 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProspective Artificial Intelligence Approaches for Active Cyber Defence
Apr 20, 2021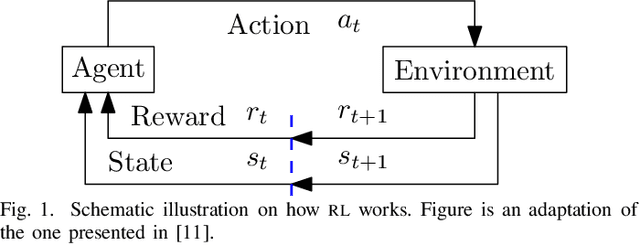
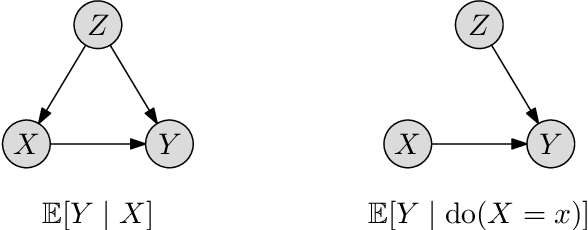
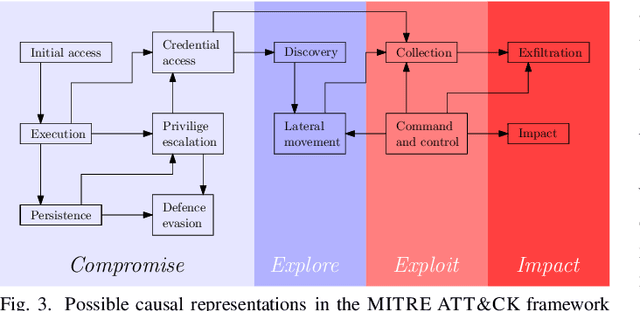
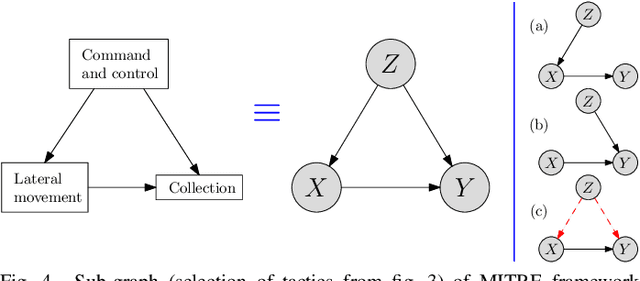
Cybercriminals are rapidly developing new malicious tools that leverage artificial intelligence (AI) to enable new classes of adaptive and stealthy attacks. New defensive methods need to be developed to counter these threats. Some cybersecurity professionals are speculating AI will enable corresponding new classes of active cyber defence measures -- is this realistic, or currently mostly hype? The Alan Turing Institute, with expert guidance from the UK National Cyber Security Centre and Defence Science Technology Laboratory, published a research roadmap for AI for ACD last year. This position paper updates the roadmap for two of the most promising AI approaches -- reinforcement learning and causal inference - and describes why they could help tip the balance back towards defenders.
On Adaptive Estimation for Dynamic Bernoulli Bandits
May 15, 2018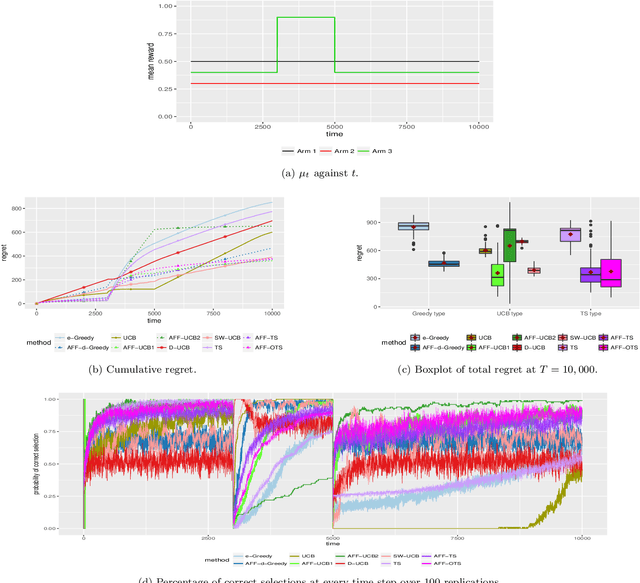

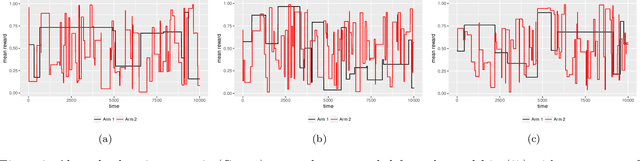
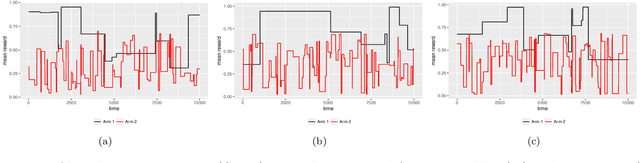
The multi-armed bandit (MAB) problem is a classic example of the exploration-exploitation dilemma. It is concerned with maximising the total rewards for a gambler by sequentially pulling an arm from a multi-armed slot machine where each arm is associated with a reward distribution. In static MABs, the reward distributions do not change over time, while in dynamic MABs, each arm's reward distribution can change, and the optimal arm can switch over time. Motivated by many real applications where rewards are binary, we focus on dynamic Bernoulli bandits. Standard methods like $\epsilon$-Greedy and Upper Confidence Bound (UCB), which rely on the sample mean estimator, often fail to track changes in the underlying reward for dynamic problems. In this paper, we overcome the shortcoming of slow response to change by deploying adaptive estimation in the standard methods and propose a new family of algorithms, which are adaptive versions of $\epsilon$-Greedy, UCB, and Thompson sampling. These new methods are simple and easy to implement. Moreover, they do not require any prior knowledge about the dynamic reward process, which is important for real applications. We examine the new algorithms numerically in different scenarios and the results show solid improvements of our algorithms in dynamic environments.