 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombining Spatial and Temporal Abstraction in Planning for Better Generalization
Sep 30, 2023
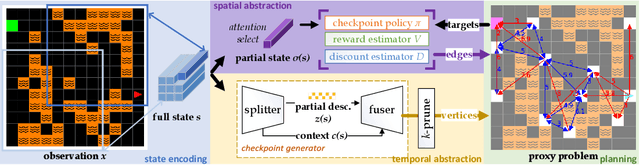
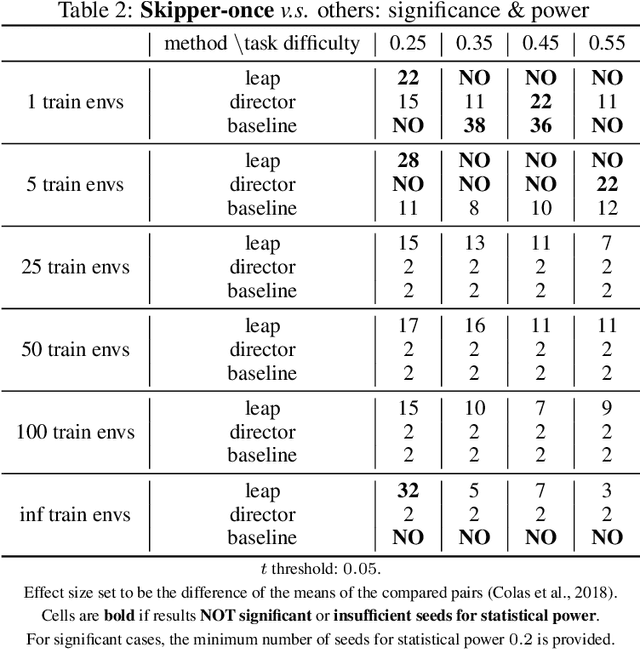
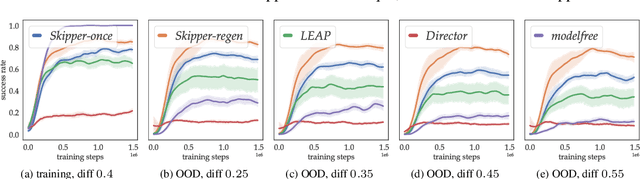
Inspired by human conscious planning, we propose Skipper, a model-based reinforcement learning agent that utilizes spatial and temporal abstractions to generalize learned skills in novel situations. It automatically decomposes the task at hand into smaller-scale, more manageable subtasks and hence enables sparse decision-making and focuses its computation on the relevant parts of the environment. This relies on the definition of a high-level proxy problem represented as a directed graph, in which vertices and edges are learned end-to-end using hindsight. Our theoretical analyses provide performance guarantees under appropriate assumptions and establish where our approach is expected to be helpful. Generalization-focused experiments validate Skipper's significant advantage in zero-shot generalization, compared to existing state-of-the-art hierarchical planning methods.
Replay Buffer With Local Forgetting for Adaptive Deep Model-Based Reinforcement Learning
Mar 15, 2023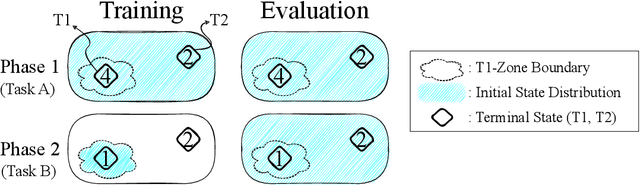
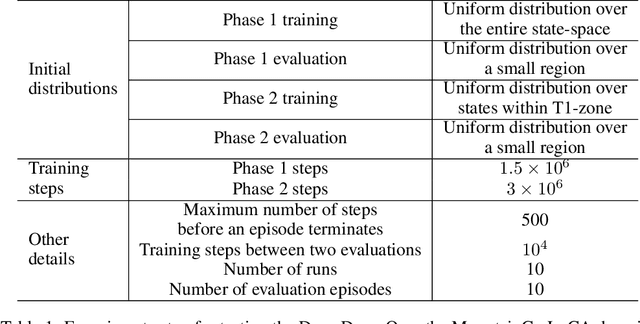
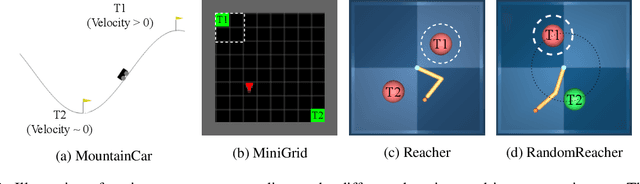
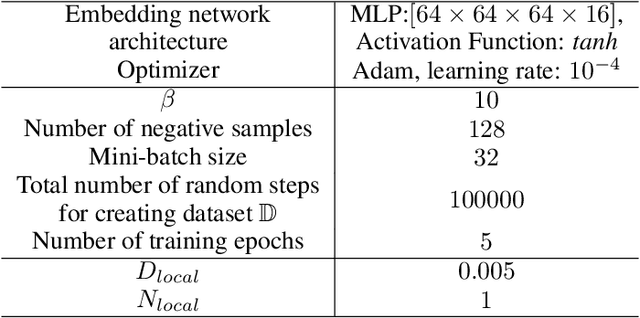
One of the key behavioral characteristics used in neuroscience to determine whether the subject of study -- be it a rodent or a human -- exhibits model-based learning is effective adaptation to local changes in the environment. In reinforcement learning, however, recent work has shown that modern deep model-based reinforcement-learning (MBRL) methods adapt poorly to such changes. An explanation for this mismatch is that MBRL methods are typically designed with sample-efficiency on a single task in mind and the requirements for effective adaptation are substantially higher, both in terms of the learned world model and the planning routine. One particularly challenging requirement is that the learned world model has to be sufficiently accurate throughout relevant parts of the state-space. This is challenging for deep-learning-based world models due to catastrophic forgetting. And while a replay buffer can mitigate the effects of catastrophic forgetting, the traditional first-in-first-out replay buffer precludes effective adaptation due to maintaining stale data. In this work, we show that a conceptually simple variation of this traditional replay buffer is able to overcome this limitation. By removing only samples from the buffer from the local neighbourhood of the newly observed samples, deep world models can be built that maintain their accuracy across the state-space, while also being able to effectively adapt to changes in the reward function. We demonstrate this by applying our replay-buffer variation to a deep version of the classical Dyna method, as well as to recent methods such as PlaNet and DreamerV2, demonstrating that deep model-based methods can adapt effectively as well to local changes in the environment.
Agent-Controller Representations: Principled Offline RL with Rich Exogenous Information
Oct 31, 2022Learning to control an agent from data collected offline in a rich pixel-based visual observation space is vital for real-world applications of reinforcement learning (RL). A major challenge in this setting is the presence of input information that is hard to model and irrelevant to controlling the agent. This problem has been approached by the theoretical RL community through the lens of exogenous information, i.e, any control-irrelevant information contained in observations. For example, a robot navigating in busy streets needs to ignore irrelevant information, such as other people walking in the background, textures of objects, or birds in the sky. In this paper, we focus on the setting with visually detailed exogenous information, and introduce new offline RL benchmarks offering the ability to study this problem. We find that contemporary representation learning techniques can fail on datasets where the noise is a complex and time dependent process, which is prevalent in practical applications. To address these, we propose to use multi-step inverse models, which have seen a great deal of interest in the RL theory community, to learn Agent-Controller Representations for Offline-RL (ACRO). Despite being simple and requiring no reward, we show theoretically and empirically that the representation created by this objective greatly outperforms baselines.
Modular Lifelong Reinforcement Learning via Neural Composition
Jul 01, 2022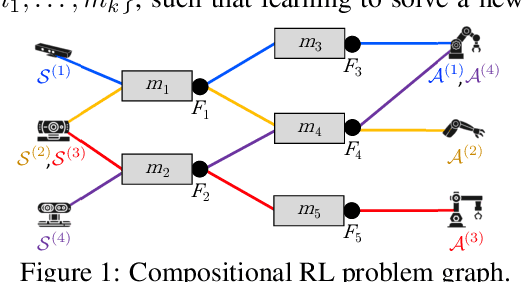
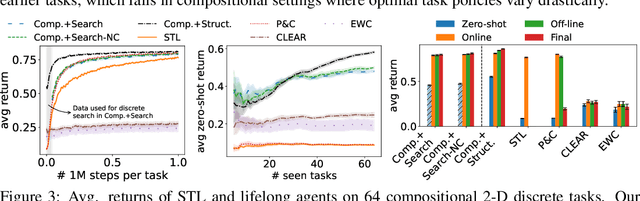
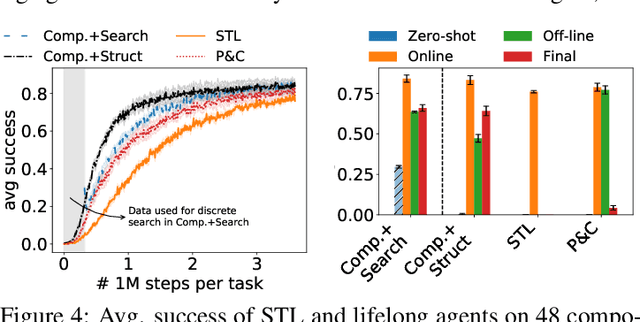

Humans commonly solve complex problems by decomposing them into easier subproblems and then combining the subproblem solutions. This type of compositional reasoning permits reuse of the subproblem solutions when tackling future tasks that share part of the underlying compositional structure. In a continual or lifelong reinforcement learning (RL) setting, this ability to decompose knowledge into reusable components would enable agents to quickly learn new RL tasks by leveraging accumulated compositional structures. We explore a particular form of composition based on neural modules and present a set of RL problems that intuitively admit compositional solutions. Empirically, we demonstrate that neural composition indeed captures the underlying structure of this space of problems. We further propose a compositional lifelong RL method that leverages accumulated neural components to accelerate the learning of future tasks while retaining performance on previous tasks via off-line RL over replayed experiences.
Towards Evaluating Adaptivity of Model-Based Reinforcement Learning Methods
Apr 25, 2022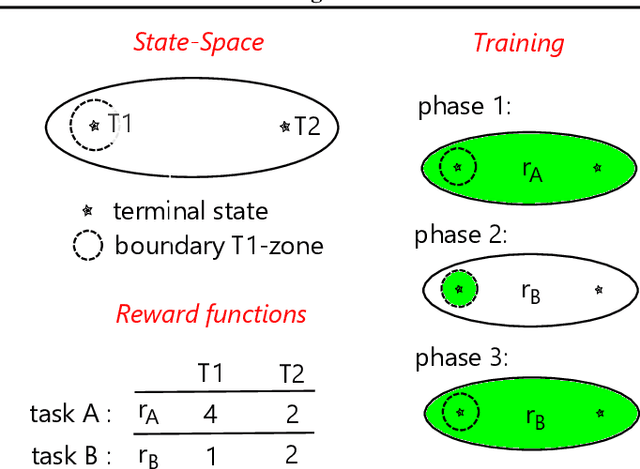

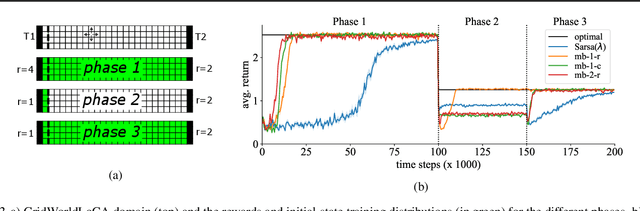
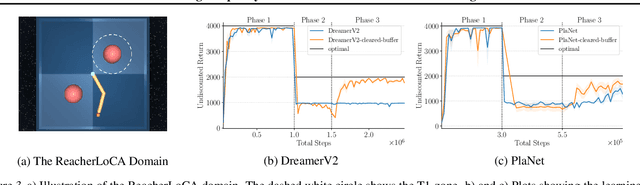
In recent years, a growing number of deep model-based reinforcement learning (RL) methods have been introduced. The interest in deep model-based RL is not surprising, given its many potential benefits, such as higher sample efficiency and the potential for fast adaption to changes in the environment. However, we demonstrate, using an improved version of the recently introduced Local Change Adaptation (LoCA) setup, that well-known model-based methods such as PlaNet and DreamerV2 perform poorly in their ability to adapt to local environmental changes. Combined with prior work that made a similar observation about the other popular model-based method, MuZero, a trend appears to emerge, suggesting that current deep model-based methods have serious limitations. We dive deeper into the causes of this poor performance, by identifying elements that hurt adaptive behavior and linking these to underlying techniques frequently used in deep model-based RL. We empirically validate these insights in the case of linear function approximation by demonstrating that a modified version of linear Dyna achieves effective adaptation to local changes. Furthermore, we provide detailed insights into the challenges of building an adaptive nonlinear model-based method, by experimenting with a nonlinear version of Dyna.
Shortest-Path Constrained Reinforcement Learning for Sparse Reward Tasks
Jul 13, 2021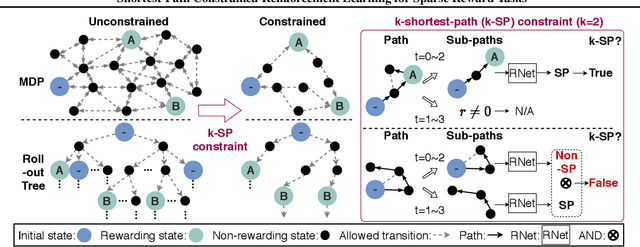
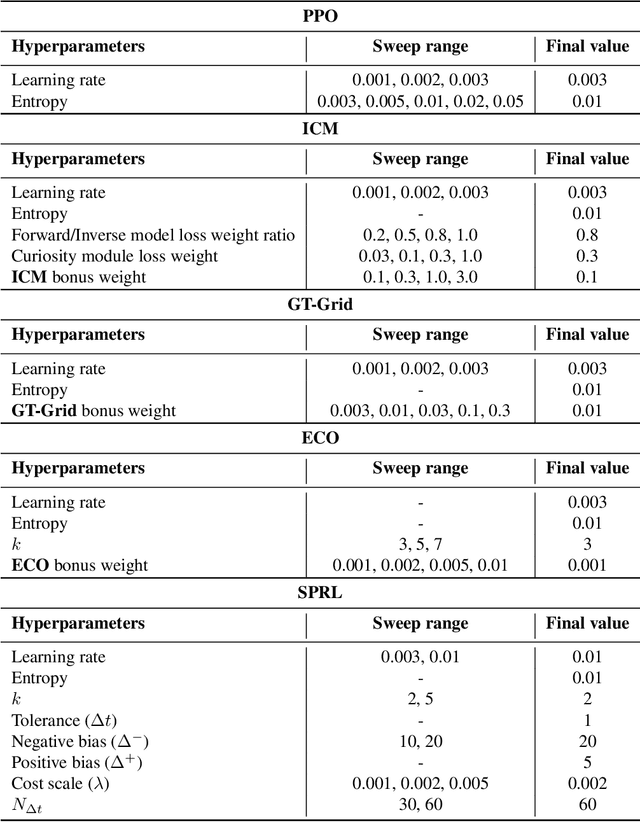

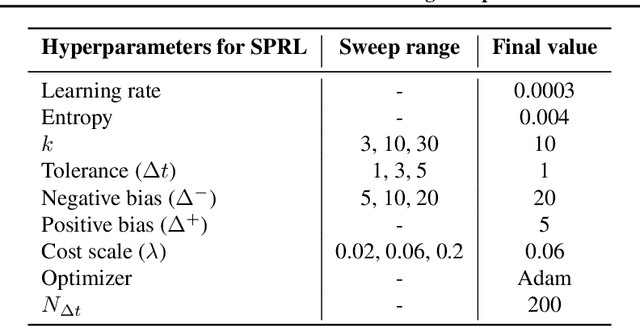
We propose the k-Shortest-Path (k-SP) constraint: a novel constraint on the agent's trajectory that improves the sample efficiency in sparse-reward MDPs. We show that any optimal policy necessarily satisfies the k-SP constraint. Notably, the k-SP constraint prevents the policy from exploring state-action pairs along the non-k-SP trajectories (e.g., going back and forth). However, in practice, excluding state-action pairs may hinder the convergence of RL algorithms. To overcome this, we propose a novel cost function that penalizes the policy violating SP constraint, instead of completely excluding it. Our numerical experiment in a tabular RL setting demonstrates that the SP constraint can significantly reduce the trajectory space of policy. As a result, our constraint enables more sample efficient learning by suppressing redundant exploration and exploitation. Our experiments on MiniGrid, DeepMind Lab, Atari, and Fetch show that the proposed method significantly improves proximal policy optimization (PPO) and outperforms existing novelty-seeking exploration methods including count-based exploration even in continuous control tasks, indicating that it improves the sample efficiency by preventing the agent from taking redundant actions.
A Deeper Look at Discounting Mismatch in Actor-Critic Algorithms
Oct 02, 2020
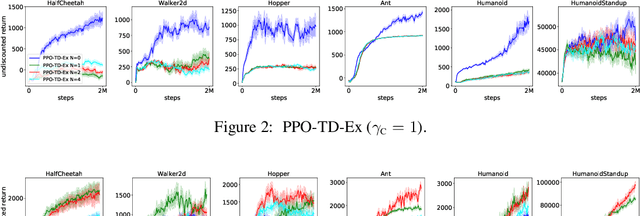
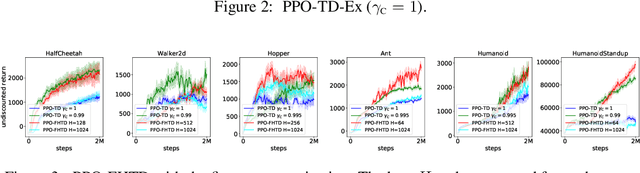

We investigate the discounting mismatch in actor-critic algorithm implementations from a representation learning perspective. Theoretically, actor-critic algorithms usually have discounting for both actor and critic, i.e., there is a $\gamma^t$ term in the actor update for the transition observed at time $t$ in a trajectory and the critic is a discounted value function. Practitioners, however, usually ignore the discounting ($\gamma^t$) for the actor while using a discounted critic. We investigate this mismatch in two scenarios. In the first scenario, we consider optimizing an undiscounted objective $(\gamma = 1)$ where $\gamma^t$ disappears naturally $(1^t = 1)$. We then propose to interpret the discounting in critic in terms of a bias-variance-representation trade-off and provide supporting empirical results. In the second scenario, we consider optimizing a discounted objective ($\gamma < 1$) and propose to interpret the omission of the discounting in the actor update from an auxiliary task perspective and provide supporting empirical results.
The LoCA Regret: A Consistent Metric to Evaluate Model-Based Behavior in Reinforcement Learning
Jul 07, 2020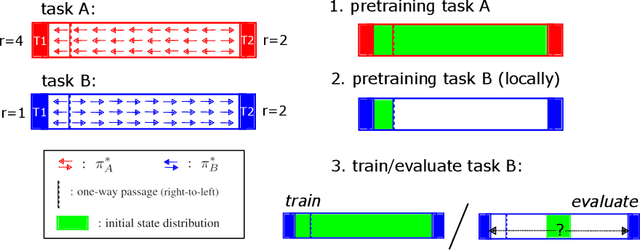
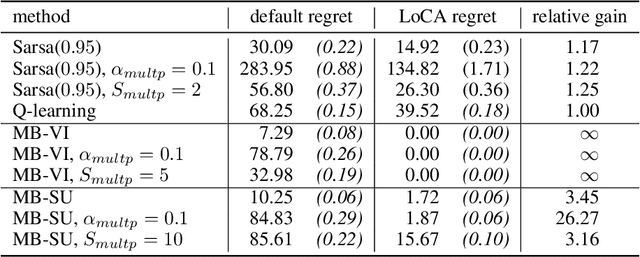
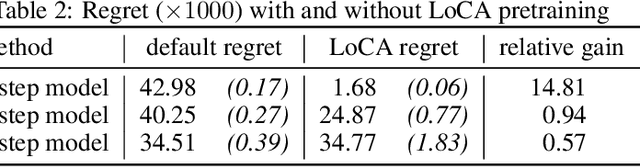

Deep model-based Reinforcement Learning (RL) has the potential to substantially improve the sample-efficiency of deep RL. While various challenges have long held it back, a number of papers have recently come out reporting success with deep model-based methods. This is a great development, but the lack of a consistent metric to evaluate such methods makes it difficult to compare various approaches. For example, the common single-task sample-efficiency metric conflates improvements due to model-based learning with various other aspects, such as representation learning, making it difficult to assess true progress on model-based RL. To address this, we introduce an experimental setup to evaluate model-based behavior of RL methods, inspired by work from neuroscience on detecting model-based behavior in humans and animals. Our metric based on this setup, the Local Change Adaptation (LoCA) regret, measures how quickly an RL method adapts to a local change in the environment. Our metric can identify model-based behavior, even if the method uses a poor representation and provides insight in how close a method's behavior is from optimal model-based behavior. We use our setup to evaluate the model-based behavior of MuZero on a variation of the classic Mountain Car task.
Using a Logarithmic Mapping to Enable Lower Discount Factors in Reinforcement Learning
Jun 03, 2019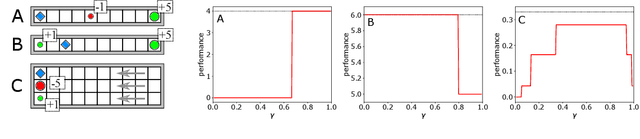

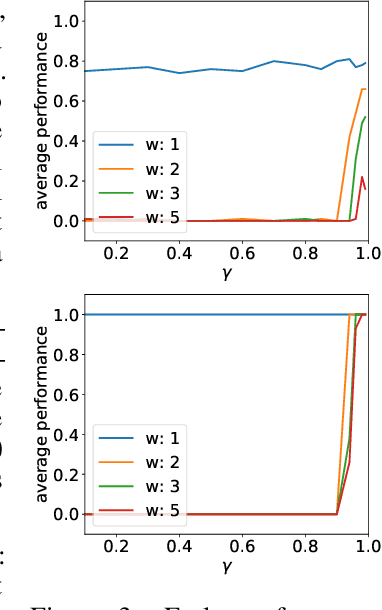
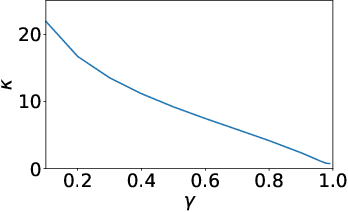
In an effort to better understand the different ways in which the discount factor affects the optimization process in reinforcement learning, we designed a set of experiments to study each effect in isolation. Our analysis reveals that the common perception that poor performance of low discount factors is caused by (too) small action-gaps requires revision. We propose an alternative hypothesis, which identifies the size-difference of the action-gap across the state-space as the primary cause. We then introduce a new method that enables more homogeneous action-gaps by mapping value estimates to a logarithmic space. We prove convergence for this method under standard assumptions and demonstrate empirically that it indeed enables lower discount factors for approximate reinforcement-learning methods. This in turn allows tackling a class of reinforcement-learning problems that are challenging to solve with traditional methods.
Learning Invariances for Policy Generalization
Sep 07, 2018
While recent progress has spawned very powerful machine learning systems, those agents remain extremely specialized and fail to transfer the knowledge they gain to similar yet unseen tasks. In this paper, we study a simple reinforcement learning problem and focus on learning policies that encode the proper invariances for generalization to different settings. We evaluate three potential methods for policy generalization: data augmentation, meta-learning and adversarial training. We find our data augmentation method to be effective, and study the potential of meta-learning and adversarial learning as alternative task-agnostic approaches. Keywords: reinforcement learning, generalization, data augmentation, meta-learning, adversarial learning.