of a model for complex real life problems will not peak and remain fixed at the point of publication or even point of deployment. Rather, data changes over time, and they also changed when models are transported to new places to be used by new demography.
Synthetic Data: Opening the data floodgates to enable faster, more directed development of machine learning methods
Dec 08, 2020Many ground-breaking advancements in machine learning can be attributed to the availability of a large volume of rich data. Unfortunately, many large-scale datasets are highly sensitive, such as healthcare data, and are not widely available to the machine learning community. Generating synthetic data with privacy guarantees provides one such solution, allowing meaningful research to be carried out "at scale" - by allowing the entirety of the machine learning community to potentially accelerate progress within a given field. In this article, we provide a high-level view of synthetic data: what it means, how we might evaluate it and how we might use it.