 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning machines for health and beyond
Mar 02, 2023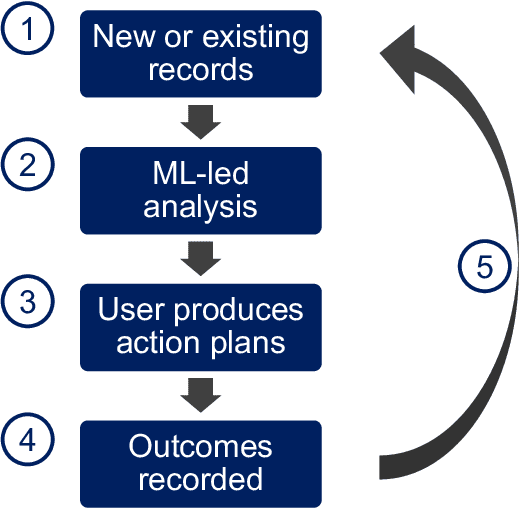

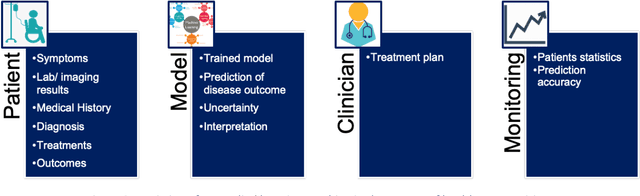
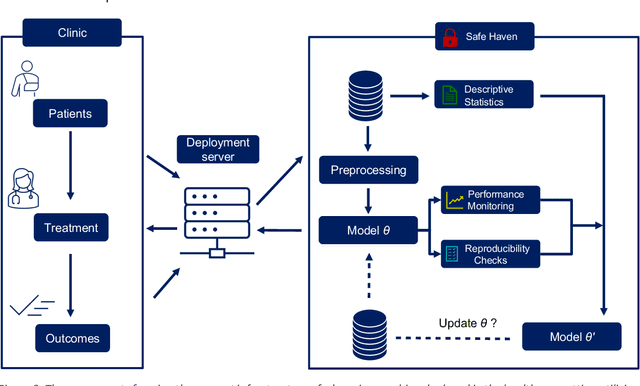
Machine learning techniques are effective for building predictive models because they are good at identifying patterns in large datasets. Development of a model for complex real life problems often stops at the point of publication, proof of concept or when made accessible through some mode of deployment. However, a model in the medical domain risks becoming obsolete as soon as patient demographic changes. The maintenance and monitoring of predictive models post-publication is crucial to guarantee their safe and effective long term use. As machine learning techniques are effectively trained to look for patterns in available datasets, the performance of a model for complex real life problems will not peak and remain fixed at the point of publication or even point of deployment. Rather, data changes over time, and they also changed when models are transported to new places to be used by new demography.
Faking feature importance: A cautionary tale on the use of differentially-private synthetic data
Mar 02, 2022
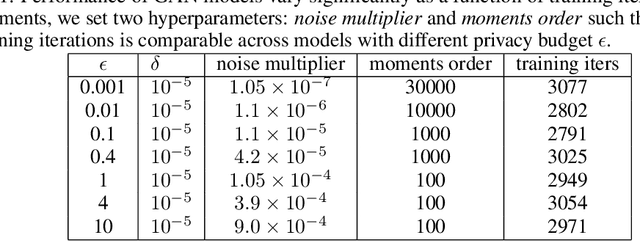

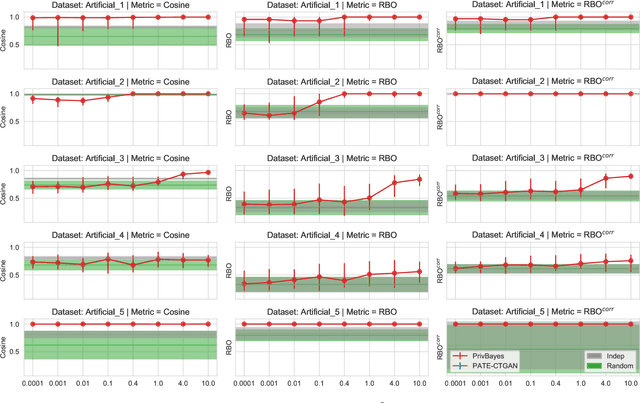
Synthetic datasets are often presented as a silver-bullet solution to the problem of privacy-preserving data publishing. However, for many applications, synthetic data has been shown to have limited utility when used to train predictive models. One promising potential application of these data is in the exploratory phase of the machine learning workflow, which involves understanding, engineering and selecting features. This phase often involves considerable time, and depends on the availability of data. There would be substantial value in synthetic data that permitted these steps to be carried out while, for example, data access was being negotiated, or with fewer information governance restrictions. This paper presents an empirical analysis of the agreement between the feature importance obtained from raw and from synthetic data, on a range of artificially generated and real-world datasets (where feature importance represents how useful each feature is when predicting a the outcome). We employ two differentially-private methods to produce synthetic data, and apply various utility measures to quantify the agreement in feature importance as this varies with the level of privacy. Our results indicate that synthetic data can sometimes preserve several representations of the ranking of feature importance in simple settings but their performance is not consistent and depends upon a number of factors. Particular caution should be exercised in more nuanced real-world settings, where synthetic data can lead to differences in ranked feature importance that could alter key modelling decisions. This work has important implications for developing synthetic versions of highly sensitive data sets in fields such as finance and healthcare.
An Expectation-Based Network Scan Statistic for a COVID-19 Early Warning System
Dec 08, 2020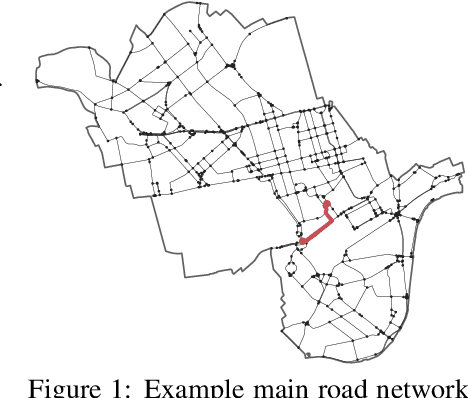
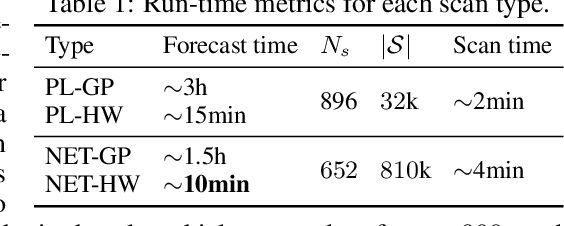
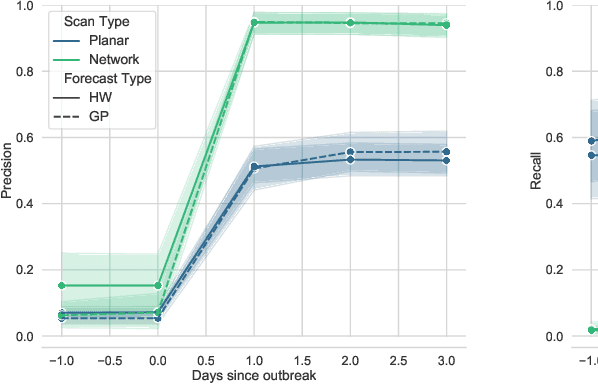
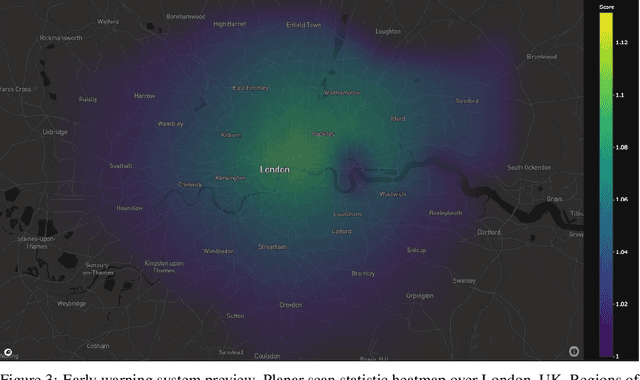
One of the Greater London Authority's (GLA) response to the COVID-19 pandemic brings together multiple large-scale and heterogeneous datasets capturing mobility, transportation and traffic activity over the city of London to better understand 'busyness' and enable targeted interventions and effective policy-making. As part of Project Odysseus we describe an early-warning system and introduce an expectation-based scan statistic for networks to help the GLA and Transport for London, understand the extent to which populations are following government COVID-19 guidelines. We explicitly treat the case of geographically fixed time-series data located on a (road) network and primarily focus on monitoring the dynamics across large regions of the capital. Additionally, we also focus on the detection and reporting of significant spatio-temporal regions. Our approach is extending the Network Based Scan Statistic (NBSS) by making it expectation-based (EBP) and by using stochastic processes for time-series forecasting, which enables us to quantify metric uncertainty in both the EBP and NBSS frameworks. We introduce a variant of the metric used in the EBP model which focuses on identifying space-time regions in which activity is quieter than expected.
Near Real-Time Social Distancing in London
Dec 07, 2020
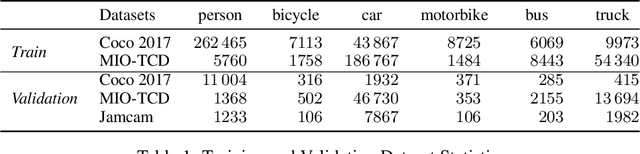
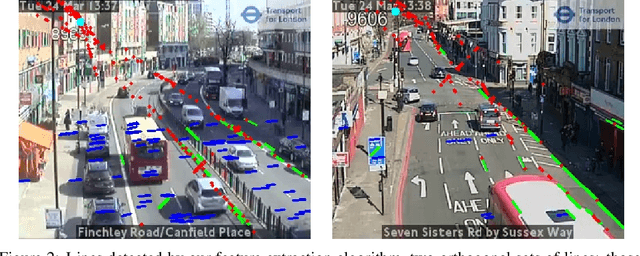
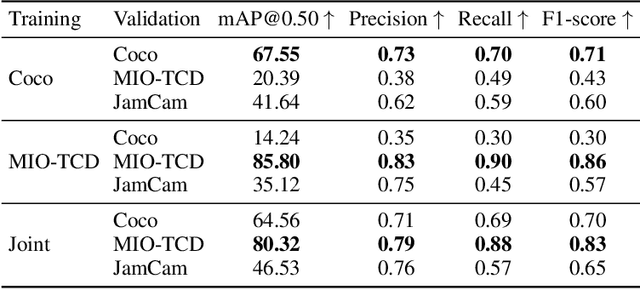
During the COVID-19 pandemic, policy makers at the Greater London Authority, the regional governance body of London, UK, are reliant upon prompt and accurate data sources. Large well-defined heterogeneous compositions of activity throughout the city are sometimes difficult to acquire, yet are a necessity in order to learn 'busyness' and consequently make safe policy decisions. One component of our project within this space is to utilise existing infrastructure to estimate social distancing adherence by the general public. Our method enables near immediate sampling and contextualisation of activity and physical distancing on the streets of London via live traffic camera feeds. We introduce a framework for inspecting and improving upon existing methods, whilst also describing its active deployment on over 900 real-time feeds.