 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCCC/Code 8.7: Applying AI in the Fight Against Modern Slavery
Jun 24, 2021On any given day, tens of millions of people find themselves trapped in instances of modern slavery. The terms "human trafficking," "trafficking in persons," and "modern slavery" are sometimes used interchangeably to refer to both sex trafficking and forced labor. Human trafficking occurs when a trafficker compels someone to provide labor or services through the use of force, fraud, and/or coercion. The wide range of stakeholders in human trafficking presents major challenges. Direct stakeholders are law enforcement, NGOs and INGOs, businesses, local/planning government authorities, and survivors. Viewed from a very high level, all stakeholders share in a rich network of interactions that produce and consume enormous amounts of information. The problems of making efficient use of such information for the purposes of fighting trafficking while at the same time adhering to community standards of privacy and ethics are formidable. At the same time they help us, technologies that increase surveillance of populations can also undermine basic human rights. In early March 2020, the Computing Community Consortium (CCC), in collaboration with the Code 8.7 Initiative, brought together over fifty members of the computing research community along with anti-slavery practitioners and survivors to lay out a research roadmap. The primary goal was to explore ways in which long-range research in artificial intelligence (AI) could be applied to the fight against human trafficking. Building on the kickoff Code 8.7 conference held at the headquarters of the United Nations in February 2019, the focus for this workshop was to link the ambitious goals outlined in the A 20-Year Community Roadmap for Artificial Intelligence Research in the US (AI Roadmap) to challenges vital in achieving the UN's Sustainable Development Goal Target 8.7, the elimination of modern slavery.
Prospective Artificial Intelligence Approaches for Active Cyber Defence
Apr 20, 2021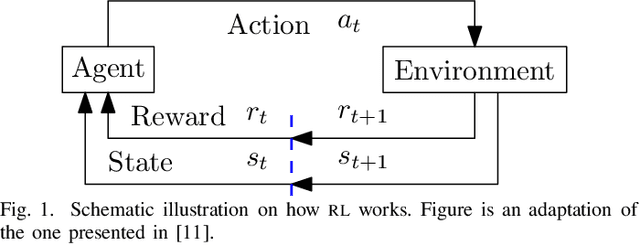
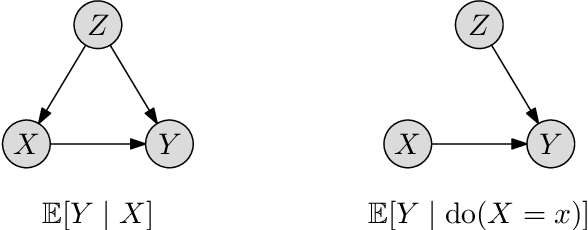
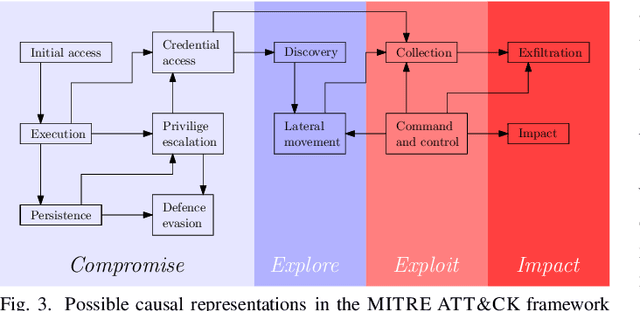
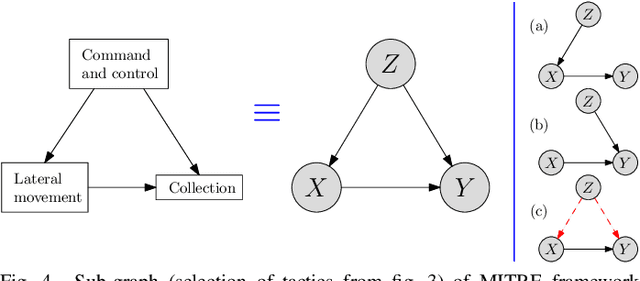
Cybercriminals are rapidly developing new malicious tools that leverage artificial intelligence (AI) to enable new classes of adaptive and stealthy attacks. New defensive methods need to be developed to counter these threats. Some cybersecurity professionals are speculating AI will enable corresponding new classes of active cyber defence measures -- is this realistic, or currently mostly hype? The Alan Turing Institute, with expert guidance from the UK National Cyber Security Centre and Defence Science Technology Laboratory, published a research roadmap for AI for ACD last year. This position paper updates the roadmap for two of the most promising AI approaches -- reinforcement learning and causal inference - and describes why they could help tip the balance back towards defenders.
Inferring proximity from Bluetooth Low Energy RSSI with Unscented Kalman Smoothers
Jul 09, 2020
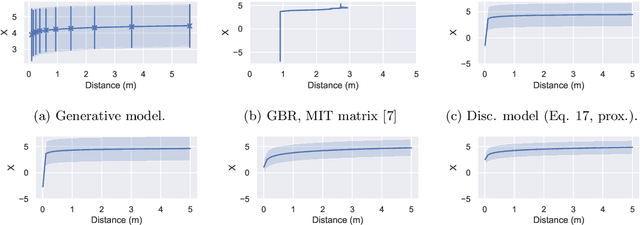
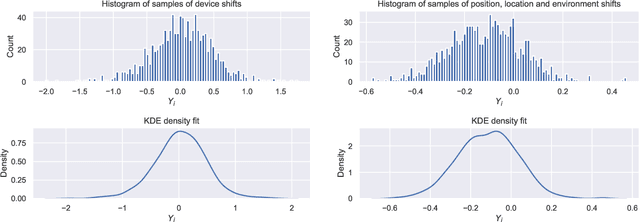
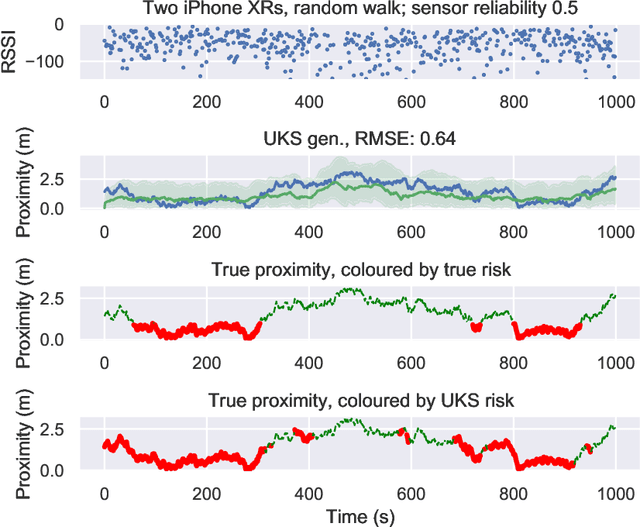
The Covid-19 pandemic has resulted in a variety of approaches for managing infection outbreaks in international populations. One example is mobile phone applications, which attempt to alert infected individuals and their contacts by automatically inferring two key components of infection risk: the proximity to an individual who may be infected, and the duration of proximity. The former component, proximity, relies on Bluetooth Low Energy (BLE) Received Signal Strength Indicator(RSSI) as a distance sensor, and this has been shown to be problematic; not least because of unpredictable variations caused by different device types, device location on-body, device orientation, the local environment and the general noise associated with radio frequency propagation. In this paper, we present an approach that infers posterior probabilities over distance given sequences of RSSI values. Using a single-dimensional Unscented Kalman Smoother (UKS) for non-linear state space modelling, we outline several Gaussian process observation transforms, including: a generative model that directly captures sources of variation; and a discriminative model that learns a suitable observation function from training data using both distance and infection risk as optimisation objective functions. Our results show that good risk prediction can be achieved in $\mathcal{O}(n)$ time on real-world data sets, with the UKS outperforming more traditional classification methods learned from the same training data.
Exploring Hyper-Parameter Optimization for Neural Machine Translation on GPU Architectures
May 05, 2018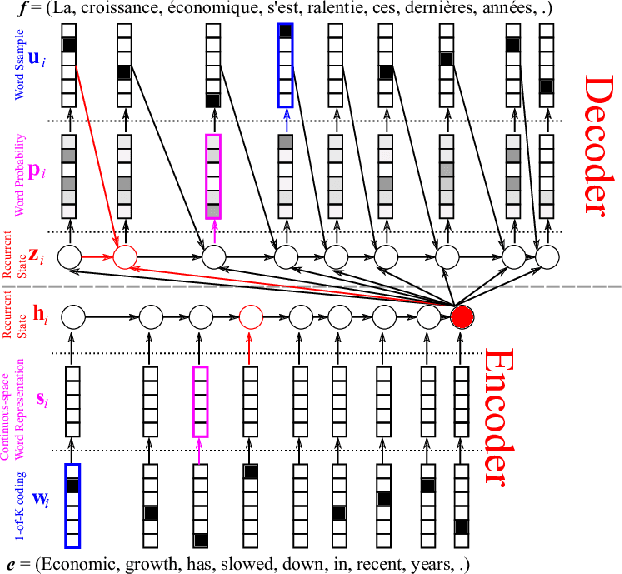
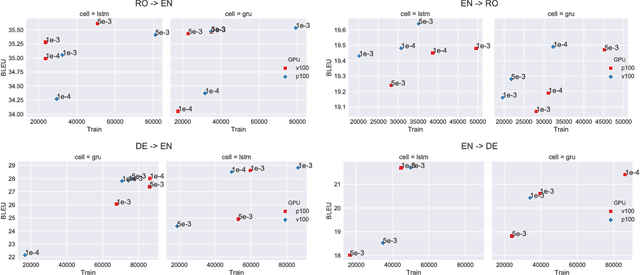
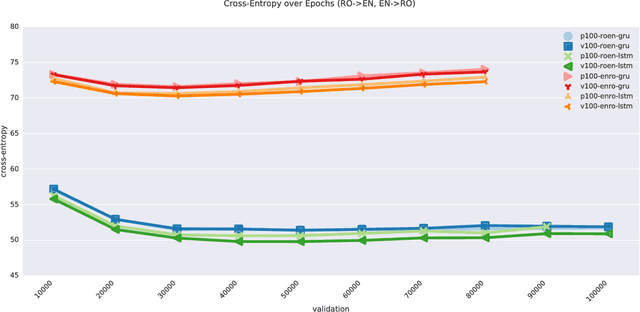
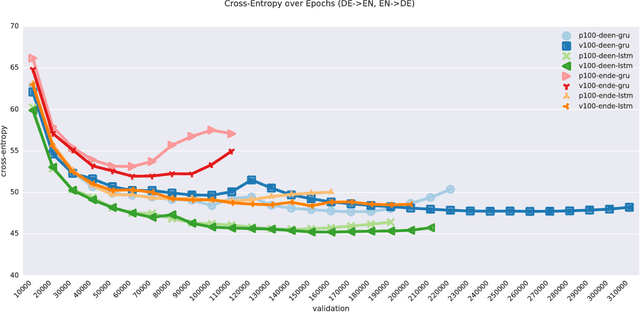
Neural machine translation (NMT) has been accelerated by deep learning neural networks over statistical-based approaches, due to the plethora and programmability of commodity heterogeneous computing architectures such as FPGAs and GPUs and the massive amount of training corpuses generated from news outlets, government agencies and social media. Training a learning classifier for neural networks entails tuning hyper-parameters that would yield the best performance. Unfortunately, the number of parameters for machine translation include discrete categories as well as continuous options, which makes for a combinatorial explosive problem. This research explores optimizing hyper-parameters when training deep learning neural networks for machine translation. Specifically, our work investigates training a language model with Marian NMT. Results compare NMT under various hyper-parameter settings across a variety of modern GPU architecture generations in single node and multi-node settings, revealing insights on which hyper-parameters matter most in terms of performance, such as words processed per second, convergence rates, and translation accuracy, and provides insights on how to best achieve high-performing NMT systems.