 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAbstract Dialectical Frameworks are Boolean Networks (full version)
Jul 02, 2024
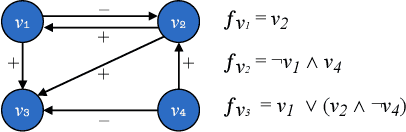

Dialectical frameworks are a unifying model of formal argumentation, where argumentative relations between arguments are represented by assigning acceptance conditions to atomic arguments. Their generality allow them to cover a number of different approaches with varying forms of representing the argumentation structure. Boolean regulatory networks are used to model the dynamics of complex biological processes, taking into account the interactions of biological compounds, such as proteins or genes. These models have proven highly useful for comprehending such biological processes, allowing to reproduce known behaviour and testing new hypotheses and predictions in silico, for example in the context of new medical treatments. While both these approaches stem from entirely different communities, it turns out that there are striking similarities in their appearence. In this paper, we study the relation between these two formalisms revealing their communalities as well as their differences, and introducing a correspondence that allows to establish novel results for the individual formalisms.
On Modifying a Neural Network's Perception
Mar 05, 2023



Artificial neural networks have proven to be extremely useful models that have allowed for multiple recent breakthroughs in the field of Artificial Intelligence and many others. However, they are typically regarded as black boxes, given how difficult it is for humans to interpret how these models reach their results. In this work, we propose a method which allows one to modify what an artificial neural network is perceiving regarding specific human-defined concepts, enabling the generation of hypothetical scenarios that could help understand and even debug the neural network model. Through empirical evaluation, in a synthetic dataset and in the ImageNet dataset, we test the proposed method on different models, assessing whether the performed manipulations are well interpreted by the models, and analyzing how they react to them.
A Brief History of Updates of Answer-Set Programs
Dec 27, 2021
Over the last couple of decades, there has been a considerable effort devoted to the problem of updating logic programs under the stable model semantics (a.k.a. answer-set programs) or, in other words, the problem of characterising the result of bringing up-to-date a logic program when the world it describes changes. Whereas the state-of-the-art approaches are guided by the same basic intuitions and aspirations as belief updates in the context of classical logic, they build upon fundamentally different principles and methods, which have prevented a unifying framework that could embrace both belief and rule updates. In this paper, we will overview some of the main approaches and results related to answer-set programming updates, while pointing out some of the main challenges that research in this topic has faced.
Forgetting in Answer Set Programming -- A Survey
Jul 14, 2021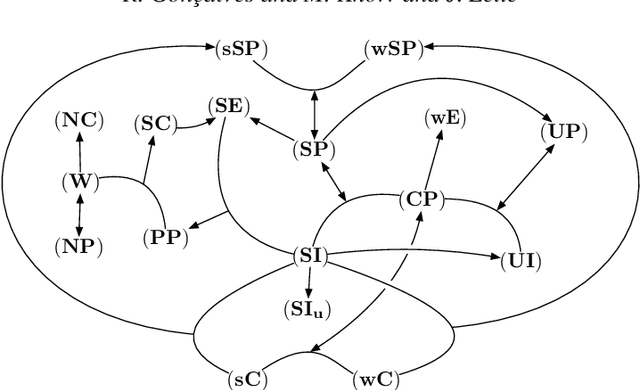



Forgetting - or variable elimination - is an operation that allows the removal, from a knowledge base, of middle variables no longer deemed relevant. In recent years, many different approaches for forgetting in Answer Set Programming have been proposed, in the form of specific operators, or classes of such operators, commonly following different principles and obeying different properties. Each such approach was developed to somehow address some particular view on forgetting, aimed at obeying a specific set of properties deemed desirable in such view, but a comprehensive and uniform overview of all the existing operators and properties is missing. In this paper, we thoroughly examine existing properties and (classes of) operators for forgetting in Answer Set Programming, drawing a complete picture of the landscape of these classes of forgetting operators, which includes many novel results on relations between properties and operators, including considerations on concrete operators to compute results of forgetting and computational complexity. Our goal is to provide guidance to help users in choosing the operator most adequate for their application requirements.
Faster than LASER -- Towards Stream Reasoning with Deep Neural Networks
Jun 15, 2021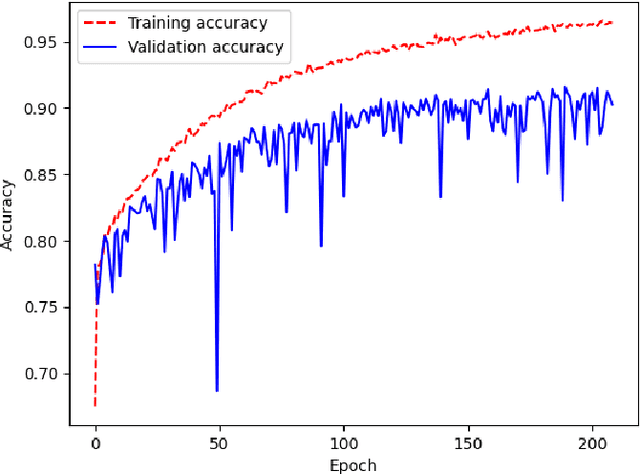
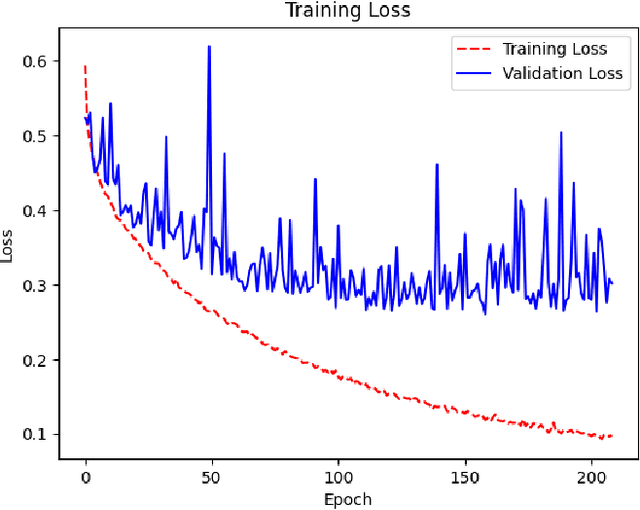
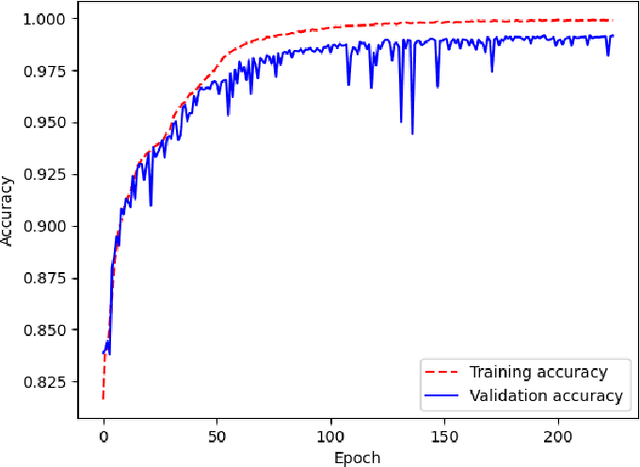
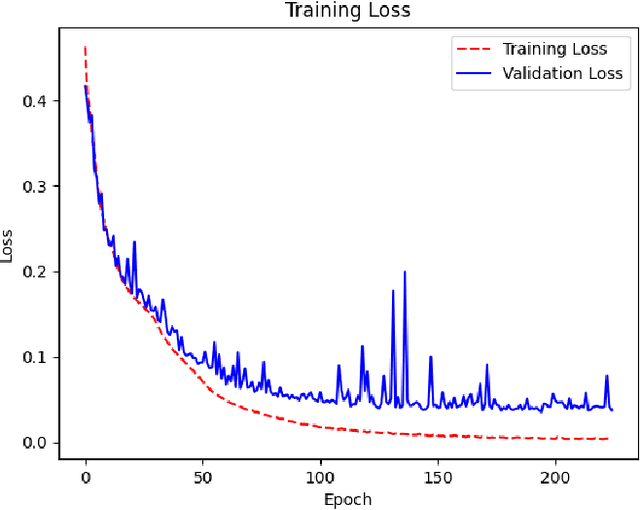
With the constant increase of available data in various domains, such as the Internet of Things, Social Networks or Smart Cities, it has become fundamental that agents are able to process and reason with such data in real time. Whereas reasoning over time-annotated data with background knowledge may be challenging, due to the volume and velocity in which such data is being produced, such complex reasoning is necessary in scenarios where agents need to discover potential problems and this cannot be done with simple stream processing techniques. Stream Reasoners aim at bridging this gap between reasoning and stream processing and LASER is such a stream reasoner designed to analyse and perform complex reasoning over streams of data. It is based on LARS, a rule-based logical language extending Answer Set Programming, and it has shown better runtime results than other state-of-the-art stream reasoning systems. Nevertheless, for high levels of data throughput even LASER may be unable to compute answers in a timely fashion. In this paper, we study whether Convolutional and Recurrent Neural Networks, which have shown to be particularly well-suited for time series forecasting and classification, can be trained to approximate reasoning with LASER, so that agents can benefit from their high processing speed.
Deep Neural Networks for Approximating Stream Reasoning with C-SPARQL
Jun 15, 2021
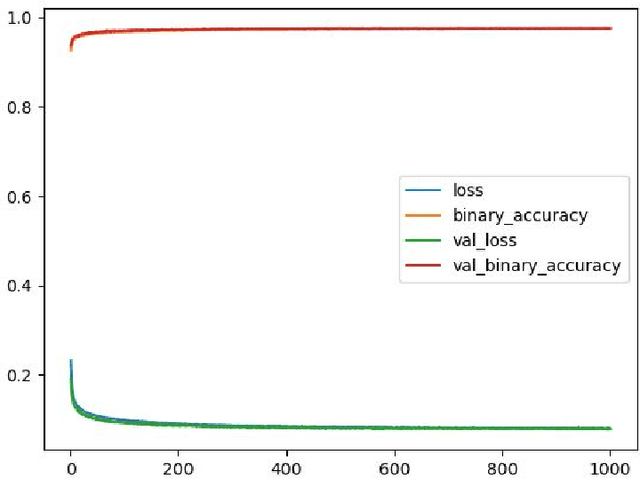
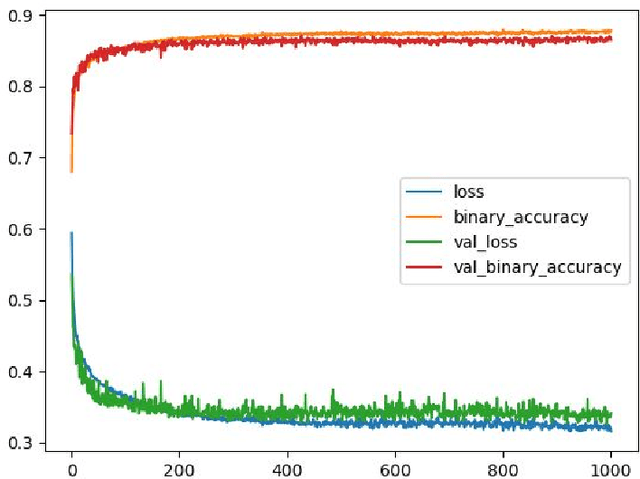
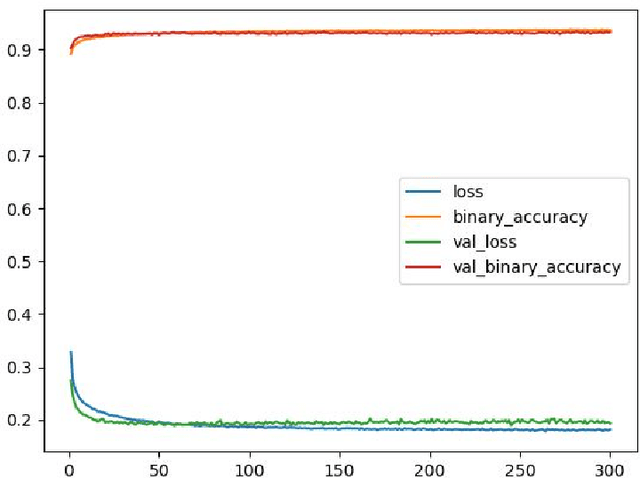
The amount of information produced, whether by newspapers, blogs and social networks, or by monitoring systems, is increasing rapidly. Processing all this data in real-time, while taking into consideration advanced knowledge about the problem domain, is challenging, but required in scenarios where assessing potential risks in a timely fashion is critical. C-SPARQL, a language for continuous queries over streams of RDF data, is one of the more prominent approaches in stream reasoning that provides such continuous inference capabilities over dynamic data that go beyond mere stream processing. However, it has been shown that, in the presence of huge amounts of data, C-SPARQL may not be able to answer queries in time, in particular when the frequency of incoming data is higher than the time required for reasoning with that data. In this paper, we investigate whether reasoning with C-SPARQL can be approximated using Recurrent Neural Networks and Convolutional Neural Networks, two neural network architectures that have been shown to be well-suited for time series forecasting and time series classification, to leverage on their higher processing speed once the network has been trained. We consider a variety of different kinds of queries and obtain overall positive results with high accuracies while improving processing time often by several orders of magnitude.
A Syntactic Operator for Forgetting that Satisfies Strong Persistence
Jul 31, 2019Whereas the operation of forgetting has recently seen a considerable amount of attention in the context of Answer Set Programming (ASP), most of it has focused on theoretical aspects, leaving the practical issues largely untouched. Recent studies include results about what sets of properties operators should satisfy, as well as the abstract characterization of several operators and their theoretical limits. However, no concrete operators have been investigated. In this paper, we address this issue by presenting the first concrete operator that satisfies strong persistence - a property that seems to best capture the essence of forgetting in the context of ASP - whenever this is possible, and many other important properties. The operator is syntactic, limiting the computation of the forgetting result to manipulating the rules in which the atoms to be forgotten occur, naturally yielding a forgetting result that is close to the original program. This paper is under consideration for acceptance in TPLP.
Reactive Multi-Context Systems: Heterogeneous Reasoning in Dynamic Environments
Dec 11, 2017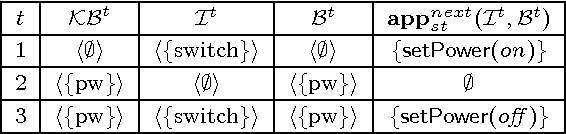
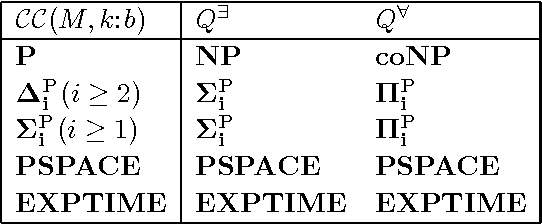

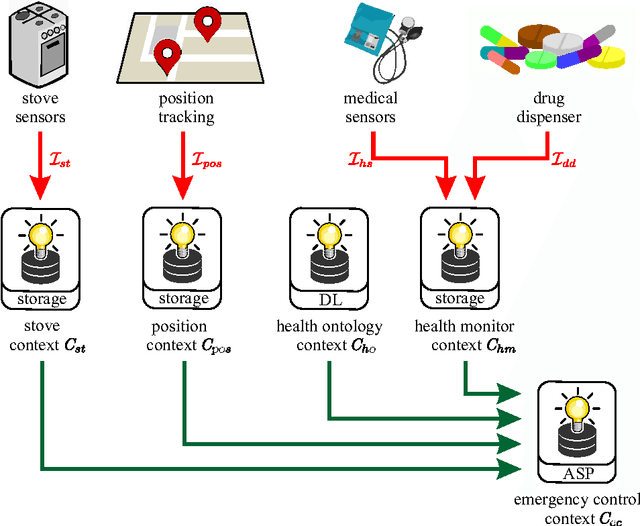
Managed multi-context systems (mMCSs) allow for the integration of heterogeneous knowledge sources in a modular and very general way. They were, however, mainly designed for static scenarios and are therefore not well-suited for dynamic environments in which continuous reasoning over such heterogeneous knowledge with constantly arriving streams of data is necessary. In this paper, we introduce reactive multi-context systems (rMCSs), a framework for reactive reasoning in the presence of heterogeneous knowledge sources and data streams. We show that rMCSs are indeed well-suited for this purpose by illustrating how several typical problems arising in the context of stream reasoning can be handled using them, by showing how inconsistencies possibly occurring in the integration of multiple knowledge sources can be handled, and by arguing that the potential non-determinism of rMCSs can be avoided if needed using an alternative, more skeptical well-founded semantics instead with beneficial computational properties. We also investigate the computational complexity of various reasoning problems related to rMCSs. Finally, we discuss related work, and show that rMCSs do not only generalize mMCSs to dynamic settings, but also capture/extend relevant approaches w.r.t. dynamics in knowledge representation and stream reasoning.
When You Must Forget: beyond strong persistence when forgetting in answer set programming
Jul 17, 2017Among the myriad of desirable properties discussed in the context of forgetting in Answer Set Programming (ASP), strong persistence naturally captures its essence. Recently, it has been shown that it is not always possible to forget a set of atoms from a program while obeying this property, and a precise criterion regarding what can be forgotten has been presented, accompanied by a class of forgetting operators that return the correct result when forgetting is possible. However, it is an open question what to do when we have to forget a set of atoms, but cannot without violating this property. In this paper, we address this issue and investigate three natural alternatives to forget when forgetting without violating strong persistence is not possible, which turn out to correspond to the different possible relaxations of the characterization of strong persistence. Additionally, we discuss their preferable usage, shed light on the relation between forgetting and notions of relativized equivalence established earlier in the context of ASP, and present a detailed study on their computational complexity.
A note on the uniqueness of models in social abstract argumentation
May 09, 2017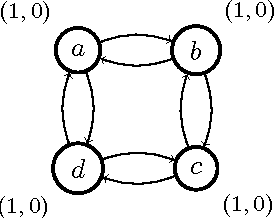

Social abstract argumentation is a principled way to assign values to conflicting (weighted) arguments. In this note we discuss the important property of the uniqueness of the model.