 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Framework for dynamically meeting performance objectives on a service mesh
Jun 25, 2023



We present a framework for achieving end-to-end management objectives for multiple services that concurrently execute on a service mesh. We apply reinforcement learning (RL) techniques to train an agent that periodically performs control actions to reallocate resources. We develop and evaluate the framework using a laboratory testbed where we run information and computing services on a service mesh, supported by the Istio and Kubernetes platforms. We investigate different management objectives that include end-to-end delay bounds on service requests, throughput objectives, cost-related objectives, and service differentiation. We compute the control policies on a simulator rather than on the testbed, which speeds up the training time by orders of magnitude for the scenarios we study. Our proposed framework is novel in that it advocates a top-down approach whereby the management objectives are defined first and then mapped onto the available control actions. It allows us to execute several types of control actions simultaneously. By first learning the system model and the operating region from testbed traces, we can train the agent for different management objectives in parallel.
Dynamically meeting performance objectives for multiple services on a service mesh
Oct 08, 2022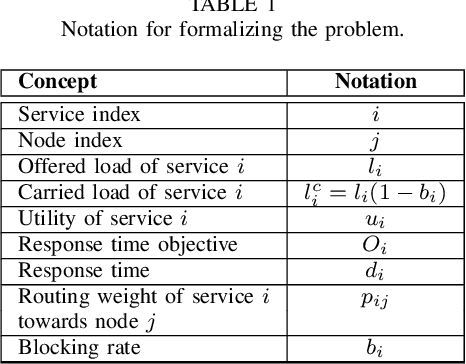
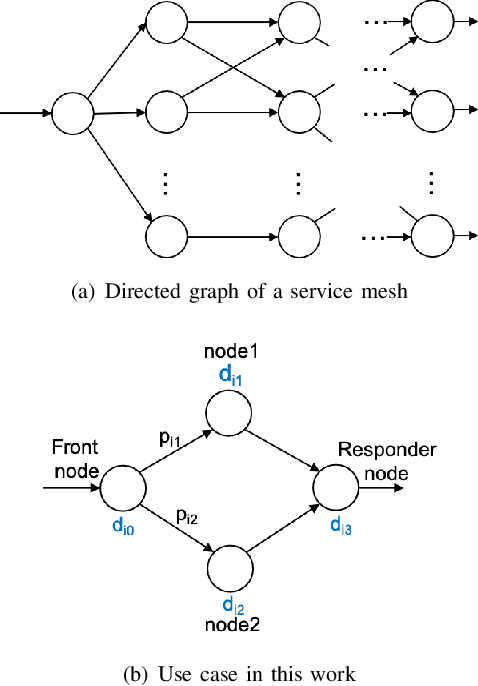
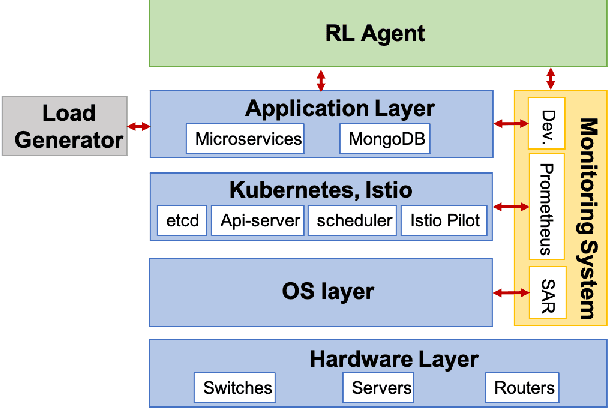
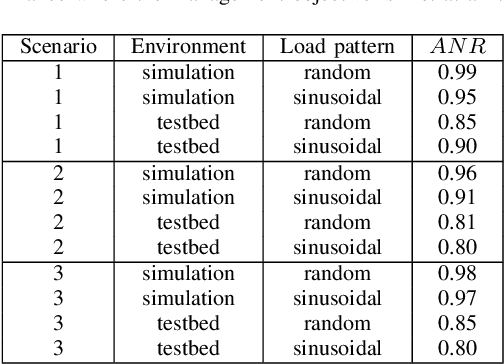
We present a framework that lets a service provider achieve end-to-end management objectives under varying load. Dynamic control actions are performed by a reinforcement learning (RL) agent. Our work includes experimentation and evaluation on a laboratory testbed where we have implemented basic information services on a service mesh supported by the Istio and Kubernetes platforms. We investigate different management objectives that include end-to-end delay bounds on service requests, throughput objectives, and service differentiation. These objectives are mapped onto reward functions that an RL agent learns to optimize, by executing control actions, namely, request routing and request blocking. We compute the control policies not on the testbed, but in a simulator, which speeds up the learning process by orders of magnitude. In our approach, the system model is learned on the testbed; it is then used to instantiate the simulator, which produces near-optimal control policies for various management objectives. The learned policies are then evaluated on the testbed using unseen load patterns.
Online feature selection for rapid, low-overhead learning in networked systems
Oct 28, 2020
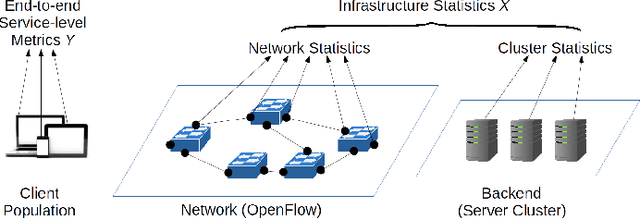
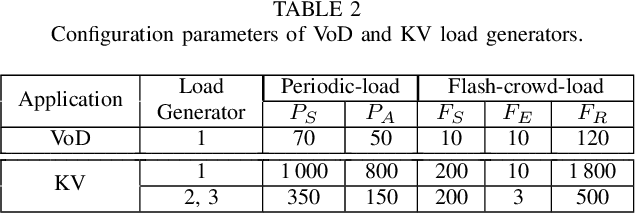

Data-driven functions for operation and management often require measurements collected through monitoring for model training and prediction. The number of data sources can be very large, which requires a significant communication and computing overhead to continuously extract and collect this data, as well as to train and update the machine-learning models. We present an online algorithm, called OSFS, that selects a small feature set from a large number of available data sources, which allows for rapid, low-overhead, and effective learning and prediction. OSFS is instantiated with a feature ranking algorithm and applies the concept of a stable feature set, which we introduce in the paper. We perform extensive, experimental evaluation of our method on data from an in-house testbed. We find that OSFS requires several hundreds measurements to reduce the number of data sources by two orders of magnitude, from which models are trained with acceptable prediction accuracy. While our method is heuristic and can be improved in many ways, the results clearly suggests that many learning tasks do not require a lengthy monitoring phase and expensive offline training.