 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausality-Aware Contrastive Learning for Robust Multivariate Time-Series Anomaly Detection
Jun 04, 2025Utilizing the complex inter-variable causal relationships within multivariate time-series provides a promising avenue toward more robust and reliable multivariate time-series anomaly detection (MTSAD) but remains an underexplored area of research. This paper proposes Causality-Aware contrastive learning for RObust multivariate Time-Series (CAROTS), a novel MTSAD pipeline that incorporates the notion of causality into contrastive learning. CAROTS employs two data augmentors to obtain causality-preserving and -disturbing samples that serve as a wide range of normal variations and synthetic anomalies, respectively. With causality-preserving and -disturbing samples as positives and negatives, CAROTS performs contrastive learning to train an encoder whose latent space separates normal and abnormal samples based on causality. Moreover, CAROTS introduces a similarity-filtered one-class contrastive loss that encourages the contrastive learning process to gradually incorporate more semantically diverse samples with common causal relationships. Extensive experiments on five real-world and two synthetic datasets validate that the integration of causal relationships endows CAROTS with improved MTSAD capabilities. The code is available at https://github.com/kimanki/CAROTS.
U-Singer: Multi-Singer Singing Voice Synthesizer that Controls Emotional Intensity
Mar 02, 2022



We propose U-Singer, the first multi-singer emotional singing voice synthesizer that expresses various levels of emotional intensity. During synthesizing singing voices according to the lyrics, pitch, and duration of the music score, U-Singer reflects singer characteristics and emotional intensity by adding variances in pitch, energy, and phoneme duration according to singer ID and emotional intensity. Representing all attributes by conditional residual embeddings in a single unified embedding space, U-Singer controls mutually correlated style attributes, minimizing interference. Additionally, we apply emotion embedding interpolation and extrapolation techniques that lead the model to learn a linear embedding space and allow the model to express emotional intensity levels not included in the training data. In experiments, U-Singer synthesized high-fidelity singing voices reflecting the singer ID and emotional intensity. The visualization of the unified embedding space exhibits that U-singer estimates the correct variations in pitch and energy highly correlated with the singer ID and emotional intensity level. The audio samples are presented at https://u-singer.github.io.
UniTTS: Residual Learning of Unified Embedding Space for Speech Style Control
Jun 21, 2021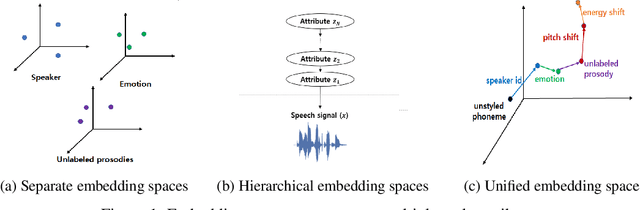
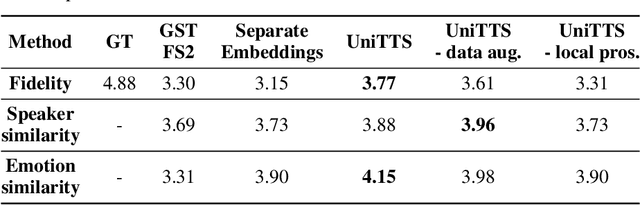
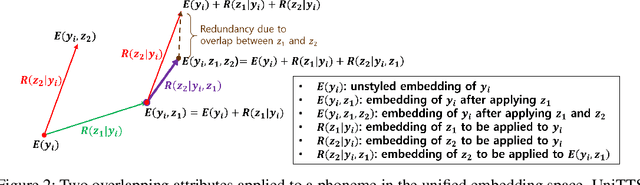

We propose a novel high-fidelity expressive speech synthesis model, UniTTS, that learns and controls overlapping style attributes avoiding interference. UniTTS represents multiple style attributes in a single unified embedding space by the residuals between the phoneme embeddings before and after applying the attributes. The proposed method is especially effective in controlling multiple attributes that are difficult to separate cleanly, such as speaker ID and emotion, because it minimizes redundancy when adding variance in speaker ID and emotion, and additionally, predicts duration, pitch, and energy based on the speaker ID and emotion. In experiments, the visualization results exhibit that the proposed methods learned multiple attributes harmoniously in a manner that can be easily separated again. As well, UniTTS synthesized high-fidelity speech signals controlling multiple style attributes. The synthesized speech samples are presented at https://jackson-kang.github.io/paper_works/UniTTS/demos.