 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBias Mitigated Learning from Differentially Private Synthetic Data: A Cautionary Tale
Paper and Code
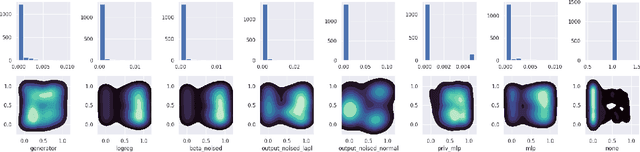
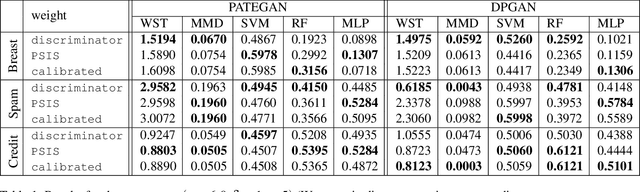
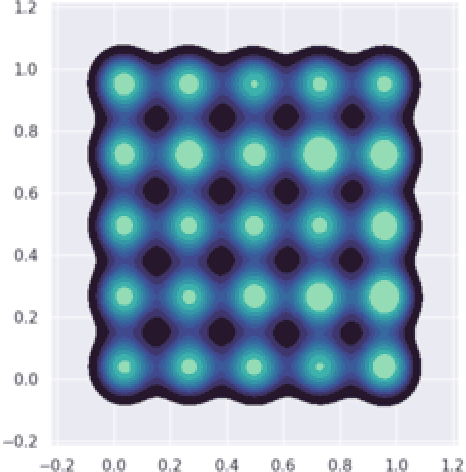
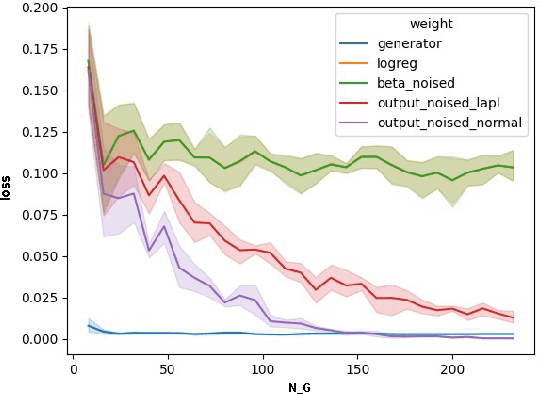
Increasing interest in privacy-preserving machine learning has led to new models for synthetic private data generation from undisclosed real data. However, mechanisms of privacy preservation introduce artifacts in the resulting synthetic data that have a significant impact on downstream tasks such as learning predictive models or inference. In particular, bias can affect all analyses as the synthetic data distribution is an inconsistent estimate of the real-data distribution. We propose several bias mitigation strategies using privatized likelihood ratios that have general applicability to differentially private synthetic data generative models. Through large-scale empirical evaluation, we show that bias mitigation provides simple and effective privacy-compliant augmentation for general applications of synthetic data. However, the work highlights that even after bias correction significant challenges remain on the usefulness of synthetic private data generators for tasks such as prediction and inference.