 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Defender Strategies for CAGE-2 using Causal Modeling and Tree Search
Jul 12, 2024The CAGE-2 challenge is considered a standard benchmark to compare methods for autonomous cyber defense. Current state-of-the-art methods evaluated against this benchmark are based on model-free (offline) reinforcement learning, which does not provide provably optimal defender strategies. We address this limitation and present a formal (causal) model of CAGE-2 together with a method that produces a provably optimal defender strategy, which we call Causal Partially Observable Monte-Carlo Planning (C-POMCP). It has two key properties. First, it incorporates the causal structure of the target system, i.e., the causal relationships among the system variables. This structure allows for a significant reduction of the search space of defender strategies. Second, it is an online method that updates the defender strategy at each time step via tree search. Evaluations against the CAGE-2 benchmark show that C-POMCP achieves state-of-the-art performance with respect to effectiveness and is two orders of magnitude more efficient in computing time than the closest competitor method.
Intrusion Tolerance for Networked Systems through Two-Level Feedback Control
Apr 02, 2024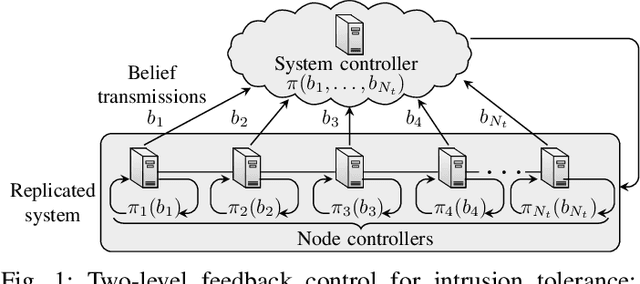

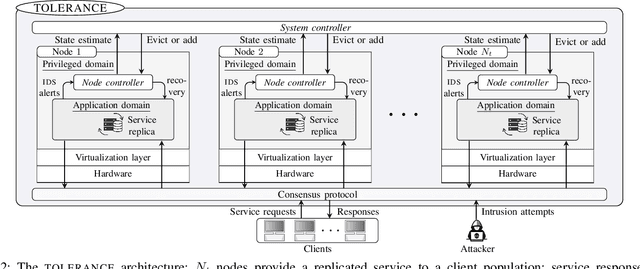
We formulate intrusion tolerance for a system with service replicas as a two-level optimal control problem. On the local level node controllers perform intrusion recovery, and on the global level a system controller manages the replication factor. The local and global control problems can be formulated as classical problems in operations research, namely, the machine replacement problem and the inventory replenishment problem. Based on this formulation, we design TOLERANCE, a novel control architecture for intrusion-tolerant systems. We prove that the optimal control strategies on both levels have threshold structure and design efficient algorithms for computing them. We implement and evaluate TOLERANCE in an emulation environment where we run 10 types of network intrusions. The results show that TOLERANCE can improve service availability and reduce operational cost compared with state-of-the-art intrusion-tolerant systems.
Conjectural Online Learning with First-order Beliefs in Asymmetric Information Stochastic Games
Mar 08, 2024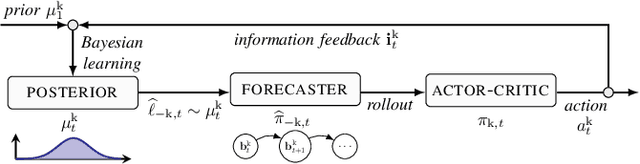

Asymmetric information stochastic games (\textsc{aisg}s) arise in many complex socio-technical systems, such as cyber-physical systems and IT infrastructures. Existing computational methods for \textsc{aisg}s are primarily offline and can not adapt to equilibrium deviations. Further, current methods are limited to special classes of \textsc{aisg}s to avoid belief hierarchies. To address these limitations, we propose conjectural online learning (\textsc{col}), an online method for generic \textsc{aisg}s. \textsc{col} uses a forecaster-actor-critic (\textsc{fac}) architecture where subjective forecasts are used to conjecture the opponents' strategies within a lookahead horizon, and Bayesian learning is used to calibrate the conjectures. To adapt strategies to nonstationary environments, \textsc{col} uses online rollout with cost function approximation (actor-critic). We prove that the conjectures produced by \textsc{col} are asymptotically consistent with the information feedback in the sense of a relaxed Bayesian consistency. We also prove that the empirical strategy profile induced by \textsc{col} converges to the Berk-Nash equilibrium, a solution concept characterizing rationality under subjectivity. Experimental results from an intrusion response use case demonstrate \textsc{col}'s superiority over state-of-the-art reinforcement learning methods against nonstationary attacks.
IT Intrusion Detection Using Statistical Learning and Testbed Measurements
Feb 20, 2024We study automated intrusion detection in an IT infrastructure, specifically the problem of identifying the start of an attack, the type of attack, and the sequence of actions an attacker takes, based on continuous measurements from the infrastructure. We apply statistical learning methods, including Hidden Markov Model (HMM), Long Short-Term Memory (LSTM), and Random Forest Classifier (RFC) to map sequences of observations to sequences of predicted attack actions. In contrast to most related research, we have abundant data to train the models and evaluate their predictive power. The data comes from traces we generate on an in-house testbed where we run attacks against an emulated IT infrastructure. Central to our work is a machine-learning pipeline that maps measurements from a high-dimensional observation space to a space of low dimensionality or to a small set of observation symbols. Investigating intrusions in offline as well as online scenarios, we find that both HMM and LSTM can be effective in predicting attack start time, attack type, and attack actions. If sufficient training data is available, LSTM achieves higher prediction accuracy than HMM. HMM, on the other hand, requires less computational resources and less training data for effective prediction. Also, we find that the methods we study benefit from data produced by traditional intrusion detection systems like SNORT.
Automated Security Response through Online Learning with Adaptive Conjectures
Feb 19, 2024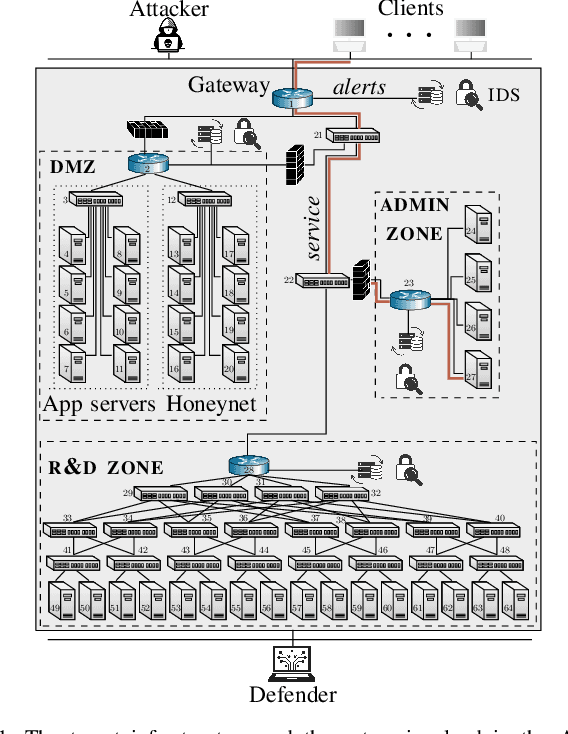

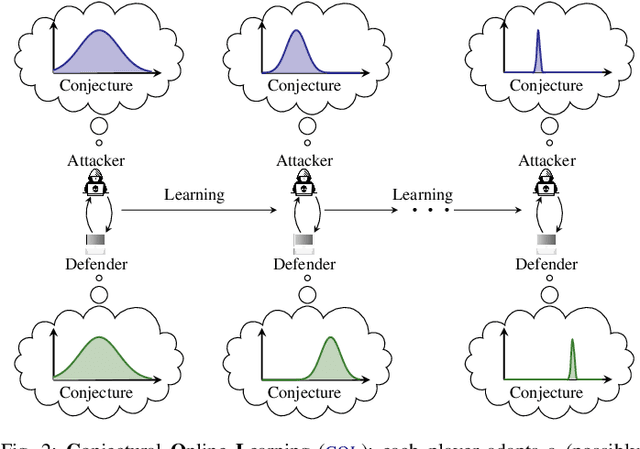
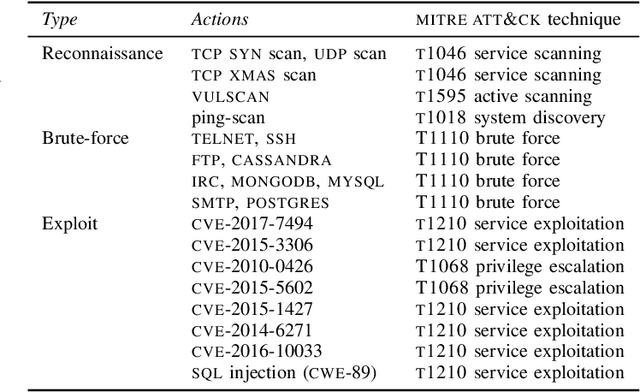
We study automated security response for an IT infrastructure and formulate the interaction between an attacker and a defender as a partially observed, non-stationary game. We relax the standard assumption that the game model is correctly specified and consider that each player has a probabilistic conjecture about the model, which may be misspecified in the sense that the true model has probability 0. This formulation allows us to capture uncertainty about the infrastructure and the intents of the players. To learn effective game strategies online, we design a novel method where a player iteratively adapts its conjecture using Bayesian learning and updates its strategy through rollout. We prove that the conjectures converge to best fits, and we provide a bound on the performance improvement that rollout enables with a conjectured model. To characterize the steady state of the game, we propose a variant of the Berk-Nash equilibrium. We present our method through an advanced persistent threat use case. Simulation studies based on testbed measurements show that our method produces effective security strategies that adapt to a changing environment. We also find that our method enables faster convergence than current reinforcement learning techniques.
Scalable Learning of Intrusion Responses through Recursive Decomposition
Sep 15, 2023We study automated intrusion response for an IT infrastructure and formulate the interaction between an attacker and a defender as a partially observed stochastic game. To solve the game we follow an approach where attack and defense strategies co-evolve through reinforcement learning and self-play toward an equilibrium. Solutions proposed in previous work prove the feasibility of this approach for small infrastructures but do not scale to realistic scenarios due to the exponential growth in computational complexity with the infrastructure size. We address this problem by introducing a method that recursively decomposes the game into subgames which can be solved in parallel. Applying optimal stopping theory we show that the best response strategies in these subgames exhibit threshold structures, which allows us to compute them efficiently. To solve the decomposed game we introduce an algorithm called Decompositional Fictitious Self-Play (DFSP), which learns Nash equilibria through stochastic approximation. We evaluate the learned strategies in an emulation environment where real intrusions and response actions can be executed. The results show that the learned strategies approximate an equilibrium and that DFSP significantly outperforms a state-of-the-art algorithm for a realistic infrastructure configuration.
A Framework for dynamically meeting performance objectives on a service mesh
Jun 25, 2023



We present a framework for achieving end-to-end management objectives for multiple services that concurrently execute on a service mesh. We apply reinforcement learning (RL) techniques to train an agent that periodically performs control actions to reallocate resources. We develop and evaluate the framework using a laboratory testbed where we run information and computing services on a service mesh, supported by the Istio and Kubernetes platforms. We investigate different management objectives that include end-to-end delay bounds on service requests, throughput objectives, cost-related objectives, and service differentiation. We compute the control policies on a simulator rather than on the testbed, which speeds up the training time by orders of magnitude for the scenarios we study. Our proposed framework is novel in that it advocates a top-down approach whereby the management objectives are defined first and then mapped onto the available control actions. It allows us to execute several types of control actions simultaneously. By first learning the system model and the operating region from testbed traces, we can train the agent for different management objectives in parallel.
Learning Near-Optimal Intrusion Responses Against Dynamic Attackers
Jan 11, 2023We study automated intrusion response and formulate the interaction between an attacker and a defender as an optimal stopping game where attack and defense strategies evolve through reinforcement learning and self-play. The game-theoretic modeling enables us to find defender strategies that are effective against a dynamic attacker, i.e. an attacker that adapts its strategy in response to the defender strategy. Further, the optimal stopping formulation allows us to prove that optimal strategies have threshold properties. To obtain near-optimal defender strategies, we develop Threshold Fictitious Self-Play (T-FP), a fictitious self-play algorithm that learns Nash equilibria through stochastic approximation. We show that T-FP outperforms a state-of-the-art algorithm for our use case. The experimental part of this investigation includes two systems: a simulation system where defender strategies are incrementally learned and an emulation system where statistics are collected that drive simulation runs and where learned strategies are evaluated. We argue that this approach can produce effective defender strategies for a practical IT infrastructure.
Dynamically meeting performance objectives for multiple services on a service mesh
Oct 08, 2022
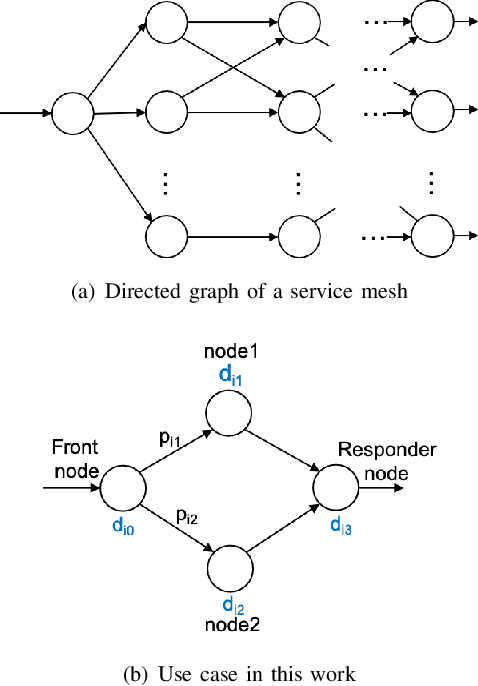
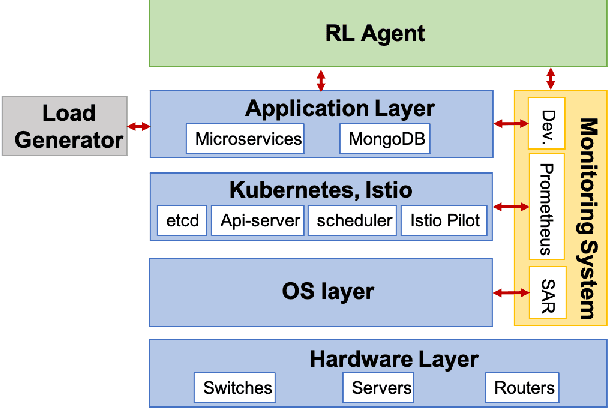
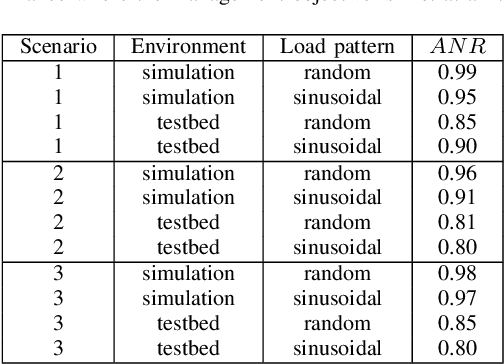
We present a framework that lets a service provider achieve end-to-end management objectives under varying load. Dynamic control actions are performed by a reinforcement learning (RL) agent. Our work includes experimentation and evaluation on a laboratory testbed where we have implemented basic information services on a service mesh supported by the Istio and Kubernetes platforms. We investigate different management objectives that include end-to-end delay bounds on service requests, throughput objectives, and service differentiation. These objectives are mapped onto reward functions that an RL agent learns to optimize, by executing control actions, namely, request routing and request blocking. We compute the control policies not on the testbed, but in a simulator, which speeds up the learning process by orders of magnitude. In our approach, the system model is learned on the testbed; it is then used to instantiate the simulator, which produces near-optimal control policies for various management objectives. The learned policies are then evaluated on the testbed using unseen load patterns.
Learning Security Strategies through Game Play and Optimal Stopping
May 29, 2022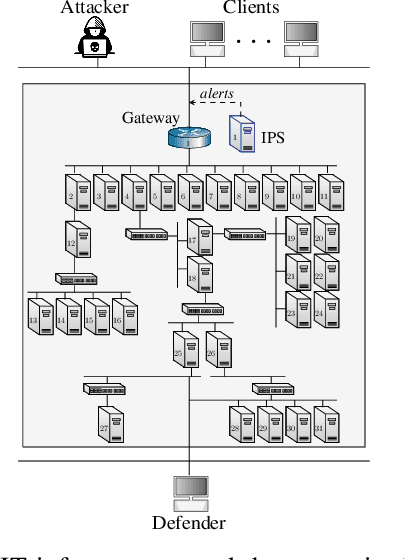

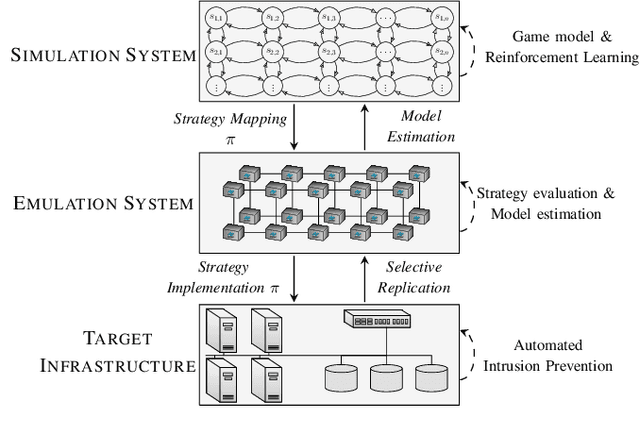

We study automated intrusion prevention using reinforcement learning. Following a novel approach, we formulate the interaction between an attacker and a defender as an optimal stopping game and let attack and defense strategies evolve through reinforcement learning and self-play. The game-theoretic perspective allows us to find defender strategies that are effective against dynamic attackers. The optimal stopping formulation gives us insight into the structure of optimal strategies, which we show to have threshold properties. To obtain the optimal defender strategies, we introduce T-FP, a fictitious self-play algorithm that learns Nash equilibria through stochastic approximation. We show that T-FP outperforms a state-of-the-art algorithm for our use case. Our overall method for learning and evaluating strategies includes two systems: a simulation system where defender strategies are incrementally learned and an emulation system where statistics are produced that drive simulation runs and where learned strategies are evaluated. We conclude that this approach can produce effective defender strategies for a practical IT infrastructure.