 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking the Cycle of Incarceration With Targeted Mental Health Outreach: A Case Study in Machine Learning for Public Policy
Sep 17, 2025Many incarcerated individuals face significant and complex challenges, including mental illness, substance dependence, and homelessness, yet jails and prisons are often poorly equipped to address these needs. With little support from the existing criminal justice system, these needs can remain untreated and worsen, often leading to further offenses and a cycle of incarceration with adverse outcomes both for the individual and for public safety, with particularly large impacts on communities of color that continue to widen the already extensive racial disparities in criminal justice outcomes. Responding to these failures, a growing number of criminal justice stakeholders are seeking to break this cycle through innovative approaches such as community-driven and alternative approaches to policing, mentoring, community building, restorative justice, pretrial diversion, holistic defense, and social service connections. Here we report on a collaboration between Johnson County, Kansas, and Carnegie Mellon University to perform targeted, proactive mental health outreach in an effort to reduce reincarceration rates. This paper describes the data used, our predictive modeling approach and results, as well as the design and analysis of a field trial conducted to confirm our model's predictive power, evaluate the impact of this targeted outreach, and understand at what level of reincarceration risk outreach might be most effective. Through this trial, we find that our model is highly predictive of new jail bookings, with more than half of individuals in the trial's highest-risk group returning to jail in the following year. Outreach was most effective among these highest-risk individuals, with impacts on mental health utilization, EMS dispatches, and criminal justice involvement.
Locating and measuring marine aquaculture production from space: a computer vision approach in the French Mediterranean
Jun 19, 2024



Aquaculture production -- the cultivation of aquatic plants and animals -- has grown rapidly since the 1990s, but sparse, self-reported and aggregate production data limits the effective understanding and monitoring of the industry's trends and potential risks. Building on a manual survey of aquaculture production from remote sensing imagery, we train a computer vision model to identify marine aquaculture cages from aerial and satellite imagery, and generate a spatially explicit dataset of finfish production locations in the French Mediterranean from 2000-2021 that includes 4,010 cages (69m2 average cage area). We demonstrate the value of our method as an easily adaptable, cost-effective approach that can improve the speed and reliability of aquaculture surveys, and enables downstream analyses relevant to researchers and regulators. We illustrate its use to compute independent estimates of production, and develop a flexible framework to quantify uncertainty in these estimates. Overall, our study presents an efficient, scalable and highly adaptable method for monitoring aquaculture production from remote sensing imagery.
Toward Operationalizing Pipeline-aware ML Fairness: A Research Agenda for Developing Practical Guidelines and Tools
Sep 29, 2023



While algorithmic fairness is a thriving area of research, in practice, mitigating issues of bias often gets reduced to enforcing an arbitrarily chosen fairness metric, either by enforcing fairness constraints during the optimization step, post-processing model outputs, or by manipulating the training data. Recent work has called on the ML community to take a more holistic approach to tackle fairness issues by systematically investigating the many design choices made through the ML pipeline, and identifying interventions that target the issue's root cause, as opposed to its symptoms. While we share the conviction that this pipeline-based approach is the most appropriate for combating algorithmic unfairness on the ground, we believe there are currently very few methods of \emph{operationalizing} this approach in practice. Drawing on our experience as educators and practitioners, we first demonstrate that without clear guidelines and toolkits, even individuals with specialized ML knowledge find it challenging to hypothesize how various design choices influence model behavior. We then consult the fair-ML literature to understand the progress to date toward operationalizing the pipeline-aware approach: we systematically collect and organize the prior work that attempts to detect, measure, and mitigate various sources of unfairness through the ML pipeline. We utilize this extensive categorization of previous contributions to sketch a research agenda for the community. We hope this work serves as the stepping stone toward a more comprehensive set of resources for ML researchers, practitioners, and students interested in exploring, designing, and testing pipeline-oriented approaches to algorithmic fairness.
A Conceptual Framework for Using Machine Learning to Support Child Welfare Decisions
Jul 12, 2022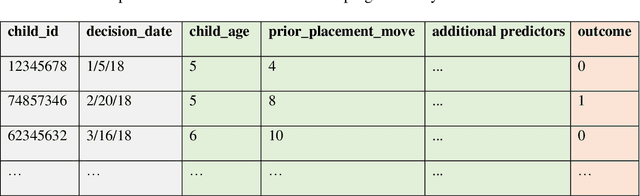
Human services systems make key decisions that impact individuals in the society. The U.S. child welfare system makes such decisions, from screening-in hotline reports of suspected abuse or neglect for child protective investigations, placing children in foster care, to returning children to permanent home settings. These complex and impactful decisions on children's lives rely on the judgment of child welfare decisionmakers. Child welfare agencies have been exploring ways to support these decisions with empirical, data-informed methods that include machine learning (ML). This paper describes a conceptual framework for ML to support child welfare decisions. The ML framework guides how child welfare agencies might conceptualize a target problem that ML can solve; vet available administrative data for building ML; formulate and develop ML specifications that mirror relevant populations and interventions the agencies are undertaking; deploy, evaluate, and monitor ML as child welfare context, policy, and practice change over time. Ethical considerations, stakeholder engagement, and avoidance of common pitfalls underpin the framework's impact and success. From abstract to concrete, we describe one application of this framework to support a child welfare decision. This ML framework, though child welfare-focused, is generalizable to solving other public policy problems.
On the Importance of Application-Grounded Experimental Design for Evaluating Explainable ML Methods
Jun 30, 2022

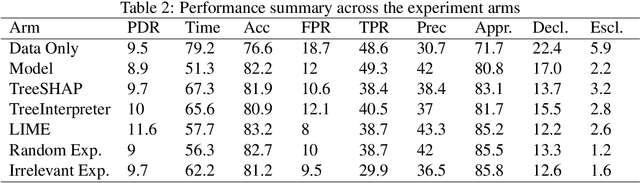
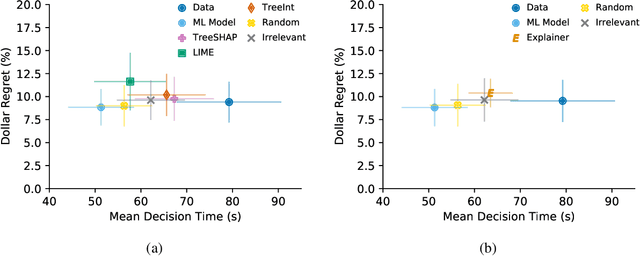
Machine Learning (ML) models now inform a wide range of human decisions, but using ``black box'' models carries risks such as relying on spurious correlations or errant data. To address this, researchers have proposed methods for supplementing models with explanations of their predictions. However, robust evaluations of these methods' usefulness in real-world contexts have remained elusive, with experiments tending to rely on simplified settings or proxy tasks. We present an experimental study extending a prior explainable ML evaluation experiment and bringing the setup closer to the deployment setting by relaxing its simplifying assumptions. Our empirical study draws dramatically different conclusions than the prior work, highlighting how seemingly trivial experimental design choices can yield misleading results. Beyond the present experiment, we believe this work holds lessons about the necessity of situating the evaluation of any ML method and choosing appropriate tasks, data, users, and metrics to match the intended deployment contexts.
An Empirical Comparison of Bias Reduction Methods on Real-World Problems in High-Stakes Policy Settings
May 13, 2021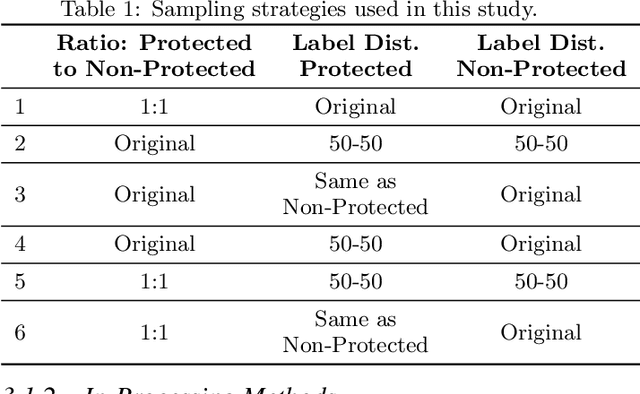
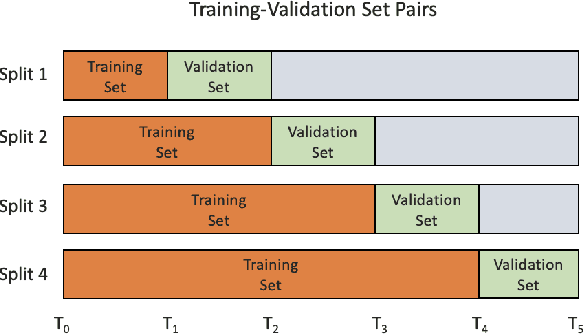
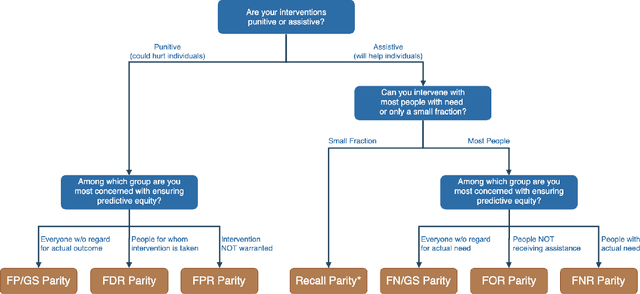
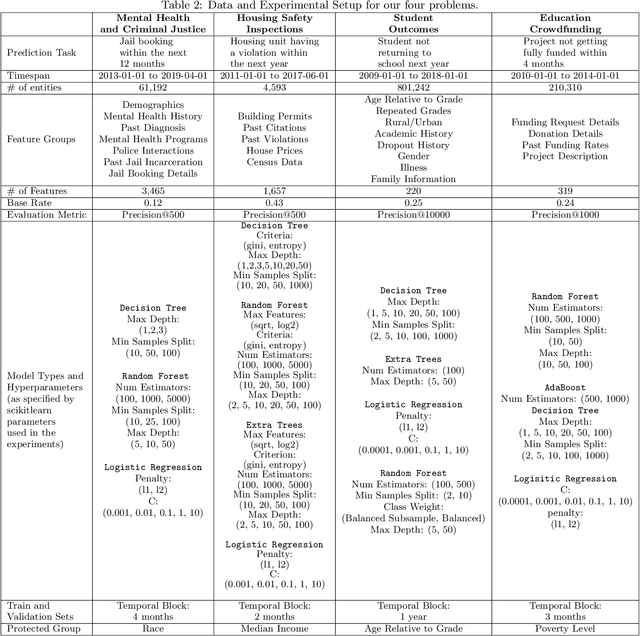
Applications of machine learning (ML) to high-stakes policy settings -- such as education, criminal justice, healthcare, and social service delivery -- have grown rapidly in recent years, sparking important conversations about how to ensure fair outcomes from these systems. The machine learning research community has responded to this challenge with a wide array of proposed fairness-enhancing strategies for ML models, but despite the large number of methods that have been developed, little empirical work exists evaluating these methods in real-world settings. Here, we seek to fill this research gap by investigating the performance of several methods that operate at different points in the ML pipeline across four real-world public policy and social good problems. Across these problems, we find a wide degree of variability and inconsistency in the ability of many of these methods to improve model fairness, but post-processing by choosing group-specific score thresholds consistently removes disparities, with important implications for both the ML research community and practitioners deploying machine learning to inform consequential policy decisions.
Machine learning for public policy: Do we need to sacrifice accuracy to make models fair?
Dec 05, 2020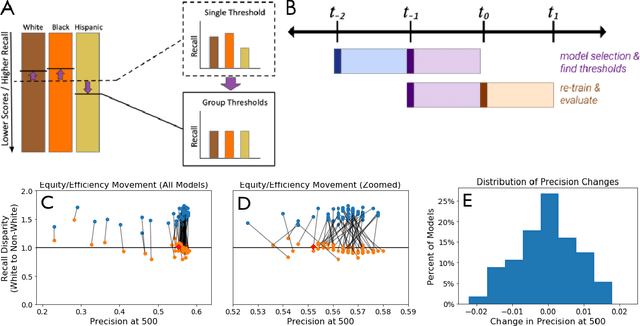
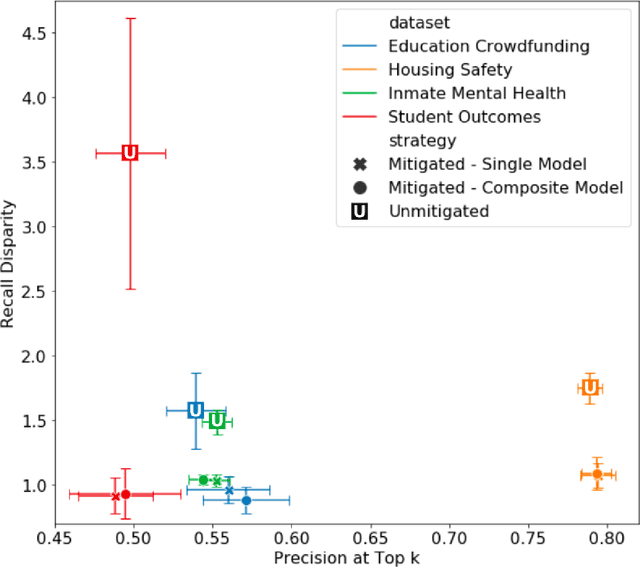
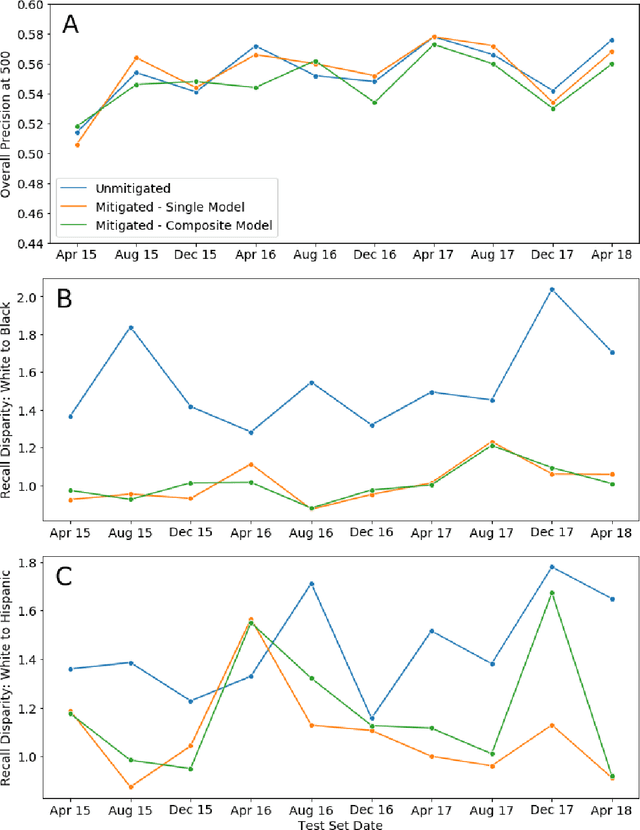
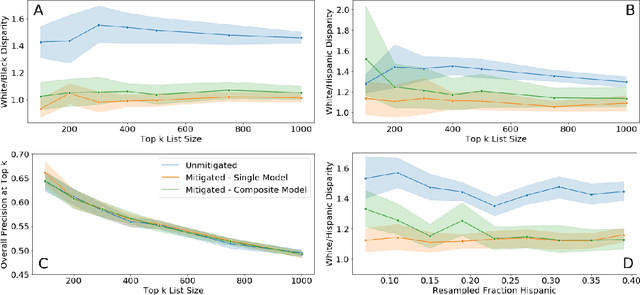
Growing applications of machine learning in policy settings have raised concern for fairness implications, especially for racial minorities, but little work has studied the practical trade-offs between fairness and accuracy in real-world settings. This empirical study fills this gap by investigating the accuracy cost of mitigating disparities across several policy settings, focusing on the common context of using machine learning to inform benefit allocation in resource-constrained programs across education, mental health, criminal justice, and housing safety. In each setting, explicitly focusing on achieving equity and using our proposed post-hoc disparity mitigation methods, fairness was substantially improved without sacrificing accuracy, challenging the commonly held assumption that reducing disparities either requires accepting an appreciable drop in accuracy or the development of novel, complex methods.
Case Study: Predictive Fairness to Reduce Misdemeanor Recidivism Through Social Service Interventions
Jan 24, 2020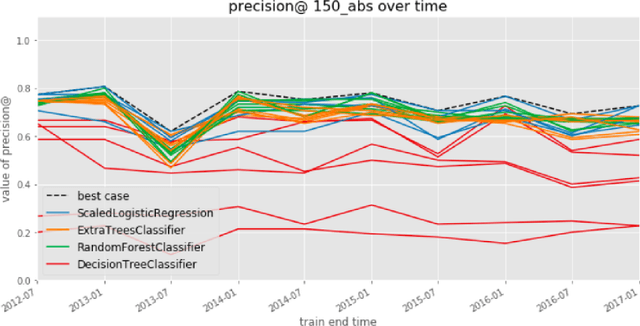
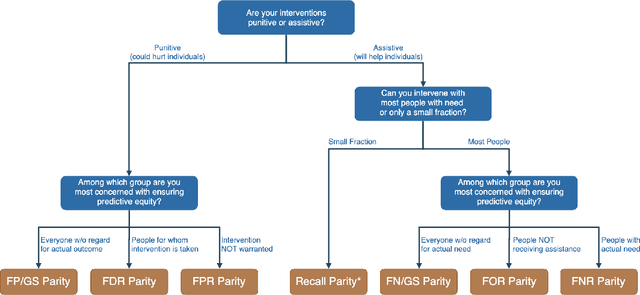
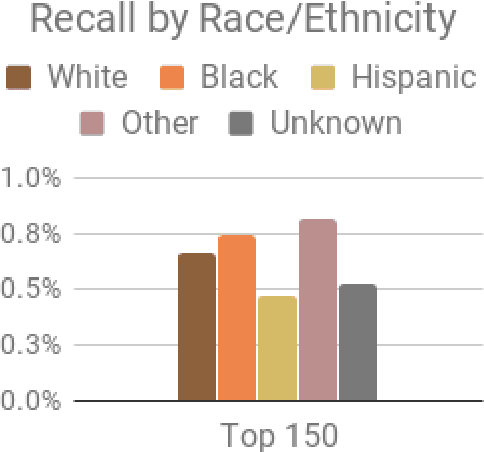
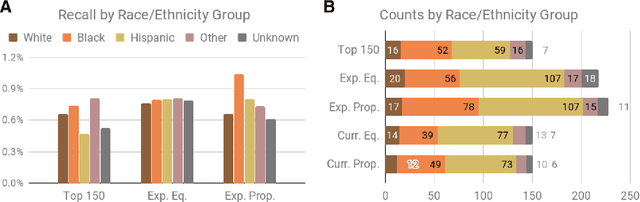
The criminal justice system is currently ill-equipped to improve outcomes of individuals who cycle in and out of the system with a series of misdemeanor offenses. Often due to constraints of caseload and poor record linkage, prior interactions with an individual may not be considered when an individual comes back into the system, let alone in a proactive manner through the application of diversion programs. The Los Angeles City Attorney's Office recently created a new Recidivism Reduction and Drug Diversion unit (R2D2) tasked with reducing recidivism in this population. Here we describe a collaboration with this new unit as a case study for the incorporation of predictive equity into machine learning based decision making in a resource-constrained setting. The program seeks to improve outcomes by developing individually-tailored social service interventions (i.e., diversions, conditional plea agreements, stayed sentencing, or other favorable case disposition based on appropriate social service linkage rather than traditional sentencing methods) for individuals likely to experience subsequent interactions with the criminal justice system, a time and resource-intensive undertaking that necessitates an ability to focus resources on individuals most likely to be involved in a future case. Seeking to achieve both efficiency (through predictive accuracy) and equity (improving outcomes in traditionally under-served communities and working to mitigate existing disparities in criminal justice outcomes), we discuss the equity outcomes we seek to achieve, describe the corresponding choice of a metric for measuring predictive fairness in this context, and explore a set of options for balancing equity and efficiency when building and selecting machine learning models in an operational public policy setting.