 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaking feature importance: A cautionary tale on the use of differentially-private synthetic data
Mar 02, 2022
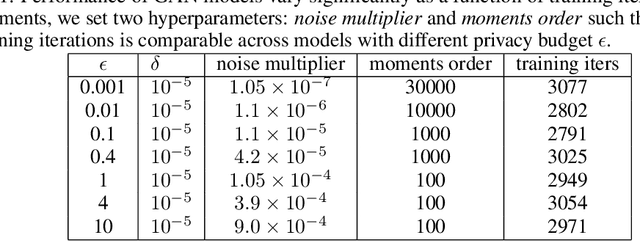

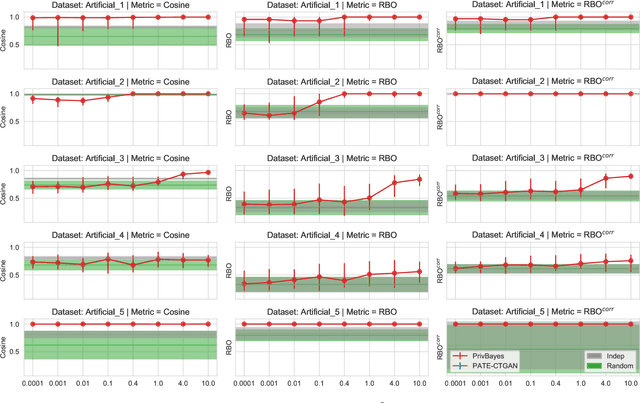
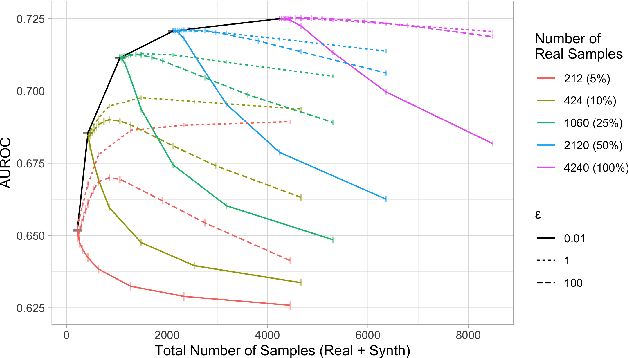
Synthetic datasets are often presented as a silver-bullet solution to the problem of privacy-preserving data publishing. However, for many applications, synthetic data has been shown to have limited utility when used to train predictive models. One promising potential application of these data is in the exploratory phase of the machine learning workflow, which involves understanding, engineering and selecting features. This phase often involves considerable time, and depends on the availability of data. There would be substantial value in synthetic data that permitted these steps to be carried out while, for example, data access was being negotiated, or with fewer information governance restrictions. This paper presents an empirical analysis of the agreement between the feature importance obtained from raw and from synthetic data, on a range of artificially generated and real-world datasets (where feature importance represents how useful each feature is when predicting a the outcome). We employ two differentially-private methods to produce synthetic data, and apply various utility measures to quantify the agreement in feature importance as this varies with the level of privacy. Our results indicate that synthetic data can sometimes preserve several representations of the ranking of feature importance in simple settings but their performance is not consistent and depends upon a number of factors. Particular caution should be exercised in more nuanced real-world settings, where synthetic data can lead to differences in ranked feature importance that could alter key modelling decisions. This work has important implications for developing synthetic versions of highly sensitive data sets in fields such as finance and healthcare.
Bias Mitigated Learning from Differentially Private Synthetic Data: A Cautionary Tale
Aug 24, 2021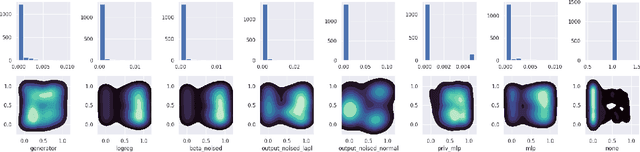
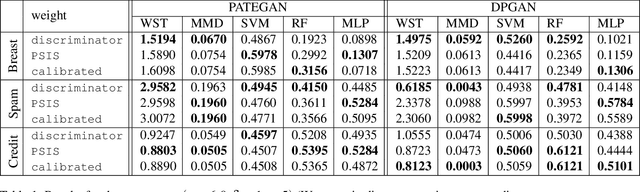
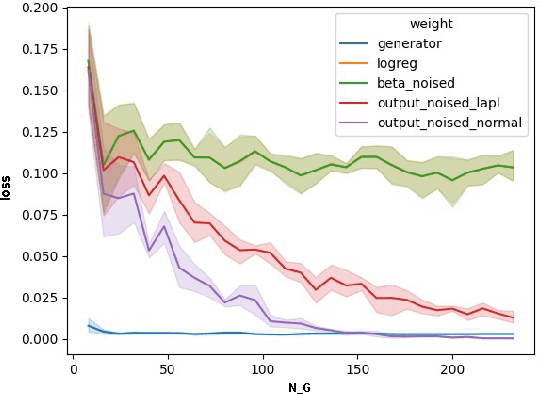
Increasing interest in privacy-preserving machine learning has led to new models for synthetic private data generation from undisclosed real data. However, mechanisms of privacy preservation introduce artifacts in the resulting synthetic data that have a significant impact on downstream tasks such as learning predictive models or inference. In particular, bias can affect all analyses as the synthetic data distribution is an inconsistent estimate of the real-data distribution. We propose several bias mitigation strategies using privatized likelihood ratios that have general applicability to differentially private synthetic data generative models. Through large-scale empirical evaluation, we show that bias mitigation provides simple and effective privacy-compliant augmentation for general applications of synthetic data. However, the work highlights that even after bias correction significant challenges remain on the usefulness of synthetic private data generators for tasks such as prediction and inference.
Foundations of Bayesian Learning from Synthetic Data
Nov 24, 2020
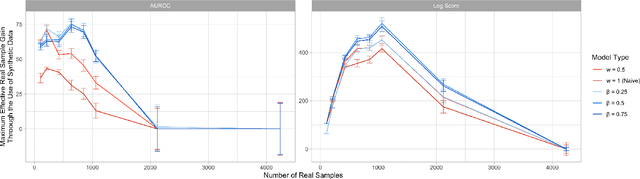
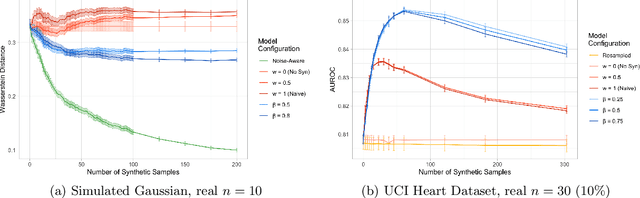
There is significant growth and interest in the use of synthetic data as an enabler for machine learning in environments where the release of real data is restricted due to privacy or availability constraints. Despite a large number of methods for synthetic data generation, there are comparatively few results on the statistical properties of models learnt on synthetic data, and fewer still for situations where a researcher wishes to augment real data with another party's synthesised data. We use a Bayesian paradigm to characterise the updating of model parameters when learning in these settings, demonstrating that caution should be taken when applying conventional learning algorithms without appropriate consideration of the synthetic data generating process and learning task. Recent results from general Bayesian updating support a novel and robust approach to Bayesian synthetic-learning founded on decision theory that outperforms standard approaches across repeated experiments on supervised learning and inference problems.
A Recommendation and Risk Classification System for Connecting Rough Sleepers to Essential Outreach Services
Jul 30, 2020

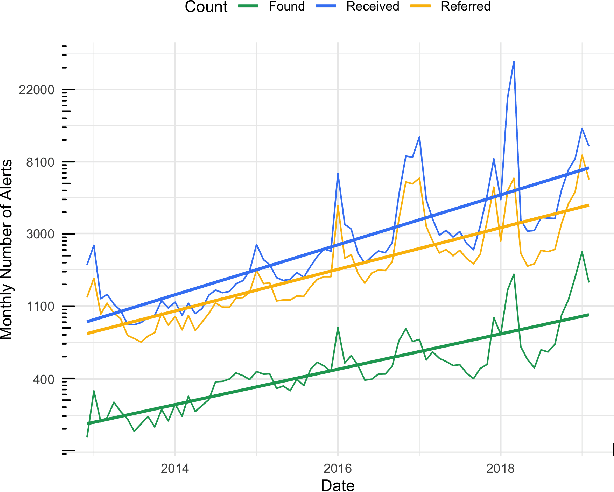

Rough sleeping is a chronic problem faced by some of the most disadvantaged people in modern society. This paper describes work carried out in partnership with Homeless Link, a UK-based charity, in developing a data-driven approach to assess the quality of incoming alerts from members of the public aimed at connecting people sleeping rough on the streets with outreach service providers. Alerts are prioritised based on the predicted likelihood of successfully connecting with the rough sleeper, helping to address capacity limitations and to quickly, effectively, and equitably process all of the alerts that they receive. Initial evaluation concludes that our approach increases the rate at which rough sleepers are found following a referral by at least 15\% based on labelled data, implying a greater overall increase when the alerts with unknown outcomes are considered, and suggesting the benefit in a trial taking place over a longer period to assess the models in practice. The discussion and modelling process is done with careful considerations of ethics, transparency and explainability due to the sensitive nature of the data in this context and the vulnerability of the people that are affected.