 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Optical Flow Computation: A Higher-Order Differential Approach
Oct 12, 2024In the domain of computer vision, optical flow stands as a cornerstone for unraveling dynamic visual scenes. However, the challenge of accurately estimating optical flow under conditions of large nonlinear motion patterns remains an open question. The image flow constraint is vulnerable to substantial displacements, and rapid spatial transformations. Inaccurate approximations inherent in numerical differentiation techniques can further amplify such intricacies. In response, this research proposes an innovative algorithm for optical flow computation, utilizing the higher precision of second-order Taylor series approximation within the differential estimation framework. By embracing this mathematical underpinning, the research seeks to extract more information about the behavior of the function under complex real-world scenarios and estimate the motion of areas with a lack of texture. An impressive showcase of the algorithm's capabilities emerges through its performance on renowned optical flow benchmarks such as KITTI (2015) and Middlebury. The average endpoint error (AEE), which computes the Euclidian distance between the calculated flow field and the ground truth flow field, stands notably diminished, validating the effectiveness of the algorithm in handling complex motion patterns.
Preventing Eviction-Caused Homelessness through ML-Informed Distribution of Rental Assistance
Mar 19, 2024



Rental assistance programs provide individuals with financial assistance to prevent housing instabilities caused by evictions and avert homelessness. Since these programs operate under resource constraints, they must decide who to prioritize. Typically, funding is distributed by a reactive or first-come-first serve allocation process that does not systematically consider risk of future homelessness. We partnered with Allegheny County, PA to explore a proactive allocation approach that prioritizes individuals facing eviction based on their risk of future homelessness. Our ML system that uses state and county administrative data to accurately identify individuals in need of support outperforms simpler prioritization approaches by at least 20% while being fair and equitable across race and gender. Furthermore, our approach would identify 28% of individuals who are overlooked by the current process and end up homeless. Beyond improvements to the rental assistance program in Allegheny County, this study can inform the development of evidence-based decision support tools in similar contexts, including lessons about data needs, model design, evaluation, and field validation.
On the Importance of Application-Grounded Experimental Design for Evaluating Explainable ML Methods
Jun 30, 2022

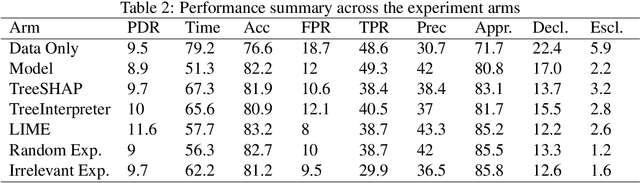
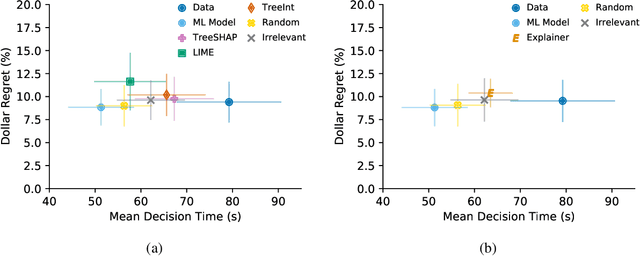
Machine Learning (ML) models now inform a wide range of human decisions, but using ``black box'' models carries risks such as relying on spurious correlations or errant data. To address this, researchers have proposed methods for supplementing models with explanations of their predictions. However, robust evaluations of these methods' usefulness in real-world contexts have remained elusive, with experiments tending to rely on simplified settings or proxy tasks. We present an experimental study extending a prior explainable ML evaluation experiment and bringing the setup closer to the deployment setting by relaxing its simplifying assumptions. Our empirical study draws dramatically different conclusions than the prior work, highlighting how seemingly trivial experimental design choices can yield misleading results. Beyond the present experiment, we believe this work holds lessons about the necessity of situating the evaluation of any ML method and choosing appropriate tasks, data, users, and metrics to match the intended deployment contexts.
Faking feature importance: A cautionary tale on the use of differentially-private synthetic data
Mar 02, 2022
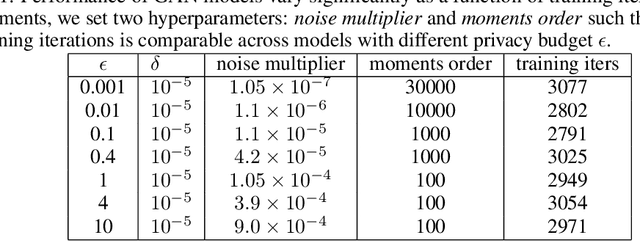

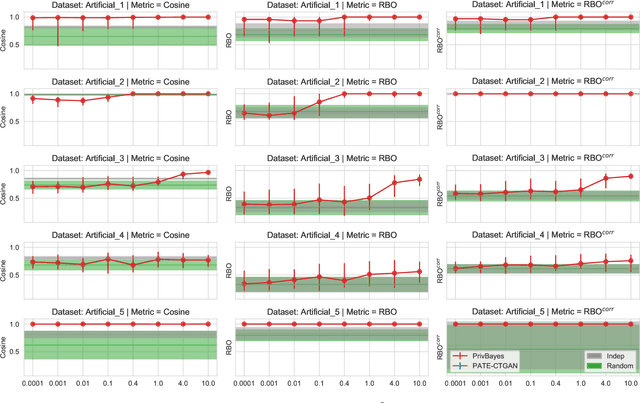
Synthetic datasets are often presented as a silver-bullet solution to the problem of privacy-preserving data publishing. However, for many applications, synthetic data has been shown to have limited utility when used to train predictive models. One promising potential application of these data is in the exploratory phase of the machine learning workflow, which involves understanding, engineering and selecting features. This phase often involves considerable time, and depends on the availability of data. There would be substantial value in synthetic data that permitted these steps to be carried out while, for example, data access was being negotiated, or with fewer information governance restrictions. This paper presents an empirical analysis of the agreement between the feature importance obtained from raw and from synthetic data, on a range of artificially generated and real-world datasets (where feature importance represents how useful each feature is when predicting a the outcome). We employ two differentially-private methods to produce synthetic data, and apply various utility measures to quantify the agreement in feature importance as this varies with the level of privacy. Our results indicate that synthetic data can sometimes preserve several representations of the ranking of feature importance in simple settings but their performance is not consistent and depends upon a number of factors. Particular caution should be exercised in more nuanced real-world settings, where synthetic data can lead to differences in ranked feature importance that could alter key modelling decisions. This work has important implications for developing synthetic versions of highly sensitive data sets in fields such as finance and healthcare.
Explainable Machine Learning for Public Policy: Use Cases, Gaps, and Research Directions
Oct 27, 2020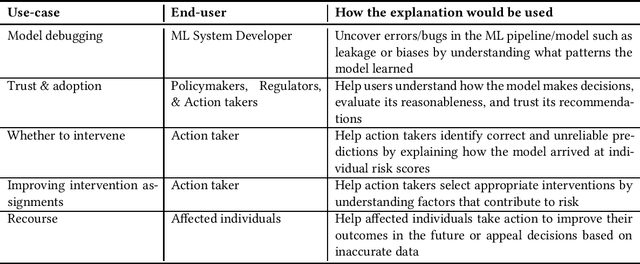
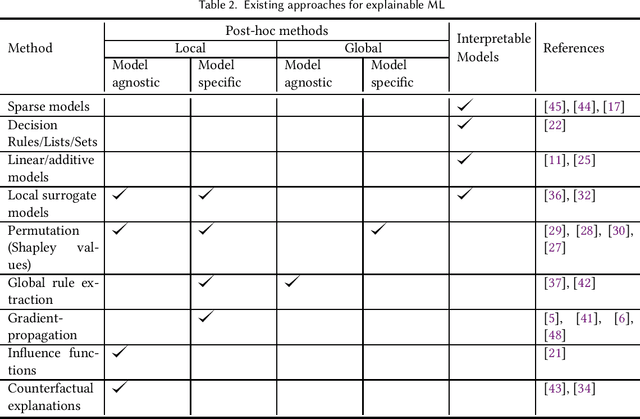
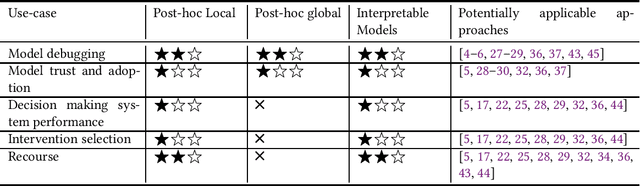
In Machine Learning (ML) models used for supporting decisions in high-stakes domains such as public policy, explainability is crucial for adoption and effectiveness. While the field of explainable ML has expanded in recent years, much of this work does not take real-world needs into account. A majority of proposed methods use benchmark ML problems with generic explainability goals without clear use-cases or intended end-users. As a result, the effectiveness of this large body of theoretical and methodological work on real-world applications is unclear. This paper focuses on filling this void for the domain of public policy. We develop a taxonomy of explainability use-cases within public policy problems; for each use-case, we define the end-users of explanations and the specific goals explainability has to fulfill; third, we map existing work to these use-cases, identify gaps, and propose research directions to fill those gaps in order to have practical policy impact through ML.
Building Energy Load Forecasting using Deep Neural Networks
Oct 29, 2016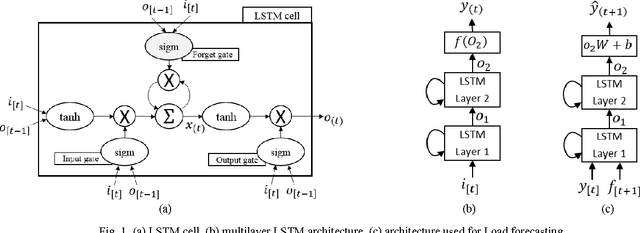
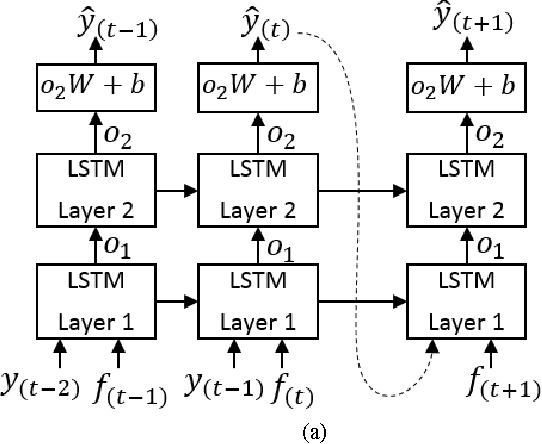
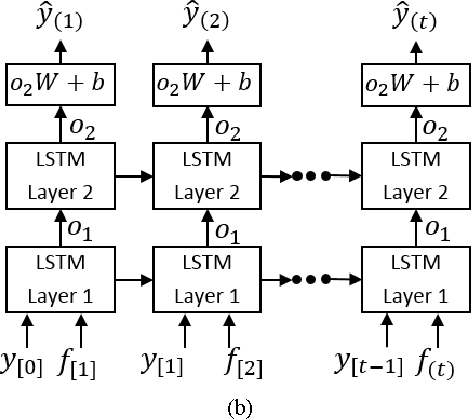
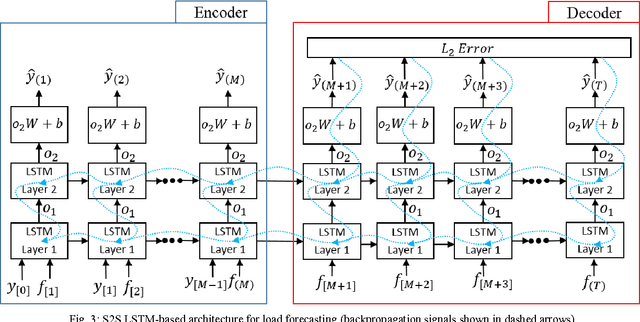
Ensuring sustainability demands more efficient energy management with minimized energy wastage. Therefore, the power grid of the future should provide an unprecedented level of flexibility in energy management. To that end, intelligent decision making requires accurate predictions of future energy demand/load, both at aggregate and individual site level. Thus, energy load forecasting have received increased attention in the recent past, however has proven to be a difficult problem. This paper presents a novel energy load forecasting methodology based on Deep Neural Networks, specifically Long Short Term Memory (LSTM) algorithms. The presented work investigates two variants of the LSTM: 1) standard LSTM and 2) LSTM-based Sequence to Sequence (S2S) architecture. Both methods were implemented on a benchmark data set of electricity consumption data from one residential customer. Both architectures where trained and tested on one hour and one-minute time-step resolution datasets. Experimental results showed that the standard LSTM failed at one-minute resolution data while performing well in one-hour resolution data. It was shown that S2S architecture performed well on both datasets. Further, it was shown that the presented methods produced comparable results with the other deep learning methods for energy forecasting in literature.