 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShortest-Path Constrained Reinforcement Learning for Sparse Reward Tasks
Jul 13, 2021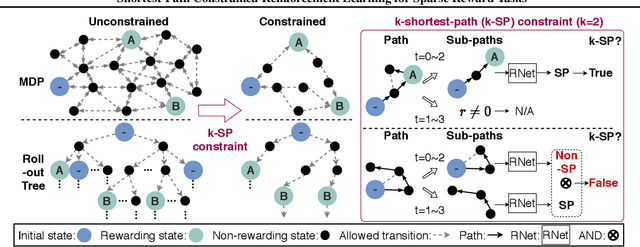
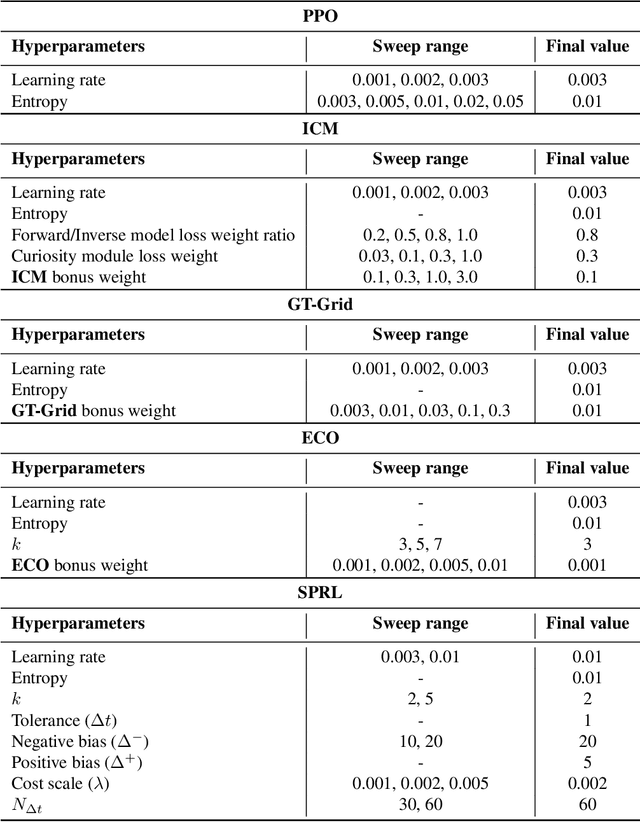

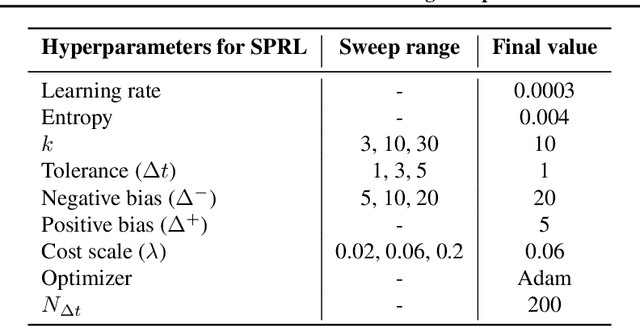
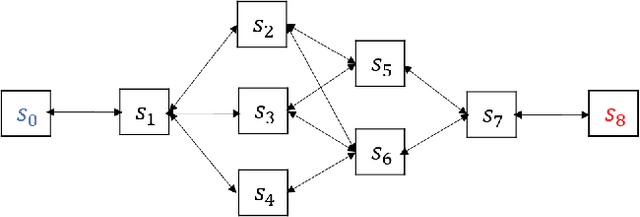
We propose the k-Shortest-Path (k-SP) constraint: a novel constraint on the agent's trajectory that improves the sample efficiency in sparse-reward MDPs. We show that any optimal policy necessarily satisfies the k-SP constraint. Notably, the k-SP constraint prevents the policy from exploring state-action pairs along the non-k-SP trajectories (e.g., going back and forth). However, in practice, excluding state-action pairs may hinder the convergence of RL algorithms. To overcome this, we propose a novel cost function that penalizes the policy violating SP constraint, instead of completely excluding it. Our numerical experiment in a tabular RL setting demonstrates that the SP constraint can significantly reduce the trajectory space of policy. As a result, our constraint enables more sample efficient learning by suppressing redundant exploration and exploitation. Our experiments on MiniGrid, DeepMind Lab, Atari, and Fetch show that the proposed method significantly improves proximal policy optimization (PPO) and outperforms existing novelty-seeking exploration methods including count-based exploration even in continuous control tasks, indicating that it improves the sample efficiency by preventing the agent from taking redundant actions.
Adaptive Learning Rule for Hardware-based Deep Neural Networks Using Electronic Synapse Devices
Aug 19, 2017
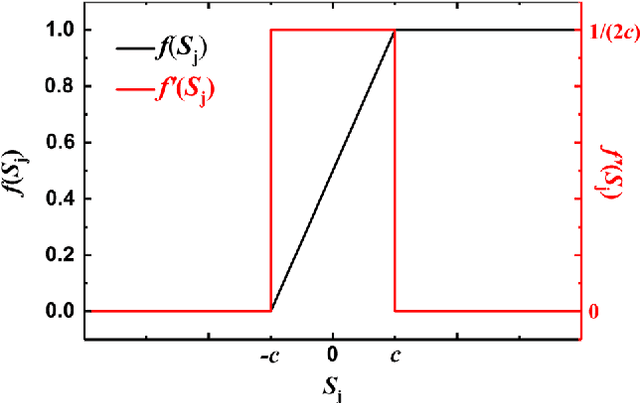
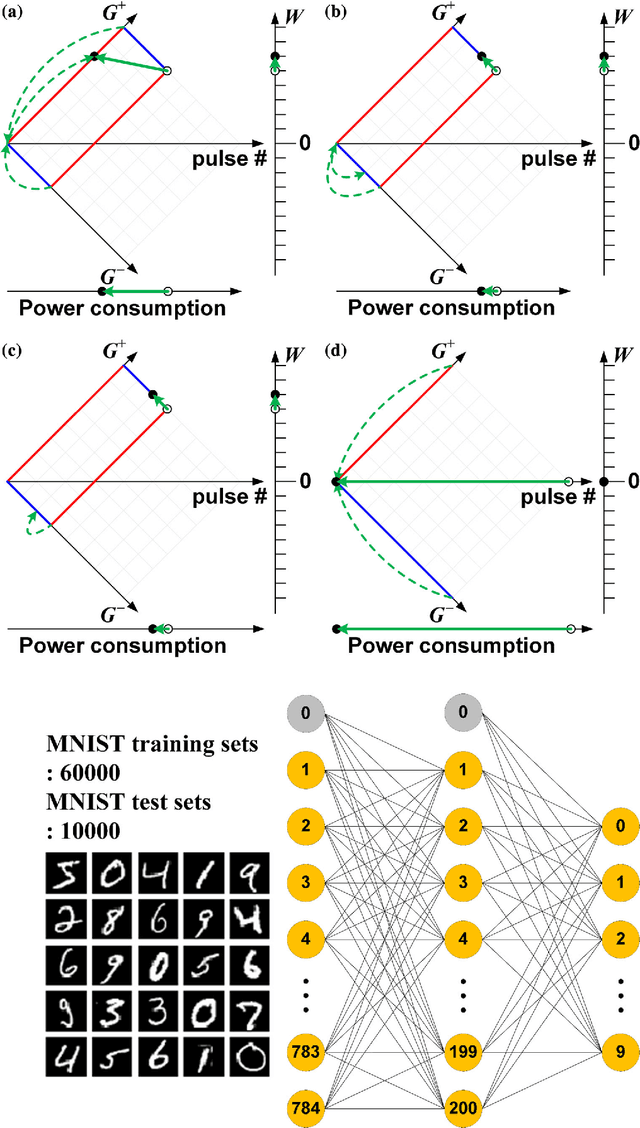
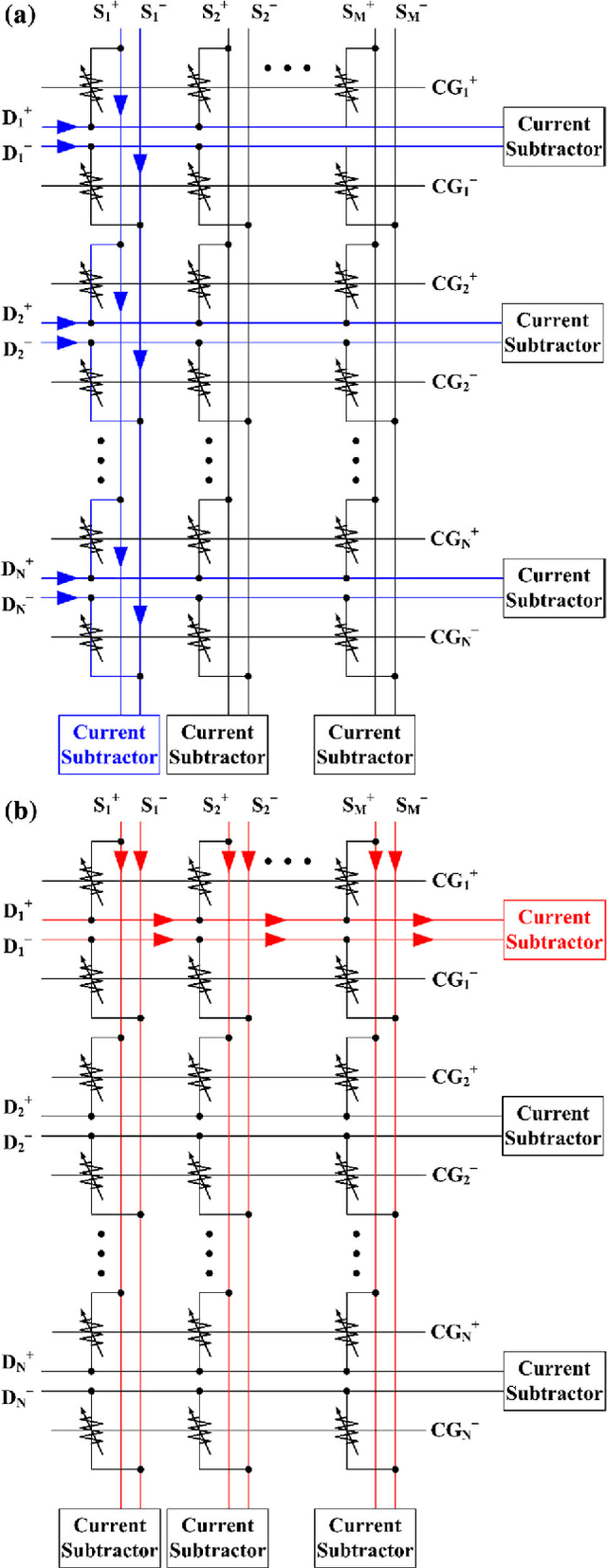
In this paper, we propose a learning rule based on a back-propagation (BP) algorithm that can be applied to a hardware-based deep neural network (HW-DNN) using electronic devices that exhibit discrete and limited conductance characteristics. This adaptive learning rule, which enables forward, backward propagation, as well as weight updates in hardware, is helpful during the implementation of power-efficient and high-speed deep neural networks. In simulations using a three-layer perceptron network, we evaluate the learning performance according to various conductance responses of electronic synapse devices and weight-updating methods. It is shown that the learning accuracy is comparable to that obtained when using a software-based BP algorithm when the electronic synapse device has a linear conductance response with a high dynamic range. Furthermore, the proposed unidirectional weight-updating method is suitable for electronic synapse devices which have nonlinear and finite conductance responses. Because this weight-updating method can compensate the demerit of asymmetric weight updates, we can obtain better accuracy compared to other methods. This adaptive learning rule, which can be applied to full hardware implementation, can also compensate the degradation of learning accuracy due to the probable device-to-device variation in an actual electronic synapse device.
Micro-Objective Learning : Accelerating Deep Reinforcement Learning through the Discovery of Continuous Subgoals
Mar 11, 2017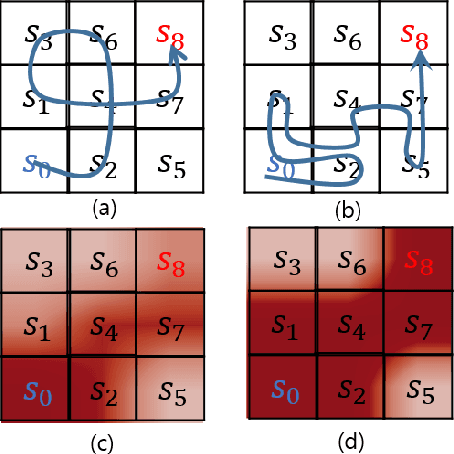
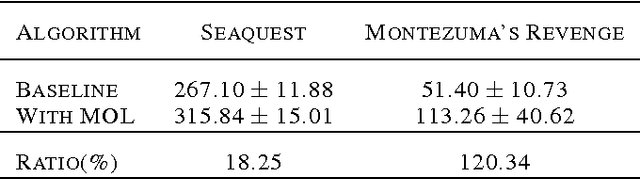
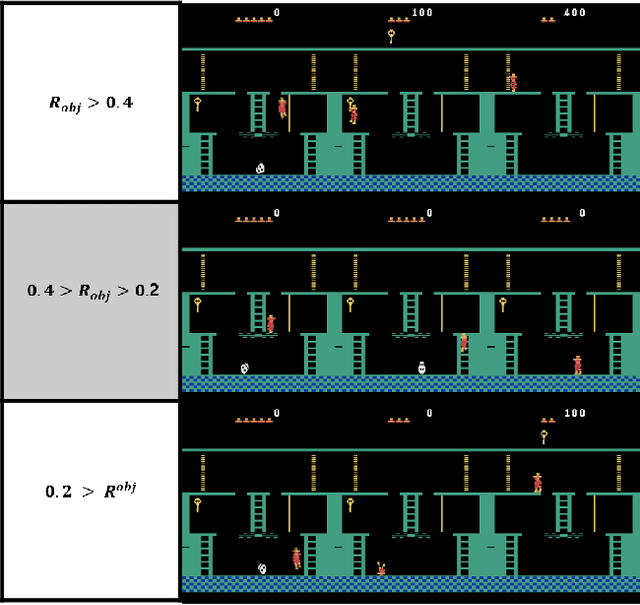
Recently, reinforcement learning has been successfully applied to the logical game of Go, various Atari games, and even a 3D game, Labyrinth, though it continues to have problems in sparse reward settings. It is difficult to explore, but also difficult to exploit, a small number of successes when learning policy. To solve this issue, the subgoal and option framework have been proposed. However, discovering subgoals online is too expensive to be used to learn options in large state spaces. We propose Micro-objective learning (MOL) to solve this problem. The main idea is to estimate how important a state is while training and to give an additional reward proportional to its importance. We evaluated our algorithm in two Atari games: Montezuma's Revenge and Seaquest. With three experiments to each game, MOL significantly improved the baseline scores. Especially in Montezuma's Revenge, MOL achieved two times better results than the previous state-of-the-art model.