 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSatellite-based feature extraction and multivariate time-series prediction of biotoxin contamination in shellfish
Nov 25, 2023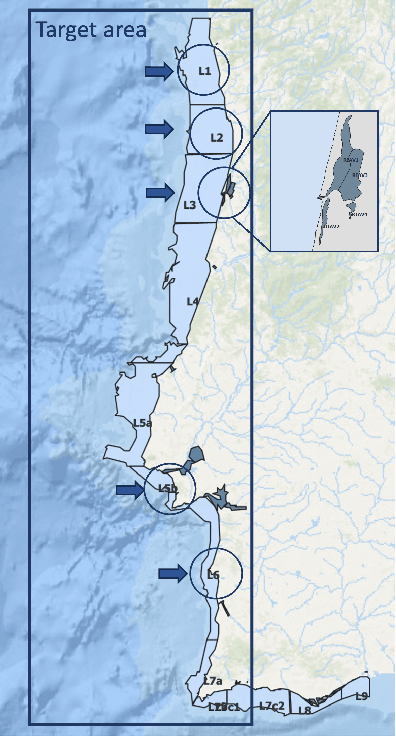
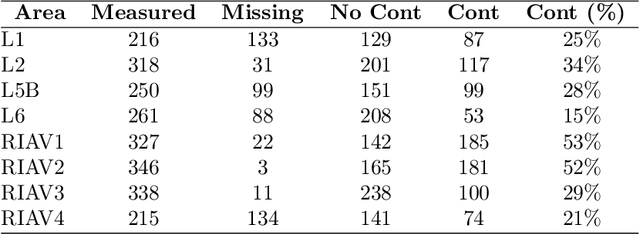


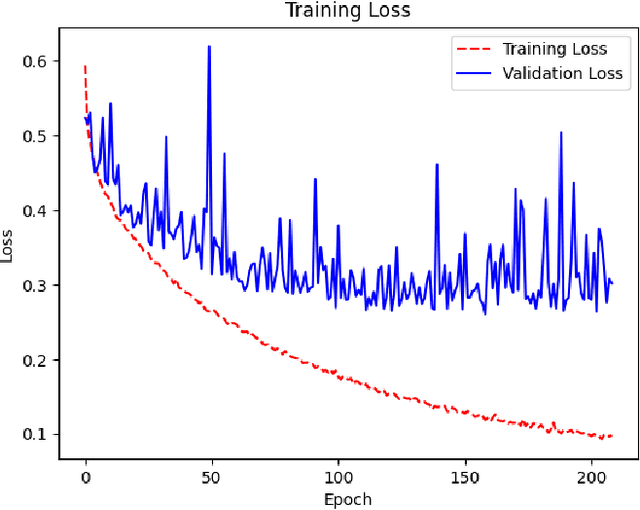
Shellfish production constitutes an important sector for the economy of many Portuguese coastal regions, yet the challenge of shellfish biotoxin contamination poses both public health concerns and significant economic risks. Thus, predicting shellfish contamination levels holds great potential for enhancing production management and safeguarding public health. In our study, we utilize a dataset with years of Sentinel-3 satellite imagery for marine surveillance, along with shellfish biotoxin contamination data from various production areas along Portugal's western coastline, collected by Portuguese official control. Our goal is to evaluate the integration of satellite data in forecasting models for predicting toxin concentrations in shellfish given forecasting horizons up to four weeks, which implies extracting a small set of useful features and assessing their impact on the predictive models. We framed this challenge as a time-series forecasting problem, leveraging historical contamination levels and satellite images for designated areas. While contamination measurements occurred weekly, satellite images were accessible multiple times per week. Unsupervised feature extraction was performed using autoencoders able to handle non-valid pixels caused by factors like cloud cover, land, or anomalies. Finally, several Artificial Neural Networks models were applied to compare univariate (contamination only) and multivariate (contamination and satellite data) time-series forecasting. Our findings show that incorporating these features enhances predictions, especially beyond one week in lagoon production areas (RIAV) and for the 1-week and 2-week horizons in the L5B area (oceanic). The methodology shows the feasibility of integrating information from a high-dimensional data source like remote sensing without compromising the model's predictive ability.
Faster than LASER -- Towards Stream Reasoning with Deep Neural Networks
Jun 15, 2021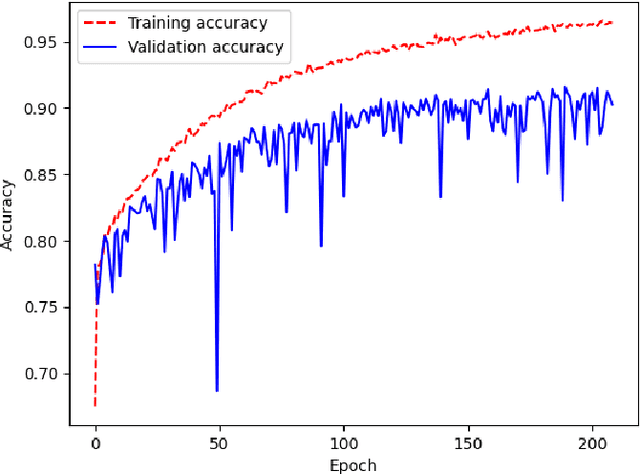
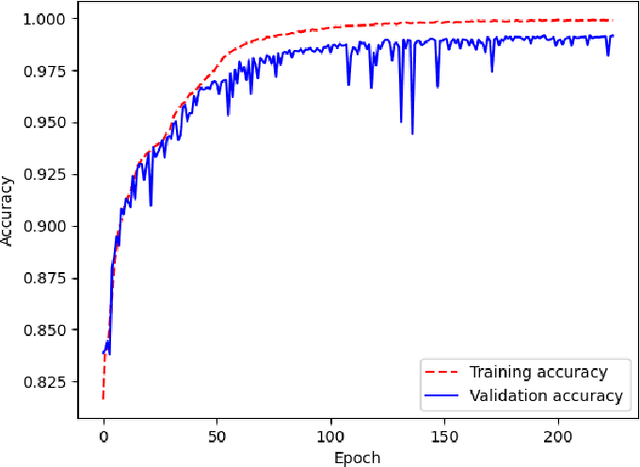
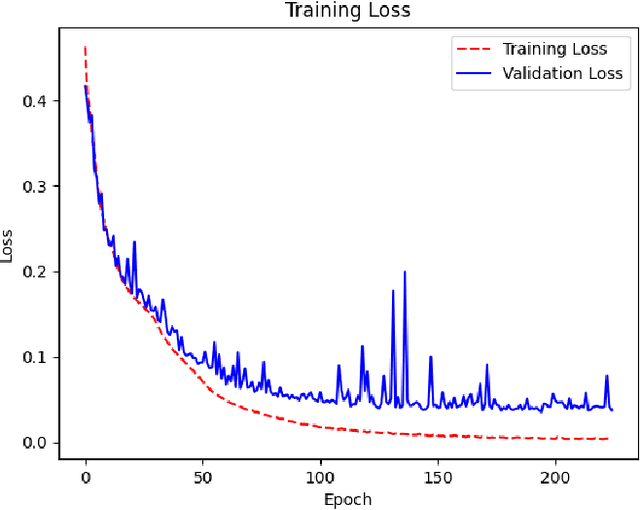
With the constant increase of available data in various domains, such as the Internet of Things, Social Networks or Smart Cities, it has become fundamental that agents are able to process and reason with such data in real time. Whereas reasoning over time-annotated data with background knowledge may be challenging, due to the volume and velocity in which such data is being produced, such complex reasoning is necessary in scenarios where agents need to discover potential problems and this cannot be done with simple stream processing techniques. Stream Reasoners aim at bridging this gap between reasoning and stream processing and LASER is such a stream reasoner designed to analyse and perform complex reasoning over streams of data. It is based on LARS, a rule-based logical language extending Answer Set Programming, and it has shown better runtime results than other state-of-the-art stream reasoning systems. Nevertheless, for high levels of data throughput even LASER may be unable to compute answers in a timely fashion. In this paper, we study whether Convolutional and Recurrent Neural Networks, which have shown to be particularly well-suited for time series forecasting and classification, can be trained to approximate reasoning with LASER, so that agents can benefit from their high processing speed.
Deep Neural Networks for Approximating Stream Reasoning with C-SPARQL
Jun 15, 2021
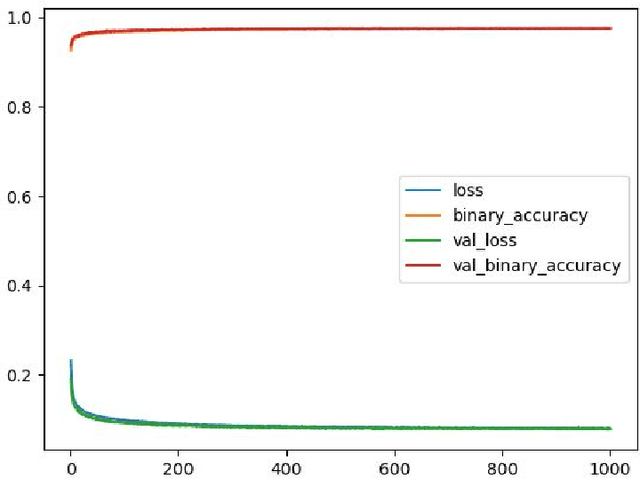
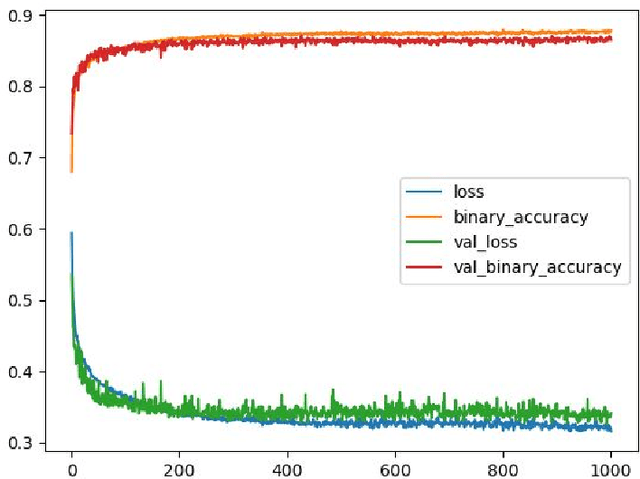
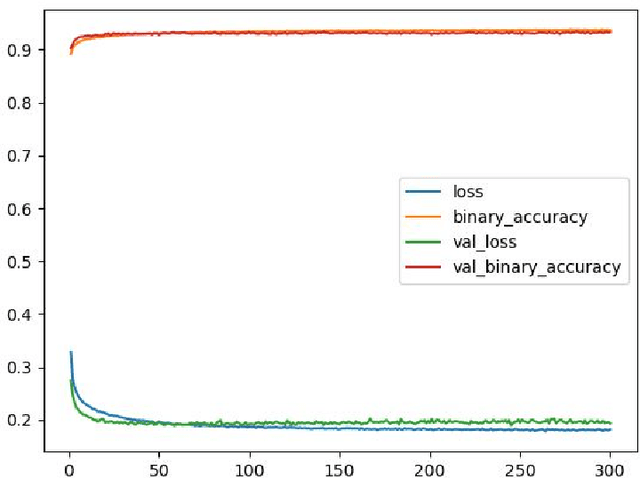
The amount of information produced, whether by newspapers, blogs and social networks, or by monitoring systems, is increasing rapidly. Processing all this data in real-time, while taking into consideration advanced knowledge about the problem domain, is challenging, but required in scenarios where assessing potential risks in a timely fashion is critical. C-SPARQL, a language for continuous queries over streams of RDF data, is one of the more prominent approaches in stream reasoning that provides such continuous inference capabilities over dynamic data that go beyond mere stream processing. However, it has been shown that, in the presence of huge amounts of data, C-SPARQL may not be able to answer queries in time, in particular when the frequency of incoming data is higher than the time required for reasoning with that data. In this paper, we investigate whether reasoning with C-SPARQL can be approximated using Recurrent Neural Networks and Convolutional Neural Networks, two neural network architectures that have been shown to be well-suited for time series forecasting and time series classification, to leverage on their higher processing speed once the network has been trained. We consider a variety of different kinds of queries and obtain overall positive results with high accuracies while improving processing time often by several orders of magnitude.
Explainable Abstract Trains Dataset
Dec 15, 2020
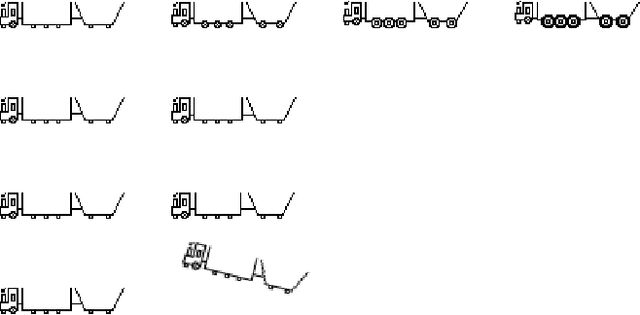

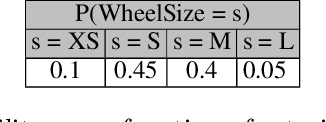
The Explainable Abstract Trains Dataset is an image dataset containing simplified representations of trains. It aims to provide a platform for the application and research of algorithms for justification and explanation extraction. The dataset is accompanied by an ontology that conceptualizes and classifies the depicted trains based on their visual characteristics, allowing for a precise understanding of how each train was labeled. Each image in the dataset is annotated with multiple attributes describing the trains' features and with bounding boxes for the train elements.
Teaching the Machine to Explain Itself using Domain Knowledge
Nov 27, 2020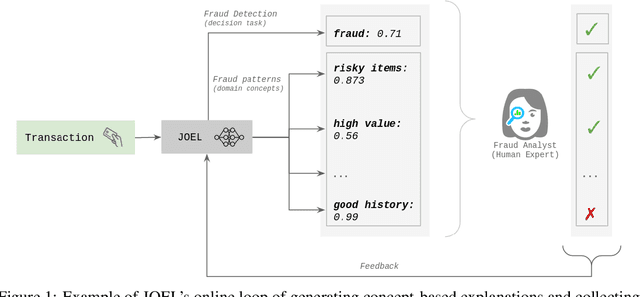
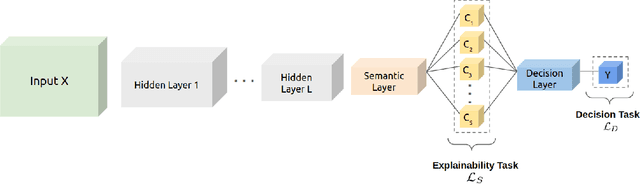
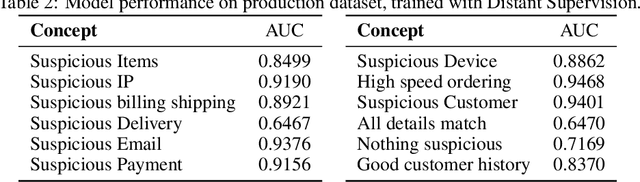
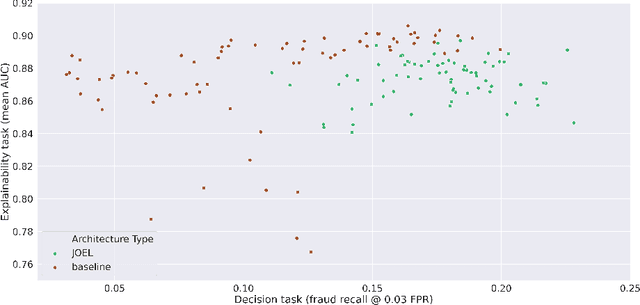
Machine Learning (ML) has been increasingly used to aid humans to make better and faster decisions. However, non-technical humans-in-the-loop struggle to comprehend the rationale behind model predictions, hindering trust in algorithmic decision-making systems. Considerable research work on AI explainability attempts to win back trust in AI systems by developing explanation methods but there is still no major breakthrough. At the same time, popular explanation methods (e.g., LIME, and SHAP) produce explanations that are very hard to understand for non-data scientist persona. To address this, we present JOEL, a neural network-based framework to jointly learn a decision-making task and associated explanations that convey domain knowledge. JOEL is tailored to human-in-the-loop domain experts that lack deep technical ML knowledge, providing high-level insights about the model's predictions that very much resemble the experts' own reasoning. Moreover, we collect the domain feedback from a pool of certified experts and use it to ameliorate the model (human teaching), hence promoting seamless and better suited explanations. Lastly, we resort to semantic mappings between legacy expert systems and domain taxonomies to automatically annotate a bootstrap training set, overcoming the absence of concept-based human annotations. We validate JOEL empirically on a real-world fraud detection dataset. We show that JOEL can generalize the explanations from the bootstrap dataset. Furthermore, obtained results indicate that human teaching can further improve the explanations prediction quality by approximately $13.57\%$.