 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Defender Strategies for CAGE-2 using Causal Modeling and Tree Search
Jul 12, 2024The CAGE-2 challenge is considered a standard benchmark to compare methods for autonomous cyber defense. Current state-of-the-art methods evaluated against this benchmark are based on model-free (offline) reinforcement learning, which does not provide provably optimal defender strategies. We address this limitation and present a formal (causal) model of CAGE-2 together with a method that produces a provably optimal defender strategy, which we call Causal Partially Observable Monte-Carlo Planning (C-POMCP). It has two key properties. First, it incorporates the causal structure of the target system, i.e., the causal relationships among the system variables. This structure allows for a significant reduction of the search space of defender strategies. Second, it is an online method that updates the defender strategy at each time step via tree search. Evaluations against the CAGE-2 benchmark show that C-POMCP achieves state-of-the-art performance with respect to effectiveness and is two orders of magnitude more efficient in computing time than the closest competitor method.
Optimal Observation-Intervention Trade-Off in Optimisation Problems with Causal Structure
Sep 05, 2023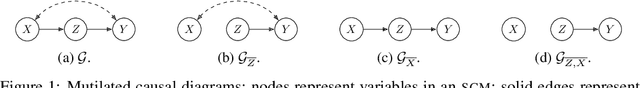

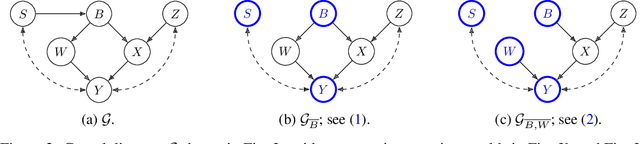

We consider the problem of optimising an expensive-to-evaluate grey-box objective function, within a finite budget, where known side-information exists in the form of the causal structure between the design variables. Standard black-box optimisation ignores the causal structure, often making it inefficient and expensive. The few existing methods that consider the causal structure are myopic and do not fully accommodate the observation-intervention trade-off that emerges when estimating causal effects. In this paper, we show that the observation-intervention trade-off can be formulated as a non-myopic optimal stopping problem which permits an efficient solution. We give theoretical results detailing the structure of the optimal stopping times and demonstrate the generality of our approach by showing that it can be integrated with existing causal Bayesian optimisation algorithms. Experimental results show that our formulation can enhance existing algorithms on real and synthetic benchmarks.
Causal Entropy Optimization
Aug 23, 2022
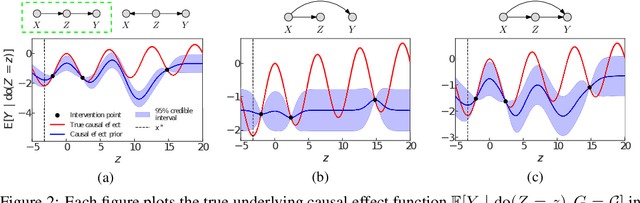

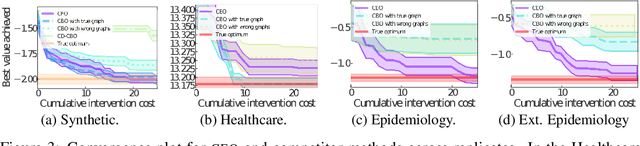
We study the problem of globally optimizing the causal effect on a target variable of an unknown causal graph in which interventions can be performed. This problem arises in many areas of science including biology, operations research and healthcare. We propose Causal Entropy Optimization (CEO), a framework that generalizes Causal Bayesian Optimization (CBO) to account for all sources of uncertainty, including the one arising from the causal graph structure. CEO incorporates the causal structure uncertainty both in the surrogate models for the causal effects and in the mechanism used to select interventions via an information-theoretic acquisition function. The resulting algorithm automatically trades-off structure learning and causal effect optimization, while naturally accounting for observation noise. For various synthetic and real-world structural causal models, CEO achieves faster convergence to the global optimum compared with CBO while also learning the graph. Furthermore, our joint approach to structure learning and causal optimization improves upon sequential, structure-learning-first approaches.
Developing Optimal Causal Cyber-Defence Agents via Cyber Security Simulation
Aug 05, 2022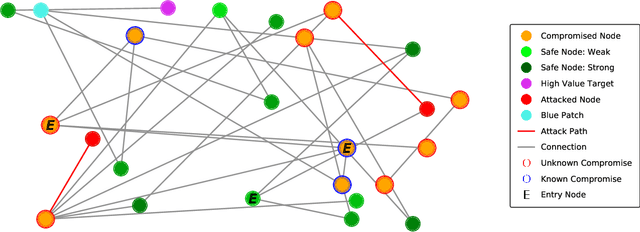

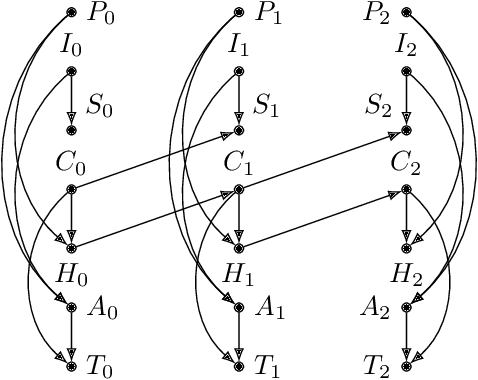

In this paper we explore cyber security defence, through the unification of a novel cyber security simulator with models for (causal) decision-making through optimisation. Particular attention is paid to a recently published approach: dynamic causal Bayesian optimisation (DCBO). We propose that DCBO can act as a blue agent when provided with a view of a simulated network and a causal model of how a red agent spreads within that network. To investigate how DCBO can perform optimal interventions on host nodes, in order to reduce the cost of intrusions caused by the red agent. Through this we demonstrate a complete cyber-simulation system, which we use to generate observational data for DCBO and provide numerical quantitative results which lay the foundations for future work in this space.
Chronological Causal Bandits
Dec 03, 2021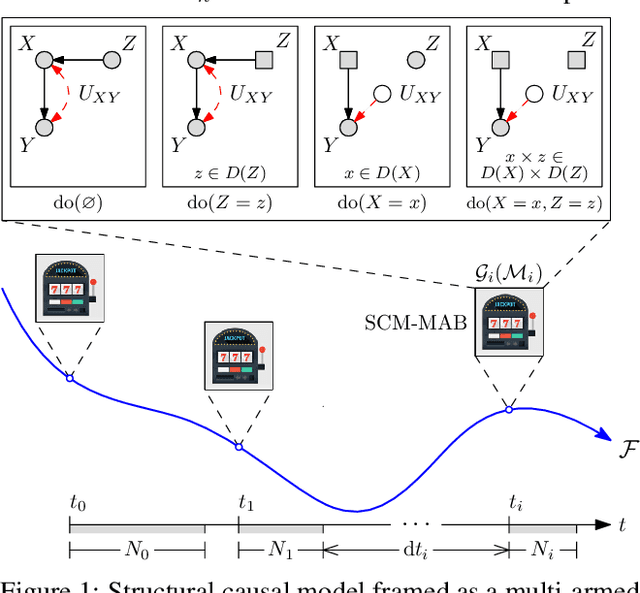



This paper studies an instance of the multi-armed bandit (MAB) problem, specifically where several causal MABs operate chronologically in the same dynamical system. Practically the reward distribution of each bandit is governed by the same non-trivial dependence structure, which is a dynamic causal model. Dynamic because we allow for each causal MAB to depend on the preceding MAB and in doing so are able to transfer information between agents. Our contribution, the Chronological Causal Bandit (CCB), is useful in discrete decision-making settings where the causal effects are changing across time and can be informed by earlier interventions in the same system. In this paper, we present some early findings of the CCB as demonstrated on a toy problem.
Dynamic Causal Bayesian Optimization
Oct 26, 2021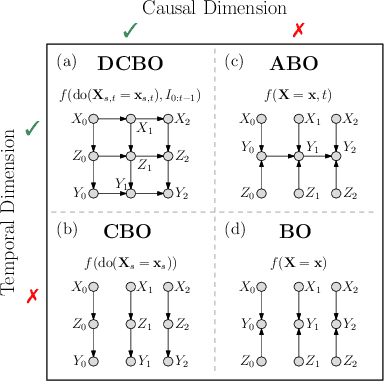
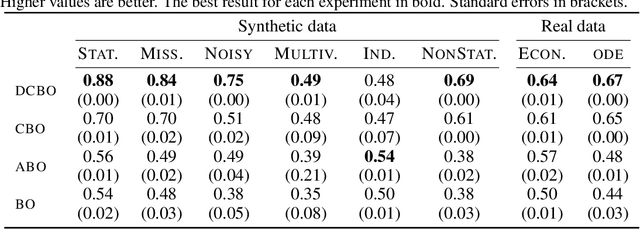
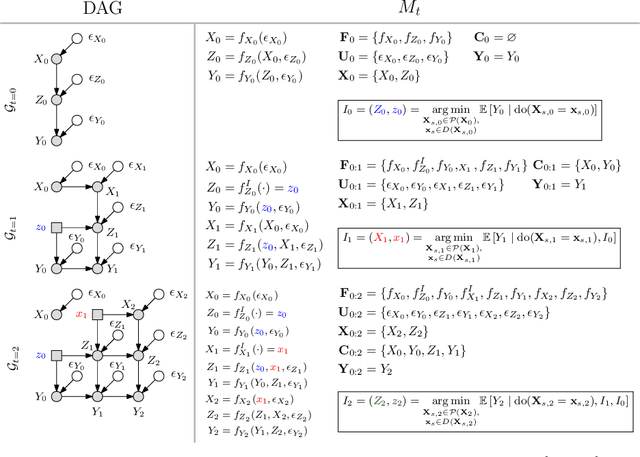
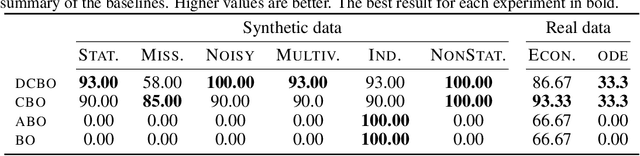
This paper studies the problem of performing a sequence of optimal interventions in a causal dynamical system where both the target variable of interest and the inputs evolve over time. This problem arises in a variety of domains e.g. system biology and operational research. Dynamic Causal Bayesian Optimization (DCBO) brings together ideas from sequential decision making, causal inference and Gaussian process (GP) emulation. DCBO is useful in scenarios where all causal effects in a graph are changing over time. At every time step DCBO identifies a local optimal intervention by integrating both observational and past interventional data collected from the system. We give theoretical results detailing how one can transfer interventional information across time steps and define a dynamic causal GP model which can be used to quantify uncertainty and find optimal interventions in practice. We demonstrate how DCBO identifies optimal interventions faster than competing approaches in multiple settings and applications.
Prospective Artificial Intelligence Approaches for Active Cyber Defence
Apr 20, 2021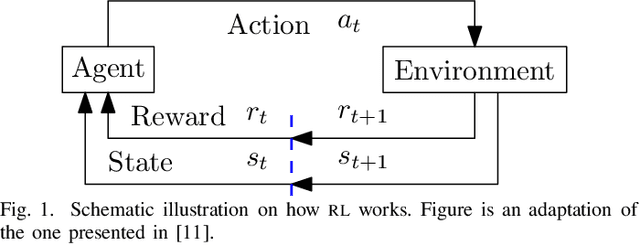
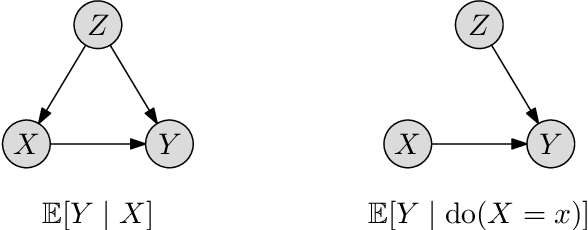
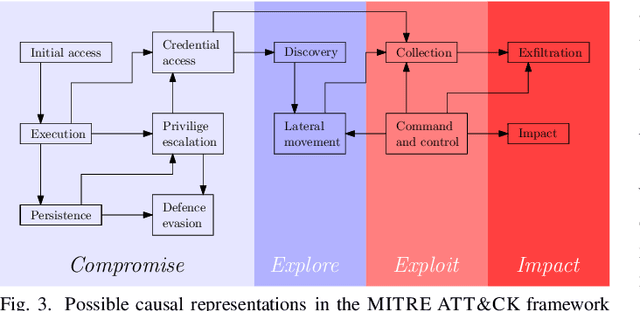
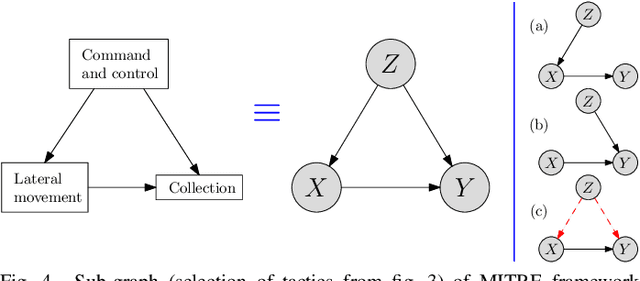
Cybercriminals are rapidly developing new malicious tools that leverage artificial intelligence (AI) to enable new classes of adaptive and stealthy attacks. New defensive methods need to be developed to counter these threats. Some cybersecurity professionals are speculating AI will enable corresponding new classes of active cyber defence measures -- is this realistic, or currently mostly hype? The Alan Turing Institute, with expert guidance from the UK National Cyber Security Centre and Defence Science Technology Laboratory, published a research roadmap for AI for ACD last year. This position paper updates the roadmap for two of the most promising AI approaches -- reinforcement learning and causal inference - and describes why they could help tip the balance back towards defenders.
An Expectation-Based Network Scan Statistic for a COVID-19 Early Warning System
Dec 08, 2020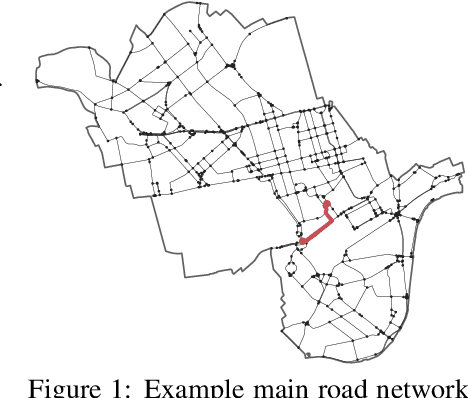
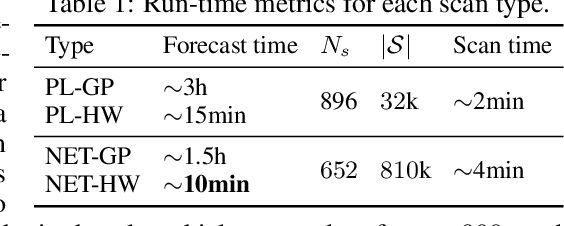
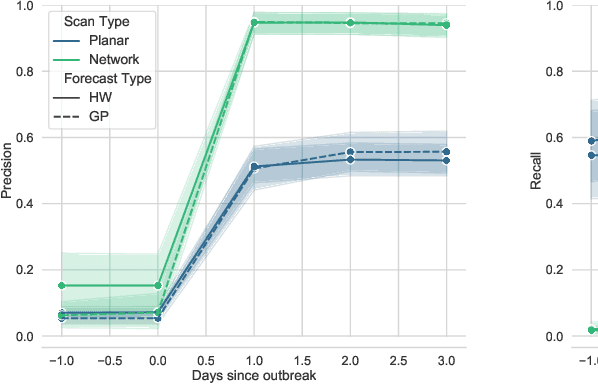
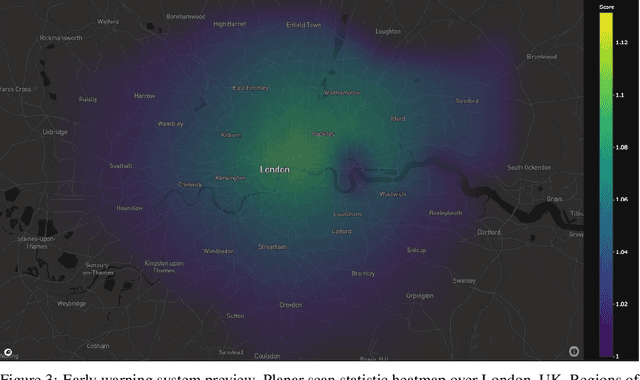
One of the Greater London Authority's (GLA) response to the COVID-19 pandemic brings together multiple large-scale and heterogeneous datasets capturing mobility, transportation and traffic activity over the city of London to better understand 'busyness' and enable targeted interventions and effective policy-making. As part of Project Odysseus we describe an early-warning system and introduce an expectation-based scan statistic for networks to help the GLA and Transport for London, understand the extent to which populations are following government COVID-19 guidelines. We explicitly treat the case of geographically fixed time-series data located on a (road) network and primarily focus on monitoring the dynamics across large regions of the capital. Additionally, we also focus on the detection and reporting of significant spatio-temporal regions. Our approach is extending the Network Based Scan Statistic (NBSS) by making it expectation-based (EBP) and by using stochastic processes for time-series forecasting, which enables us to quantify metric uncertainty in both the EBP and NBSS frameworks. We introduce a variant of the metric used in the EBP model which focuses on identifying space-time regions in which activity is quieter than expected.
Near Real-Time Social Distancing in London
Dec 07, 2020
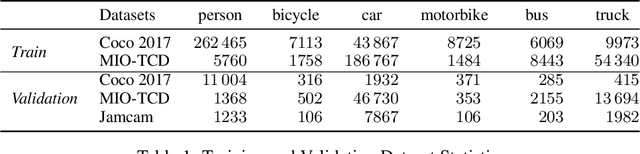
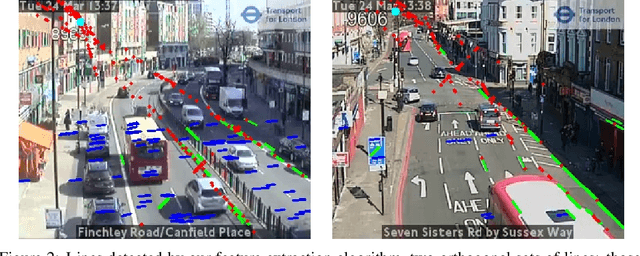
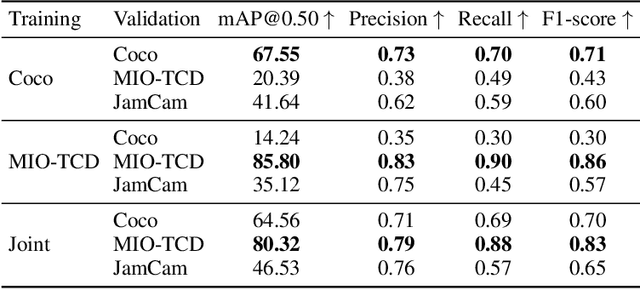
During the COVID-19 pandemic, policy makers at the Greater London Authority, the regional governance body of London, UK, are reliant upon prompt and accurate data sources. Large well-defined heterogeneous compositions of activity throughout the city are sometimes difficult to acquire, yet are a necessity in order to learn 'busyness' and consequently make safe policy decisions. One component of our project within this space is to utilise existing infrastructure to estimate social distancing adherence by the general public. Our method enables near immediate sampling and contextualisation of activity and physical distancing on the streets of London via live traffic camera feeds. We introduce a framework for inspecting and improving upon existing methods, whilst also describing its active deployment on over 900 real-time feeds.
Boltzmann Exploration Expectation-Maximisation
Dec 18, 2019


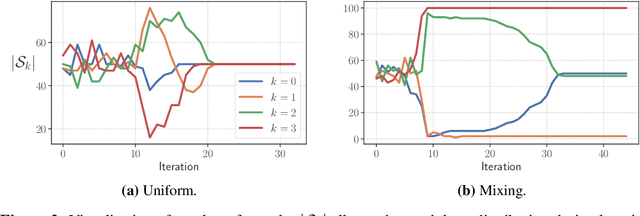
We present a general method for fitting finite mixture models (FMM). Learning in a mixture model consists of finding the most likely cluster assignment for each data-point, as well as finding the parameters of the clusters themselves. In many mixture models, this is difficult with current learning methods, where the most common approach is to employ monotone learning algorithms e.g. the conventional expectation-maximisation algorithm. While effective, the success of any monotone algorithm is crucially dependant on good parameter initialisation, where a common choice is $K$-means initialisation, commonly employed for Gaussian mixture models. For other types of mixture models, the path to good initialisation parameters is often unclear and may require a problem-specific solution. To this end, we propose a general heuristic learning algorithm that utilises Boltzmann exploration to assign each observation to a specific base distribution within the mixture model, which we call Boltzmann exploration expectation-maximisation (BEEM). With BEEM, hard assignments allow straight forward parameter learning for each base distribution by conditioning only on its assigned observations. Consequently, it can be applied to mixtures of any base distribution where single component parameter learning is tractable. The stochastic learning procedure is able to escape local optima and is thus insensitive to parameter initialisation. We show competitive performance on a number of synthetic benchmark cases as well as on real-world datasets.