 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePERC: a suite of software tools for the curation of cryoEM data with application to simulation, modelling and machine learning
Mar 17, 2025Ease of access to data, tools and models expedites scientific research. In structural biology there are now numerous open repositories of experimental and simulated datasets. Being able to easily access and utilise these is crucial for allowing researchers to make optimal use of their research effort. The tools presented here are useful for collating existing public cryoEM datasets and/or creating new synthetic cryoEM datasets to aid the development of novel data processing and interpretation algorithms. In recent years, structural biology has seen the development of a multitude of machine-learning based algorithms for aiding numerous steps in the processing and reconstruction of experimental datasets and the use of these approaches has become widespread. Developing such techniques in structural biology requires access to large datasets which can be cumbersome to curate and unwieldy to make use of. In this paper we present a suite of Python software packages which we collectively refer to as PERC (profet, EMPIARreader and CAKED). These are designed to reduce the burden which data curation places upon structural biology research. The protein structure fetcher (profet) package allows users to conveniently download and cleave sequences or structures from the Protein Data Bank or Alphafold databases. EMPIARreader allows lazy loading of Electron Microscopy Public Image Archive datasets in a machine-learning compatible structure. The Class Aggregator for Key Electron-microscopy Data (CAKED) package is designed to seamlessly facilitate the training of machine learning models on electron microscopy data, including electron-cryo-microscopy-specific data augmentation and labelling. These packages may be utilised independently or as building blocks in workflows. All are available in open source repositories and designed to be easily extensible to facilitate more advanced workflows if required.
Faking feature importance: A cautionary tale on the use of differentially-private synthetic data
Mar 02, 2022
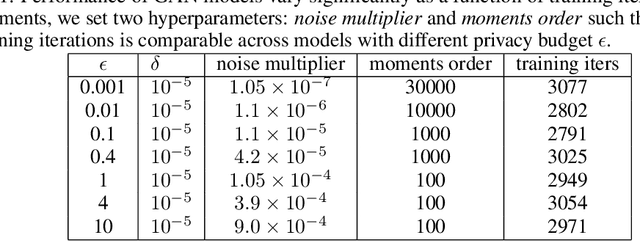

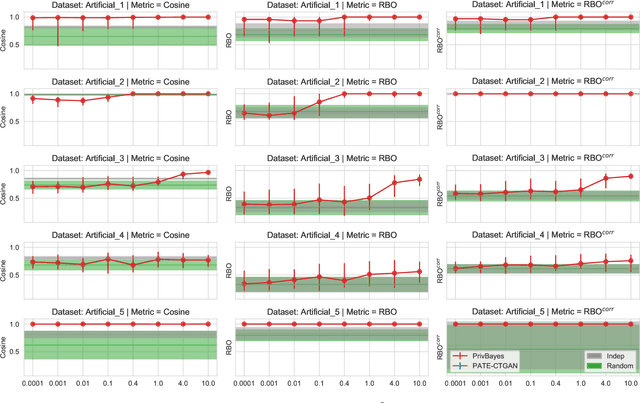
Synthetic datasets are often presented as a silver-bullet solution to the problem of privacy-preserving data publishing. However, for many applications, synthetic data has been shown to have limited utility when used to train predictive models. One promising potential application of these data is in the exploratory phase of the machine learning workflow, which involves understanding, engineering and selecting features. This phase often involves considerable time, and depends on the availability of data. There would be substantial value in synthetic data that permitted these steps to be carried out while, for example, data access was being negotiated, or with fewer information governance restrictions. This paper presents an empirical analysis of the agreement between the feature importance obtained from raw and from synthetic data, on a range of artificially generated and real-world datasets (where feature importance represents how useful each feature is when predicting a the outcome). We employ two differentially-private methods to produce synthetic data, and apply various utility measures to quantify the agreement in feature importance as this varies with the level of privacy. Our results indicate that synthetic data can sometimes preserve several representations of the ranking of feature importance in simple settings but their performance is not consistent and depends upon a number of factors. Particular caution should be exercised in more nuanced real-world settings, where synthetic data can lead to differences in ranked feature importance that could alter key modelling decisions. This work has important implications for developing synthetic versions of highly sensitive data sets in fields such as finance and healthcare.