 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHide-and-Seek Privacy Challenge
Jul 24, 2020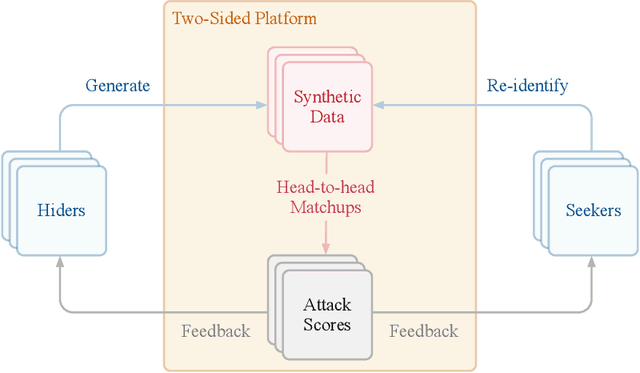
The clinical time-series setting poses a unique combination of challenges to data modeling and sharing. Due to the high dimensionality of clinical time series, adequate de-identification to preserve privacy while retaining data utility is difficult to achieve using common de-identification techniques. An innovative approach to this problem is synthetic data generation. From a technical perspective, a good generative model for time-series data should preserve temporal dynamics, in the sense that new sequences respect the original relationships between high-dimensional variables across time. From the privacy perspective, the model should prevent patient re-identification by limiting vulnerability to membership inference attacks. The NeurIPS 2020 Hide-and-Seek Privacy Challenge is a novel two-tracked competition to simultaneously accelerate progress in tackling both problems. In our head-to-head format, participants in the synthetic data generation track (i.e. "hiders") and the patient re-identification track (i.e. "seekers") are directly pitted against each other by way of a new, high-quality intensive care time-series dataset: the AmsterdamUMCdb dataset. Ultimately, we seek to advance generative techniques for dense and high-dimensional temporal data streams that are (1) clinically meaningful in terms of fidelity and predictivity, as well as (2) capable of minimizing membership privacy risks in terms of the concrete notion of patient re-identification.
TextWorld: A Learning Environment for Text-based Games
Jun 29, 2018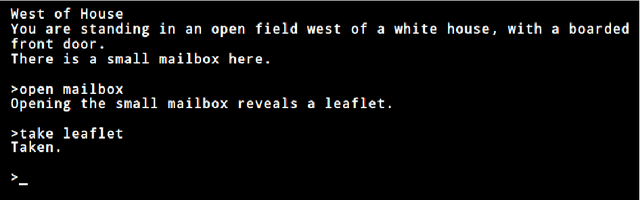

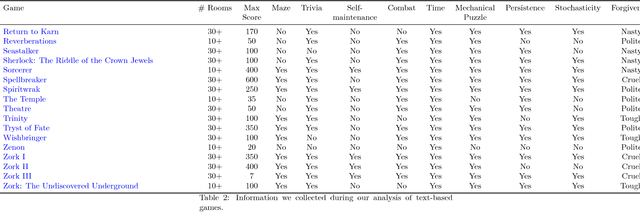
We introduce TextWorld, a sandbox learning environment for the training and evaluation of RL agents on text-based games. TextWorld is a Python library that handles interactive play-through of text games, as well as backend functions like state tracking and reward assignment. It comes with a curated list of games whose features and challenges we have analyzed. More significantly, it enables users to handcraft or automatically generate new games. Its generative mechanisms give precise control over the difficulty, scope, and language of constructed games, and can be used to relax challenges inherent to commercial text games like partial observability and sparse rewards. By generating sets of varied but similar games, TextWorld can also be used to study generalization and transfer learning. We cast text-based games in the Reinforcement Learning formalism, use our framework to develop a set of benchmark games, and evaluate several baseline agents on this set and the curated list.
Hybrid Reward Architecture for Reinforcement Learning
Nov 28, 2017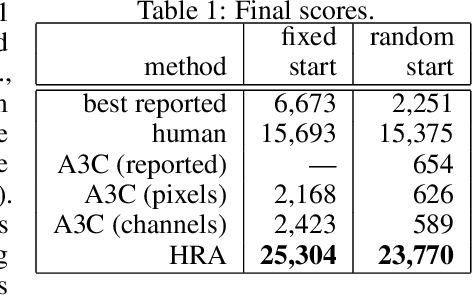
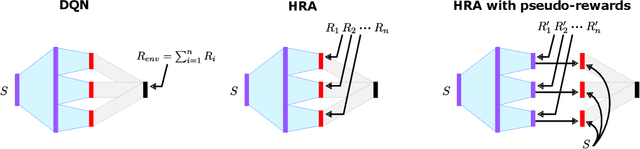
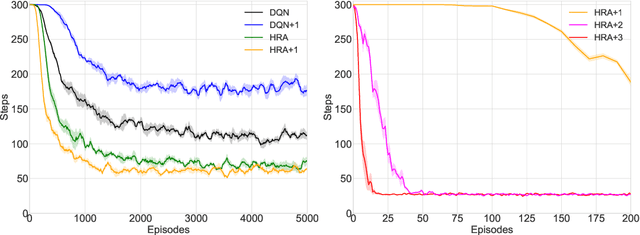
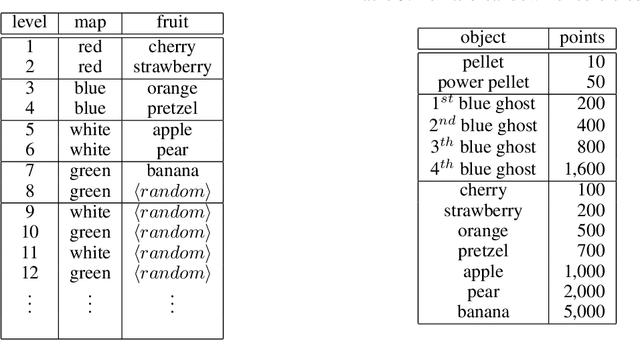
One of the main challenges in reinforcement learning (RL) is generalisation. In typical deep RL methods this is achieved by approximating the optimal value function with a low-dimensional representation using a deep network. While this approach works well in many domains, in domains where the optimal value function cannot easily be reduced to a low-dimensional representation, learning can be very slow and unstable. This paper contributes towards tackling such challenging domains, by proposing a new method, called Hybrid Reward Architecture (HRA). HRA takes as input a decomposed reward function and learns a separate value function for each component reward function. Because each component typically only depends on a subset of all features, the corresponding value function can be approximated more easily by a low-dimensional representation, enabling more effective learning. We demonstrate HRA on a toy-problem and the Atari game Ms. Pac-Man, where HRA achieves above-human performance.