 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniTTS: Residual Learning of Unified Embedding Space for Speech Style Control
Paper and Code
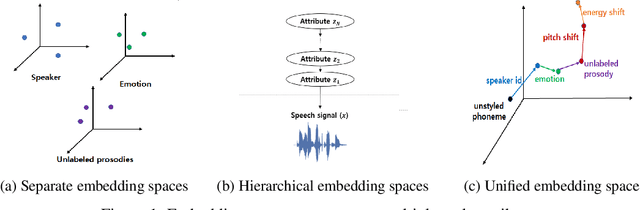
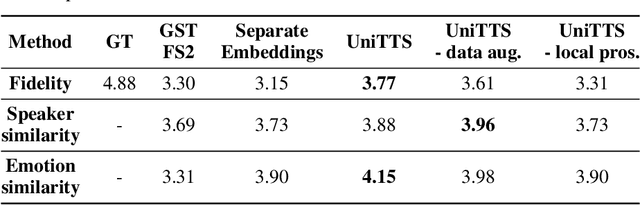
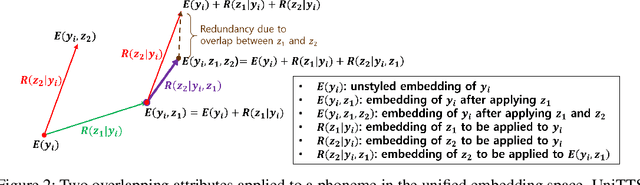

We propose a novel high-fidelity expressive speech synthesis model, UniTTS, that learns and controls overlapping style attributes avoiding interference. UniTTS represents multiple style attributes in a single unified embedding space by the residuals between the phoneme embeddings before and after applying the attributes. The proposed method is especially effective in controlling multiple attributes that are difficult to separate cleanly, such as speaker ID and emotion, because it minimizes redundancy when adding variance in speaker ID and emotion, and additionally, predicts duration, pitch, and energy based on the speaker ID and emotion. In experiments, the visualization results exhibit that the proposed methods learned multiple attributes harmoniously in a manner that can be easily separated again. As well, UniTTS synthesized high-fidelity speech signals controlling multiple style attributes. The synthesized speech samples are presented at https://jackson-kang.github.io/paper_works/UniTTS/demos.