 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Importance of Application-Grounded Experimental Design for Evaluating Explainable ML Methods
Jun 30, 2022

Machine Learning (ML) models now inform a wide range of human decisions, but using ``black box'' models carries risks such as relying on spurious correlations or errant data. To address this, researchers have proposed methods for supplementing models with explanations of their predictions. However, robust evaluations of these methods' usefulness in real-world contexts have remained elusive, with experiments tending to rely on simplified settings or proxy tasks. We present an experimental study extending a prior explainable ML evaluation experiment and bringing the setup closer to the deployment setting by relaxing its simplifying assumptions. Our empirical study draws dramatically different conclusions than the prior work, highlighting how seemingly trivial experimental design choices can yield misleading results. Beyond the present experiment, we believe this work holds lessons about the necessity of situating the evaluation of any ML method and choosing appropriate tasks, data, users, and metrics to match the intended deployment contexts.
ConceptDistil: Model-Agnostic Distillation of Concept Explanations
May 07, 2022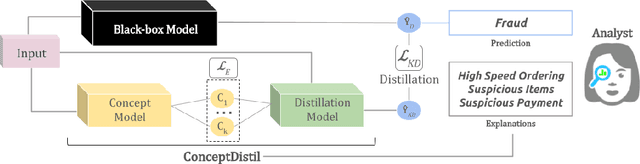
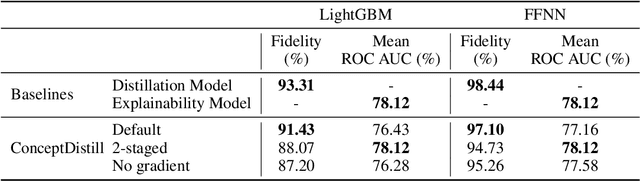
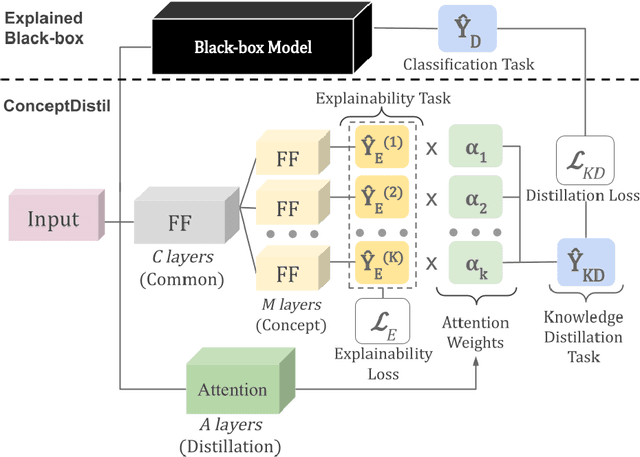

Concept-based explanations aims to fill the model interpretability gap for non-technical humans-in-the-loop. Previous work has focused on providing concepts for specific models (eg, neural networks) or data types (eg, images), and by either trying to extract concepts from an already trained network or training self-explainable models through multi-task learning. In this work, we propose ConceptDistil, a method to bring concept explanations to any black-box classifier using knowledge distillation. ConceptDistil is decomposed into two components:(1) a concept model that predicts which domain concepts are present in a given instance, and (2) a distillation model that tries to mimic the predictions of a black-box model using the concept model predictions. We validate ConceptDistil in a real world use-case, showing that it is able to optimize both tasks, bringing concept-explainability to any black-box model.
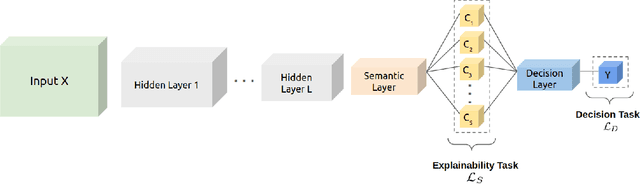
Weakly Supervised Multi-task Learning for Concept-based Explainability
Apr 26, 2021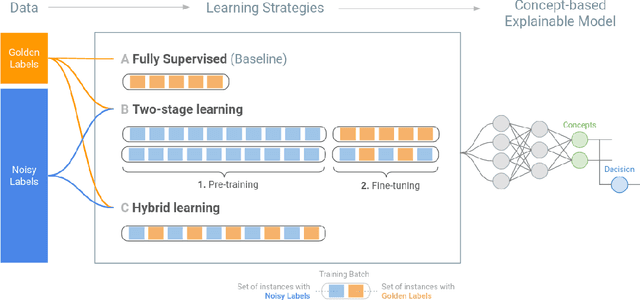
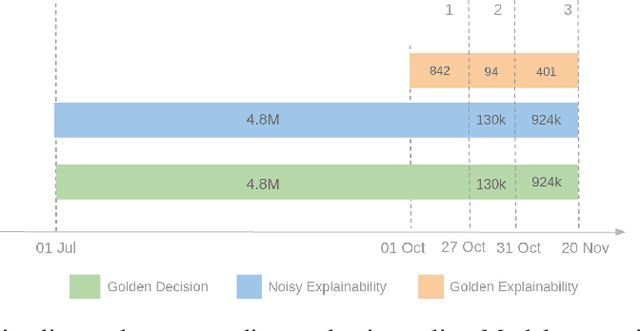
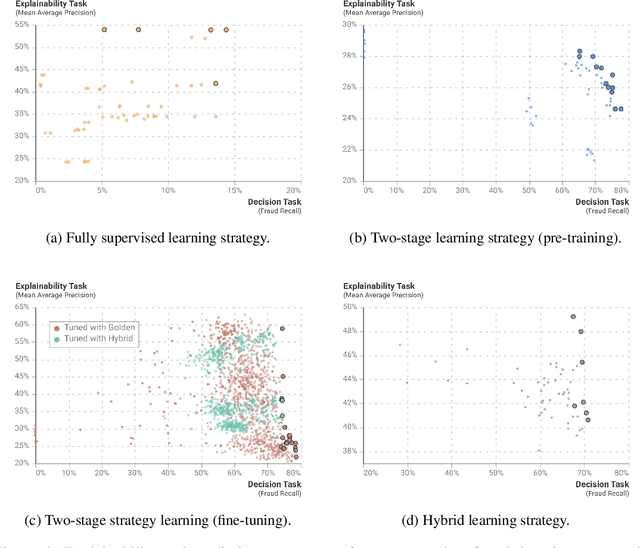
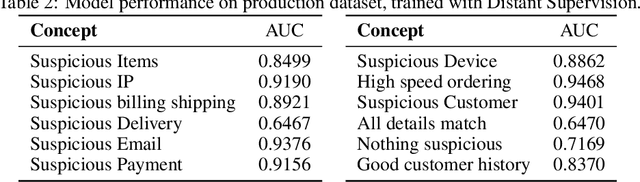
In ML-aided decision-making tasks, such as fraud detection or medical diagnosis, the human-in-the-loop, usually a domain-expert without technical ML knowledge, prefers high-level concept-based explanations instead of low-level explanations based on model features. To obtain faithful concept-based explanations, we leverage multi-task learning to train a neural network that jointly learns to predict a decision task based on the predictions of a precedent explainability task (i.e., multi-label concepts). There are two main challenges to overcome: concept label scarcity and the joint learning. To address both, we propose to: i) use expert rules to generate a large dataset of noisy concept labels, and ii) apply two distinct multi-task learning strategies combining noisy and golden labels. We compare these strategies with a fully supervised approach in a real-world fraud detection application with few golden labels available for the explainability task. With improvements of 9.26% and of 417.8% at the explainability and decision tasks, respectively, our results show it is possible to improve performance at both tasks by combining labels of heterogeneous quality.
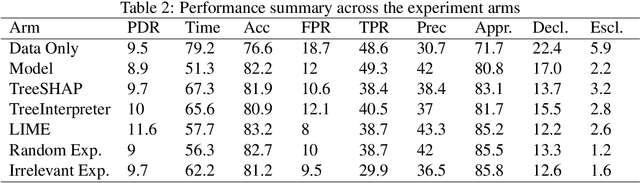
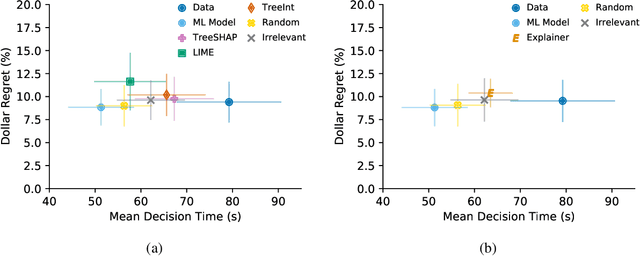
How can I choose an explainer? An Application-grounded Evaluation of Post-hoc Explanations
Jan 22, 2021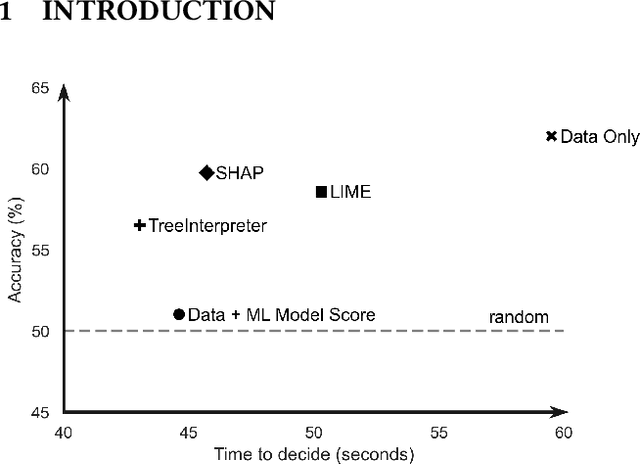
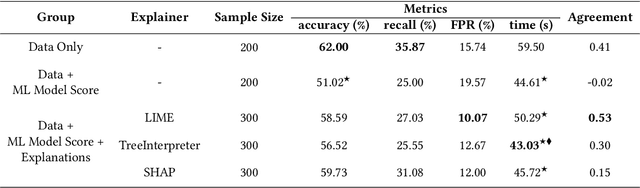
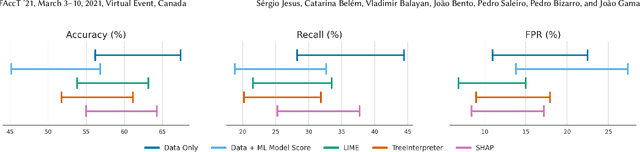
There have been several research works proposing new Explainable AI (XAI) methods designed to generate model explanations having specific properties, or desiderata, such as fidelity, robustness, or human-interpretability. However, explanations are seldom evaluated based on their true practical impact on decision-making tasks. Without that assessment, explanations might be chosen that, in fact, hurt the overall performance of the combined system of ML model + end-users. This study aims to bridge this gap by proposing XAI Test, an application-grounded evaluation methodology tailored to isolate the impact of providing the end-user with different levels of information. We conducted an experiment following XAI Test to evaluate three popular post-hoc explanation methods -- LIME, SHAP, and TreeInterpreter -- on a real-world fraud detection task, with real data, a deployed ML model, and fraud analysts. During the experiment, we gradually increased the information provided to the fraud analysts in three stages: Data Only, i.e., just transaction data without access to model score nor explanations, Data + ML Model Score, and Data + ML Model Score + Explanations. Using strong statistical analysis, we show that, in general, these popular explainers have a worse impact than desired. Some of the conclusion highlights include: i) showing Data Only results in the highest decision accuracy and the slowest decision time among all variants tested, ii) all the explainers improve accuracy over the Data + ML Model Score variant but still result in lower accuracy when compared with Data Only; iii) LIME was the least preferred by users, probably due to its substantially lower variability of explanations from case to case.
Teaching the Machine to Explain Itself using Domain Knowledge
Nov 27, 2020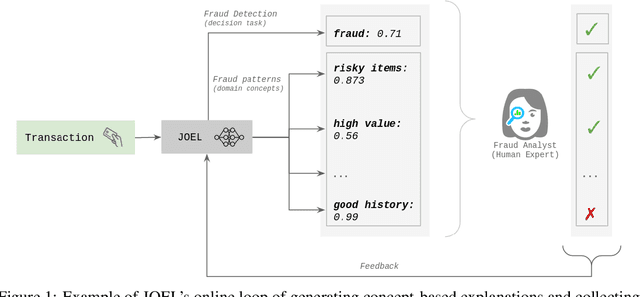
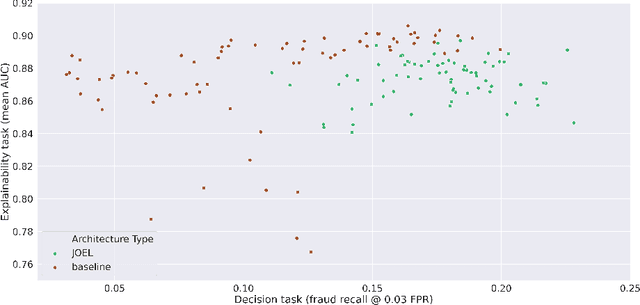
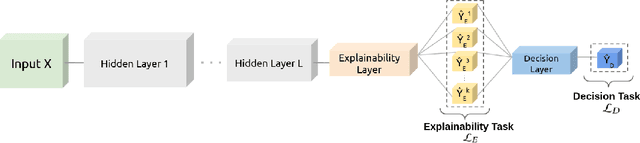
Machine Learning (ML) has been increasingly used to aid humans to make better and faster decisions. However, non-technical humans-in-the-loop struggle to comprehend the rationale behind model predictions, hindering trust in algorithmic decision-making systems. Considerable research work on AI explainability attempts to win back trust in AI systems by developing explanation methods but there is still no major breakthrough. At the same time, popular explanation methods (e.g., LIME, and SHAP) produce explanations that are very hard to understand for non-data scientist persona. To address this, we present JOEL, a neural network-based framework to jointly learn a decision-making task and associated explanations that convey domain knowledge. JOEL is tailored to human-in-the-loop domain experts that lack deep technical ML knowledge, providing high-level insights about the model's predictions that very much resemble the experts' own reasoning. Moreover, we collect the domain feedback from a pool of certified experts and use it to ameliorate the model (human teaching), hence promoting seamless and better suited explanations. Lastly, we resort to semantic mappings between legacy expert systems and domain taxonomies to automatically annotate a bootstrap training set, overcoming the absence of concept-based human annotations. We validate JOEL empirically on a real-world fraud detection dataset. We show that JOEL can generalize the explanations from the bootstrap dataset. Furthermore, obtained results indicate that human teaching can further improve the explanations prediction quality by approximately $13.57\%$.