 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScore-Repellent Monte Carlo: Toward Efficient Non-Markovian Sampler with Constant Memory in General State Spaces
Apr 24, 2026History-dependent sampling can reduce long-run Monte Carlo variance by discouraging redundant revisits, but existing schemes typically encode history through empirical measure on finite state spaces, which is infeasible in high-dimensional discrete configuration spaces or ill-posed in continuous domains. We propose Score-Repellent Monte Carlo (SRMC) framework that summarizes trajectory history by a running average of score evaluations in $R^d$, where $d$ is the dimension of the score and state representation. This history is converted into a surrogate target through an exponential score tilt, indexed with $α$ that represents the strength of repellence in controlling the magnitude of the history-based repulsion. The surrogate family is normalization-free in the standard MCMC sense, yielding a generic wrapper: at each iteration, any base kernel targeting $π$ can instead be run on the current surrogate $π_{θ_n}$ while the history is updated online. We analyze the coupled evolution of the history recursion and Monte Carlo estimators using stochastic approximation with controlled Markovian noise, establishing almost sure convergence and a joint central limit theorem. We further identify regimes in which the asymptotic covariance decreases as $α$ increases, with scaling $O(1/α)$, extending the near-zero-variance effect of finite-state history-dependent samplers to general state spaces with constant memory. Experiments on continuous targets and discrete energy-based models demonstrate improved estimator variance and mode coverage, while retaining $O(d)$ memory usage and modest per-iteration overhead.
Holi-DETR: Holistic Fashion Item Detection Leveraging Contextual Information
Dec 29, 2025Fashion item detection is challenging due to the ambiguities introduced by the highly diverse appearances of fashion items and the similarities among item subcategories. To address this challenge, we propose a novel Holistic Detection Transformer (Holi-DETR) that detects fashion items in outfit images holistically, by leveraging contextual information. Fashion items often have meaningful relationships as they are combined to create specific styles. Unlike conventional detectors that detect each item independently, Holi-DETR detects multiple items while reducing ambiguities by leveraging three distinct types of contextual information: (1) the co-occurrence relationship between fashion items, (2) the relative position and size based on inter-item spatial arrangements, and (3) the spatial relationships between items and human body key-points. %Holi-DETR explicitly incorporates three types of contextual information: (1) the co-occurrence probability between fashion items, (2) the relative position and size based on inter-item spatial arrangements, and (3) the spatial relationships between items and human body key-points. To this end, we propose a novel architecture that integrates these three types of heterogeneous contextual information into the Detection Transformer (DETR) and its subsequent models. In experiments, the proposed methods improved the performance of the vanilla DETR and the more recently developed Co-DETR by 3.6 percent points (pp) and 1.1 pp, respectively, in terms of average precision (AP).
Item Region-based Style Classification Network (IRSN): A Fashion Style Classifier Based on Domain Knowledge of Fashion Experts
Dec 23, 2025Fashion style classification is a challenging task because of the large visual variation within the same style and the existence of visually similar styles. Styles are expressed not only by the global appearance, but also by the attributes of individual items and their combinations. In this study, we propose an item region-based fashion style classification network (IRSN) to effectively classify fashion styles by analyzing item-specific features and their combinations in addition to global features. IRSN extracts features of each item region using item region pooling (IRP), analyzes them separately, and combines them using gated feature fusion (GFF). In addition, we improve the feature extractor by applying a dual-backbone architecture that combines a domain-specific feature extractor and a general feature extractor pre-trained with a large-scale image-text dataset. In experiments, applying IRSN to six widely-used backbones, including EfficientNet, ConvNeXt, and Swin Transformer, improved style classification accuracy by an average of 6.9% and a maximum of 14.5% on the FashionStyle14 dataset and by an average of 7.6% and a maximum of 15.1% on the ShowniqV3 dataset. Visualization analysis also supports that the IRSN models are better than the baseline models at capturing differences between similar style classes.
* This is a pre-print of an article published in Applied Intelligence. The final authenticated version is available online at: https://doi.org/10.1007/s10489-024-05683-9
Enhanced Diffusion Sampling via Extrapolation with Multiple ODE Solutions
Apr 02, 2025Diffusion probabilistic models (DPMs), while effective in generating high-quality samples, often suffer from high computational costs due to their iterative sampling process. To address this, we propose an enhanced ODE-based sampling method for DPMs inspired by Richardson extrapolation, which reduces numerical error and improves convergence rates. Our method, RX-DPM, leverages multiple ODE solutions at intermediate time steps to extrapolate the denoised prediction in DPMs. This significantly enhances the accuracy of estimations for the final sample while maintaining the number of function evaluations (NFEs). Unlike standard Richardson extrapolation, which assumes uniform discretization of the time grid, we develop a more general formulation tailored to arbitrary time step scheduling, guided by local truncation error derived from a baseline sampling method. The simplicity of our approach facilitates accurate estimation of numerical solutions without significant computational overhead, and allows for seamless and convenient integration into various DPMs and solvers. Additionally, RX-DPM provides explicit error estimates, effectively demonstrating the faster convergence as the leading error term's order increases. Through a series of experiments, we show that the proposed method improves the quality of generated samples without requiring additional sampling iterations.
FIFO-Diffusion: Generating Infinite Videos from Text without Training
May 19, 2024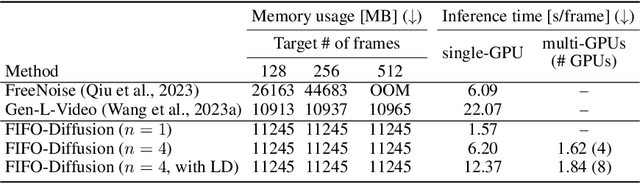

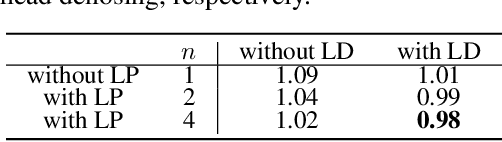
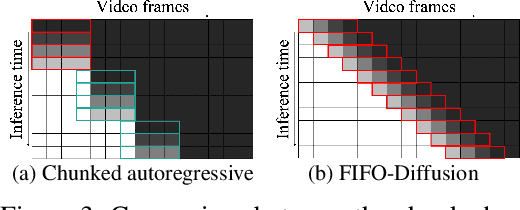
We propose a novel inference technique based on a pretrained diffusion model for text-conditional video generation. Our approach, called FIFO-Diffusion, is conceptually capable of generating infinitely long videos without training. This is achieved by iteratively performing diagonal denoising, which concurrently processes a series of consecutive frames with increasing noise levels in a queue; our method dequeues a fully denoised frame at the head while enqueuing a new random noise frame at the tail. However, diagonal denoising is a double-edged sword as the frames near the tail can take advantage of cleaner ones by forward reference but such a strategy induces the discrepancy between training and inference. Hence, we introduce latent partitioning to reduce the training-inference gap and lookahead denoising to leverage the benefit of forward referencing. We have demonstrated the promising results and effectiveness of the proposed methods on existing text-to-video generation baselines.
PECI-Net: Bolus segmentation from video fluoroscopic swallowing study images using preprocessing ensemble and cascaded inference
Mar 21, 2024Bolus segmentation is crucial for the automated detection of swallowing disorders in videofluoroscopic swallowing studies (VFSS). However, it is difficult for the model to accurately segment a bolus region in a VFSS image because VFSS images are translucent, have low contrast and unclear region boundaries, and lack color information. To overcome these challenges, we propose PECI-Net, a network architecture for VFSS image analysis that combines two novel techniques: the preprocessing ensemble network (PEN) and the cascaded inference network (CIN). PEN enhances the sharpness and contrast of the VFSS image by combining multiple preprocessing algorithms in a learnable way. CIN reduces ambiguity in bolus segmentation by using context from other regions through cascaded inference. Moreover, CIN prevents undesirable side effects from unreliably segmented regions by referring to the context in an asymmetric way. In experiments, PECI-Net exhibited higher performance than four recently developed baseline models, outperforming TernausNet, the best among the baseline models, by 4.54\% and the widely used UNet by 10.83\%. The results of the ablation studies confirm that CIN and PEN are effective in improving bolus segmentation performance.
* 20 pages, 8 figures,
A Training-Free Defense Framework for Robust Learned Image Compression
Jan 22, 2024



We study the robustness of learned image compression models against adversarial attacks and present a training-free defense technique based on simple image transform functions. Recent learned image compression models are vulnerable to adversarial attacks that result in poor compression rate, low reconstruction quality, or weird artifacts. To address the limitations, we propose a simple but effective two-way compression algorithm with random input transforms, which is conveniently applicable to existing image compression models. Unlike the na\"ive approaches, our approach preserves the original rate-distortion performance of the models on clean images. Moreover, the proposed algorithm requires no additional training or modification of existing models, making it more practical. We demonstrate the effectiveness of the proposed techniques through extensive experiments under multiple compression models, evaluation metrics, and attack scenarios.
Observation-Guided Diffusion Probabilistic Models
Oct 06, 2023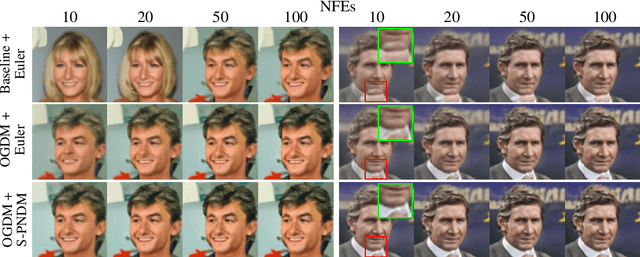
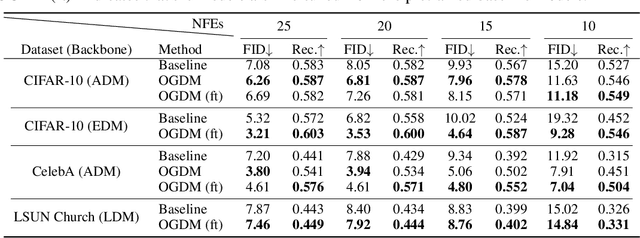
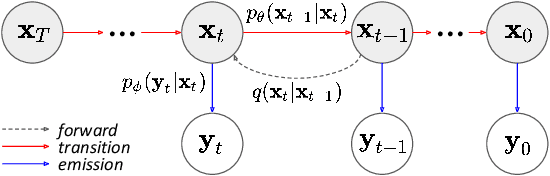

We propose a novel diffusion model called observation-guided diffusion probabilistic model (OGDM), which effectively addresses the trade-off between quality control and fast sampling. Our approach reestablishes the training objective by integrating the guidance of the observation process with the Markov chain in a principled way. This is achieved by introducing an additional loss term derived from the observation based on the conditional discriminator on noise level, which employs Bernoulli distribution indicating whether its input lies on the (noisy) real manifold or not. This strategy allows us to optimize the more accurate negative log-likelihood induced in the inference stage especially when the number of function evaluations is limited. The proposed training method is also advantageous even when incorporated only into the fine-tuning process, and it is compatible with various fast inference strategies since our method yields better denoising networks using the exactly same inference procedure without incurring extra computational cost. We demonstrate the effectiveness of the proposed training algorithm using diverse inference methods on strong diffusion model baselines.
Variable-Rate Deep Image Compression through Spatially-Adaptive Feature Transform
Aug 21, 2021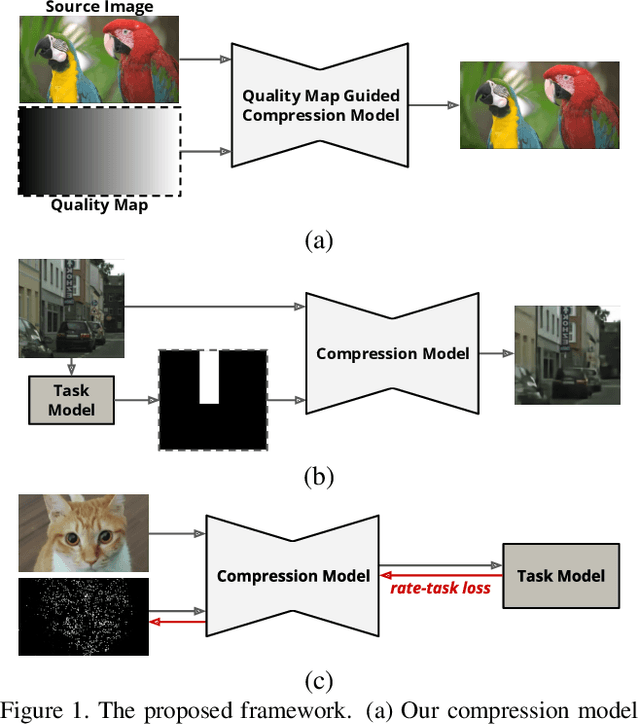


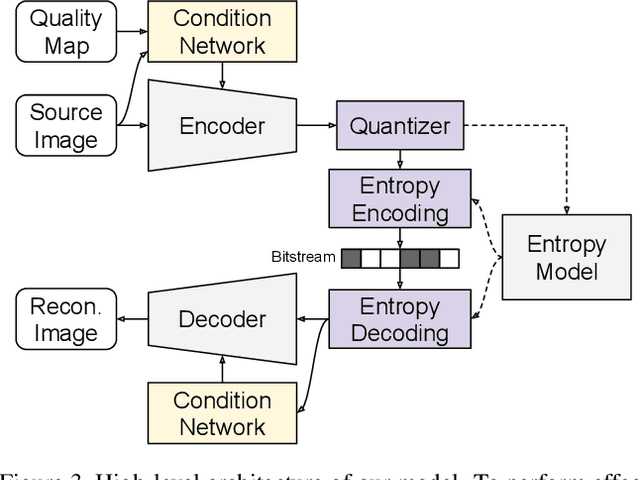
We propose a versatile deep image compression network based on Spatial Feature Transform (SFT arXiv:1804.02815), which takes a source image and a corresponding quality map as inputs and produce a compressed image with variable rates. Our model covers a wide range of compression rates using a single model, which is controlled by arbitrary pixel-wise quality maps. In addition, the proposed framework allows us to perform task-aware image compressions for various tasks, e.g., classification, by efficiently estimating optimized quality maps specific to target tasks for our encoding network. This is even possible with a pretrained network without learning separate models for individual tasks. Our algorithm achieves outstanding rate-distortion trade-off compared to the approaches based on multiple models that are optimized separately for several different target rates. At the same level of compression, the proposed approach successfully improves performance on image classification and text region quality preservation via task-aware quality map estimation without additional model training. The code is available at the project website: https://github.com/micmic123/QmapCompression
MCL-GAN: Generative Adversarial Networks with Multiple Specialized Discriminators
Jul 15, 2021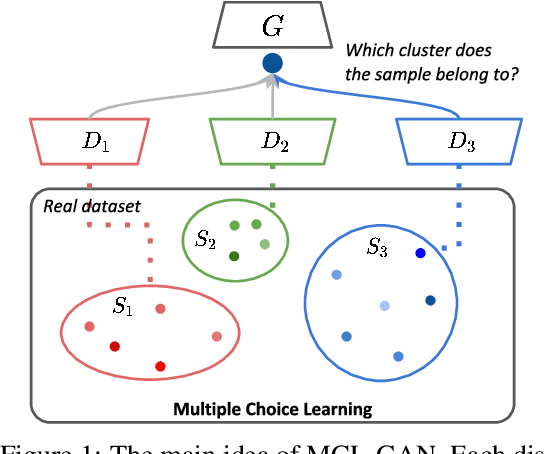
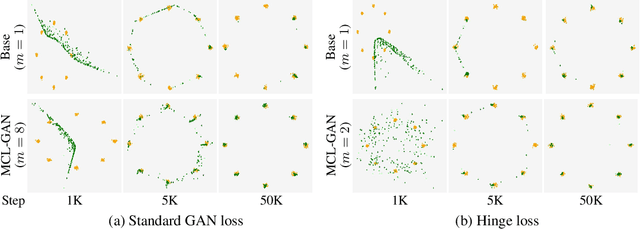
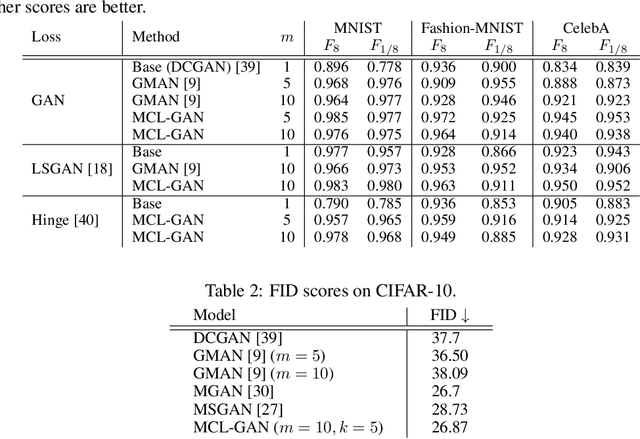
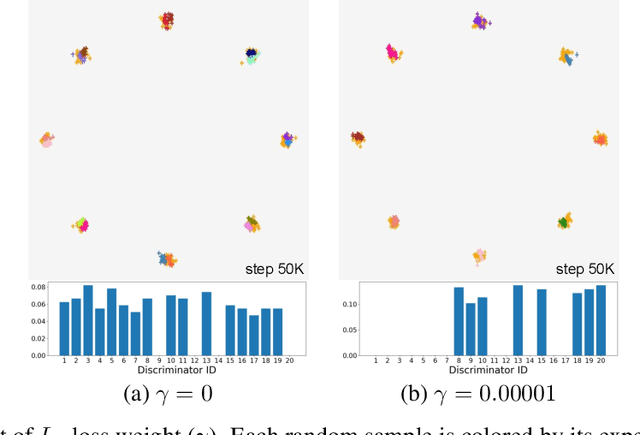
We propose a generative adversarial network with multiple discriminators, where each discriminator is specialized to distinguish the subset of a real dataset. This approach facilitates learning a generator coinciding with the underlying data distribution and thus mitigates the chronic mode collapse problem. From the inspiration of multiple choice learning, we guide each discriminator to have expertise in the subset of the entire data and allow the generator to find reasonable correspondences between the latent and real data spaces automatically without supervision for training examples and the number of discriminators. Despite the use of multiple discriminators, the backbone networks are shared across the discriminators and the increase of training cost is minimized. We demonstrate the effectiveness of our algorithm in the standard datasets using multiple evaluation metrics.