 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditional Distribution Compression via the Kernel Conditional Mean Embedding
Apr 14, 2025



Existing distribution compression methods, like Kernel Herding (KH), were originally developed for unlabelled data. However, no existing approach directly compresses the conditional distribution of labelled data. To address this gap, we first introduce the Average Maximum Conditional Mean Discrepancy (AMCMD), a natural metric for comparing conditional distributions. We then derive a consistent estimator for the AMCMD and establish its rate of convergence. Next, we make a key observation: in the context of distribution compression, the cost of constructing a compressed set targeting the AMCMD can be reduced from $\mathcal{O}(n^3)$ to $\mathcal{O}(n)$. Building on this, we extend the idea of KH to develop Average Conditional Kernel Herding (ACKH), a linear-time greedy algorithm that constructs a compressed set targeting the AMCMD. To better understand the advantages of directly compressing the conditional distribution rather than doing so via the joint distribution, we introduce Joint Kernel Herding (JKH), a straightforward adaptation of KH designed to compress the joint distribution of labelled data. While herding methods provide a simple and interpretable selection process, they rely on a greedy heuristic. To explore alternative optimisation strategies, we propose Joint Kernel Inducing Points (JKIP) and Average Conditional Kernel Inducing Points (ACKIP), which jointly optimise the compressed set while maintaining linear complexity. Experiments show that directly preserving conditional distributions with ACKIP outperforms both joint distribution compression (via JKH and JKIP) and the greedy selection used in ACKH. Moreover, we see that JKIP consistently outperforms JKH.
Inferring proximity from Bluetooth Low Energy RSSI with Unscented Kalman Smoothers
Jul 09, 2020
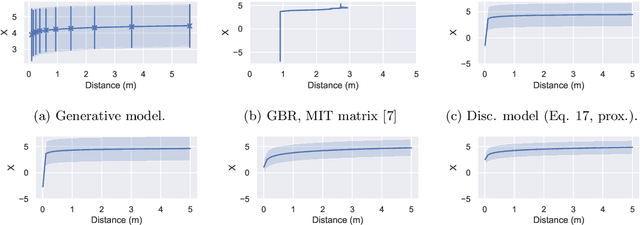
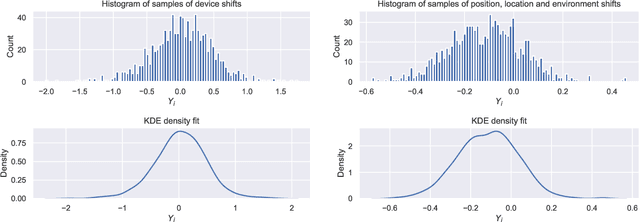
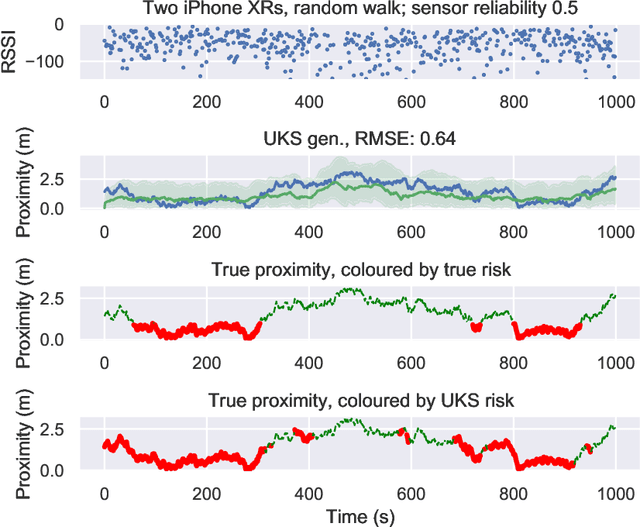
The Covid-19 pandemic has resulted in a variety of approaches for managing infection outbreaks in international populations. One example is mobile phone applications, which attempt to alert infected individuals and their contacts by automatically inferring two key components of infection risk: the proximity to an individual who may be infected, and the duration of proximity. The former component, proximity, relies on Bluetooth Low Energy (BLE) Received Signal Strength Indicator(RSSI) as a distance sensor, and this has been shown to be problematic; not least because of unpredictable variations caused by different device types, device location on-body, device orientation, the local environment and the general noise associated with radio frequency propagation. In this paper, we present an approach that infers posterior probabilities over distance given sequences of RSSI values. Using a single-dimensional Unscented Kalman Smoother (UKS) for non-linear state space modelling, we outline several Gaussian process observation transforms, including: a generative model that directly captures sources of variation; and a discriminative model that learns a suitable observation function from training data using both distance and infection risk as optimisation objective functions. Our results show that good risk prediction can be achieved in $\mathcal{O}(n)$ time on real-world data sets, with the UKS outperforming more traditional classification methods learned from the same training data.