 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHoli-DETR: Holistic Fashion Item Detection Leveraging Contextual Information
Dec 29, 2025Fashion item detection is challenging due to the ambiguities introduced by the highly diverse appearances of fashion items and the similarities among item subcategories. To address this challenge, we propose a novel Holistic Detection Transformer (Holi-DETR) that detects fashion items in outfit images holistically, by leveraging contextual information. Fashion items often have meaningful relationships as they are combined to create specific styles. Unlike conventional detectors that detect each item independently, Holi-DETR detects multiple items while reducing ambiguities by leveraging three distinct types of contextual information: (1) the co-occurrence relationship between fashion items, (2) the relative position and size based on inter-item spatial arrangements, and (3) the spatial relationships between items and human body key-points. %Holi-DETR explicitly incorporates three types of contextual information: (1) the co-occurrence probability between fashion items, (2) the relative position and size based on inter-item spatial arrangements, and (3) the spatial relationships between items and human body key-points. To this end, we propose a novel architecture that integrates these three types of heterogeneous contextual information into the Detection Transformer (DETR) and its subsequent models. In experiments, the proposed methods improved the performance of the vanilla DETR and the more recently developed Co-DETR by 3.6 percent points (pp) and 1.1 pp, respectively, in terms of average precision (AP).
Item Region-based Style Classification Network (IRSN): A Fashion Style Classifier Based on Domain Knowledge of Fashion Experts
Dec 23, 2025Fashion style classification is a challenging task because of the large visual variation within the same style and the existence of visually similar styles. Styles are expressed not only by the global appearance, but also by the attributes of individual items and their combinations. In this study, we propose an item region-based fashion style classification network (IRSN) to effectively classify fashion styles by analyzing item-specific features and their combinations in addition to global features. IRSN extracts features of each item region using item region pooling (IRP), analyzes them separately, and combines them using gated feature fusion (GFF). In addition, we improve the feature extractor by applying a dual-backbone architecture that combines a domain-specific feature extractor and a general feature extractor pre-trained with a large-scale image-text dataset. In experiments, applying IRSN to six widely-used backbones, including EfficientNet, ConvNeXt, and Swin Transformer, improved style classification accuracy by an average of 6.9% and a maximum of 14.5% on the FashionStyle14 dataset and by an average of 7.6% and a maximum of 15.1% on the ShowniqV3 dataset. Visualization analysis also supports that the IRSN models are better than the baseline models at capturing differences between similar style classes.
* This is a pre-print of an article published in Applied Intelligence. The final authenticated version is available online at: https://doi.org/10.1007/s10489-024-05683-9
PECI-Net: Bolus segmentation from video fluoroscopic swallowing study images using preprocessing ensemble and cascaded inference
Mar 21, 2024Bolus segmentation is crucial for the automated detection of swallowing disorders in videofluoroscopic swallowing studies (VFSS). However, it is difficult for the model to accurately segment a bolus region in a VFSS image because VFSS images are translucent, have low contrast and unclear region boundaries, and lack color information. To overcome these challenges, we propose PECI-Net, a network architecture for VFSS image analysis that combines two novel techniques: the preprocessing ensemble network (PEN) and the cascaded inference network (CIN). PEN enhances the sharpness and contrast of the VFSS image by combining multiple preprocessing algorithms in a learnable way. CIN reduces ambiguity in bolus segmentation by using context from other regions through cascaded inference. Moreover, CIN prevents undesirable side effects from unreliably segmented regions by referring to the context in an asymmetric way. In experiments, PECI-Net exhibited higher performance than four recently developed baseline models, outperforming TernausNet, the best among the baseline models, by 4.54\% and the widely used UNet by 10.83\%. The results of the ablation studies confirm that CIN and PEN are effective in improving bolus segmentation performance.
* 20 pages, 8 figures,
Unidirectional Thin Adapter for Efficient Adaptation of Deep Neural Networks
Mar 23, 2022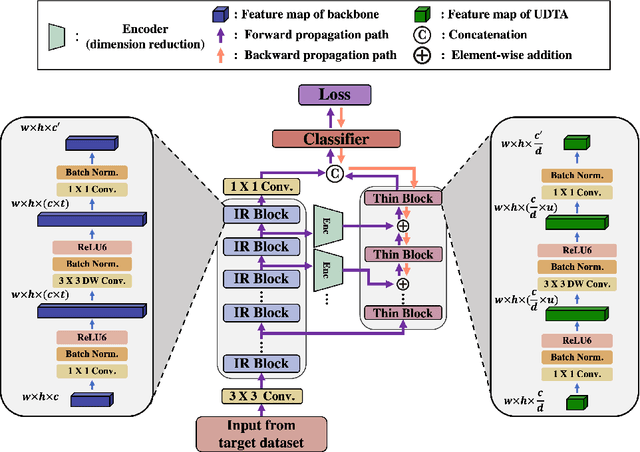
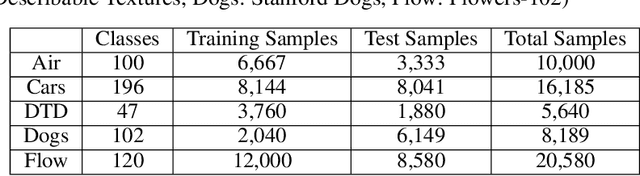

In this paper, we propose a new adapter network for adapting a pre-trained deep neural network to a target domain with minimal computation. The proposed model, unidirectional thin adapter (UDTA), helps the classifier adapt to new data by providing auxiliary features that complement the backbone network. UDTA takes outputs from multiple layers of the backbone as input features but does not transmit any feature to the backbone. As a result, UDTA can learn without computing the gradient of the backbone, which saves computation for training significantly. In addition, since UDTA learns the target task without modifying the backbone, a single backbone can adapt to multiple tasks by learning only UDTAs separately. In experiments on five fine-grained classification datasets consisting of a small number of samples, UDTA significantly reduced computation and training time required for backpropagation while showing comparable or even improved accuracy compared with conventional adapter models.
U-Singer: Multi-Singer Singing Voice Synthesizer that Controls Emotional Intensity
Mar 02, 2022



We propose U-Singer, the first multi-singer emotional singing voice synthesizer that expresses various levels of emotional intensity. During synthesizing singing voices according to the lyrics, pitch, and duration of the music score, U-Singer reflects singer characteristics and emotional intensity by adding variances in pitch, energy, and phoneme duration according to singer ID and emotional intensity. Representing all attributes by conditional residual embeddings in a single unified embedding space, U-Singer controls mutually correlated style attributes, minimizing interference. Additionally, we apply emotion embedding interpolation and extrapolation techniques that lead the model to learn a linear embedding space and allow the model to express emotional intensity levels not included in the training data. In experiments, U-Singer synthesized high-fidelity singing voices reflecting the singer ID and emotional intensity. The visualization of the unified embedding space exhibits that U-singer estimates the correct variations in pitch and energy highly correlated with the singer ID and emotional intensity level. The audio samples are presented at https://u-singer.github.io.
OUR-GAN: One-shot Ultra-high-Resolution Generative Adversarial Networks
Feb 28, 2022


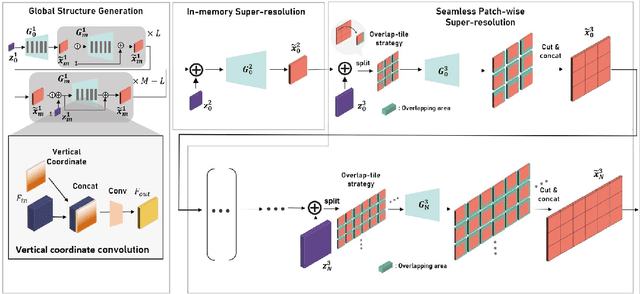
We propose OUR-GAN, the first one-shot ultra-high-resolution (UHR) image synthesis framework that generates non-repetitive images with 4K or higher resolution from a single training image. OUR-GAN generates a visually coherent image at low resolution and then gradually increases the resolution by super-resolution. Since OUR-GAN learns from a real UHR image, it can synthesize large-scale shapes with fine details while maintaining long-range coherence, which is difficult with conventional generative models that generate large images based on the patch distribution learned from relatively small images. OUR-GAN applies seamless subregion-wise super-resolution that synthesizes 4k or higher UHR images with limited memory, preventing discontinuity at the boundary. Additionally, OUR-GAN improves visual coherence maintaining diversity by adding vertical positional embeddings to the feature maps. In experiments on the ST4K and RAISE datasets, OUR-GAN exhibited improved fidelity, visual coherency, and diversity compared with existing methods. The synthesized images are presented at https://anonymous-62348.github.io.
UniTTS: Residual Learning of Unified Embedding Space for Speech Style Control
Jun 21, 2021
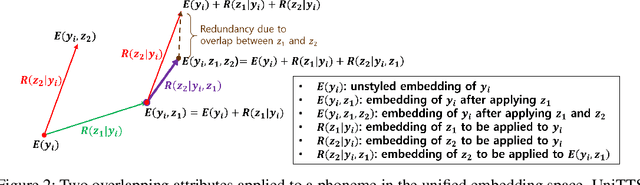

We propose a novel high-fidelity expressive speech synthesis model, UniTTS, that learns and controls overlapping style attributes avoiding interference. UniTTS represents multiple style attributes in a single unified embedding space by the residuals between the phoneme embeddings before and after applying the attributes. The proposed method is especially effective in controlling multiple attributes that are difficult to separate cleanly, such as speaker ID and emotion, because it minimizes redundancy when adding variance in speaker ID and emotion, and additionally, predicts duration, pitch, and energy based on the speaker ID and emotion. In experiments, the visualization results exhibit that the proposed methods learned multiple attributes harmoniously in a manner that can be easily separated again. As well, UniTTS synthesized high-fidelity speech signals controlling multiple style attributes. The synthesized speech samples are presented at https://jackson-kang.github.io/paper_works/UniTTS/demos.
Fast DCTTS: Efficient Deep Convolutional Text-to-Speech
Apr 01, 2021
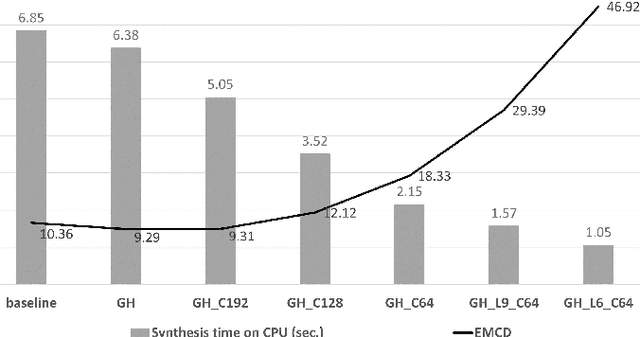


We propose an end-to-end speech synthesizer, Fast DCTTS, that synthesizes speech in real time on a single CPU thread. The proposed model is composed of a carefully-tuned lightweight network designed by applying multiple network reduction and fidelity improvement techniques. In addition, we propose a novel group highway activation that can compromise between computational efficiency and the regularization effect of the gating mechanism. As well, we introduce a new metric called Elastic mel-cepstral distortion (EMCD) to measure the fidelity of the output mel-spectrogram. In experiments, we analyze the effect of the acceleration techniques on speed and speech quality. Compared with the baseline model, the proposed model exhibits improved MOS from 2.62 to 2.74 with only 1.76% computation and 2.75% parameters. The speed on a single CPU thread was improved by 7.45 times, which is fast enough to produce mel-spectrogram in real time without GPU.
VocGAN: A High-Fidelity Real-time Vocoder with a Hierarchically-nested Adversarial Network
Jul 30, 2020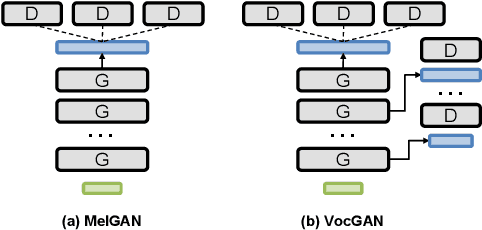
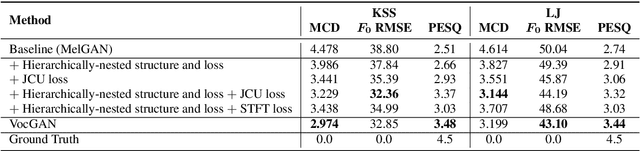
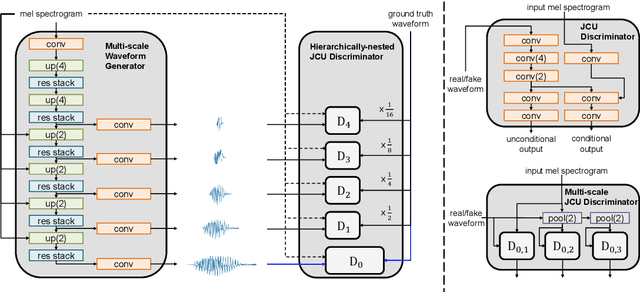
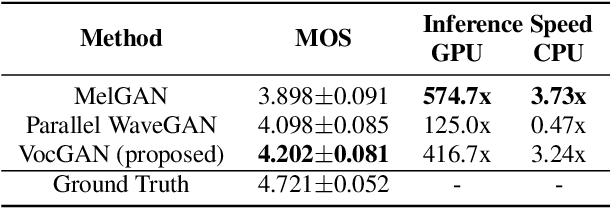
We present a novel high-fidelity real-time neural vocoder called VocGAN. A recently developed GAN-based vocoder, MelGAN, produces speech waveforms in real-time. However, it often produces a waveform that is insufficient in quality or inconsistent with acoustic characteristics of the input mel spectrogram. VocGAN is nearly as fast as MelGAN, but it significantly improves the quality and consistency of the output waveform. VocGAN applies a multi-scale waveform generator and a hierarchically-nested discriminator to learn multiple levels of acoustic properties in a balanced way. It also applies the joint conditional and unconditional objective, which has shown successful results in high-resolution image synthesis. In experiments, VocGAN synthesizes speech waveforms 416.7x faster on a GTX 1080Ti GPU and 3.24x faster on a CPU than real-time. Compared with MelGAN, it also exhibits significantly improved quality in multiple evaluation metrics including mean opinion score (MOS) with minimal additional overhead. Additionally, compared with Parallel WaveGAN, another recently developed high-fidelity vocoder, VocGAN is 6.98x faster on a CPU and exhibits higher MOS.
Capsule Networks Need an Improved Routing Algorithm
Jul 31, 2019



In capsule networks, the routing algorithm connects capsules in consecutive layers, enabling the upper-level capsules to learn higher-level concepts by combining the concepts of the lower-level capsules. Capsule networks are known to have a few advantages over conventional neural networks, including robustness to 3D viewpoint changes and generalization capability. However, some studies have reported negative experimental results. Nevertheless, the reason for this phenomenon has not been analyzed yet. We empirically analyzed the effect of five different routing algorithms. The experimental results show that the routing algorithms do not behave as expected and often produce results that are worse than simple baseline algorithms that assign the connection strengths uniformly or randomly. We also show that, in most cases, the routing algorithms do not change the classification result but polarize the link strengths, and the polarization can be extreme when they continue to repeat without stopping. In order to realize the true potential of the capsule network, it is essential to develop an improved routing algorithm.