 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKPIs 2024 Challenge: Advancing Glomerular Segmentation from Patch- to Slide-Level
Feb 11, 2025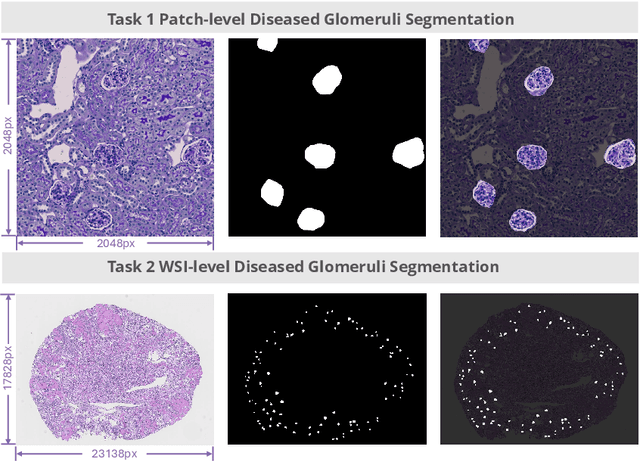

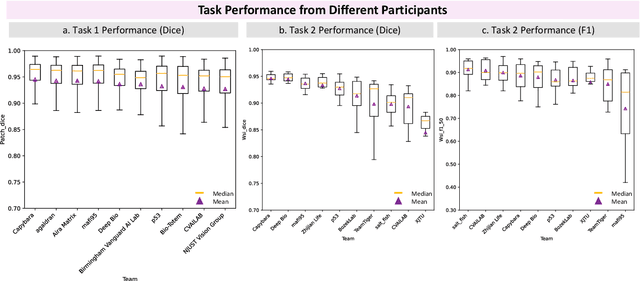

Chronic kidney disease (CKD) is a major global health issue, affecting over 10% of the population and causing significant mortality. While kidney biopsy remains the gold standard for CKD diagnosis and treatment, the lack of comprehensive benchmarks for kidney pathology segmentation hinders progress in the field. To address this, we organized the Kidney Pathology Image Segmentation (KPIs) Challenge, introducing a dataset that incorporates preclinical rodent models of CKD with over 10,000 annotated glomeruli from 60+ Periodic Acid Schiff (PAS)-stained whole slide images. The challenge includes two tasks, patch-level segmentation and whole slide image segmentation and detection, evaluated using the Dice Similarity Coefficient (DSC) and F1-score. By encouraging innovative segmentation methods that adapt to diverse CKD models and tissue conditions, the KPIs Challenge aims to advance kidney pathology analysis, establish new benchmarks, and enable precise, large-scale quantification for disease research and diagnosis.
The Disharmony Between BN and ReLU Causes Gradient Explosion, but is Offset by the Correlation Between Activations
Apr 27, 2023Deep neural networks based on batch normalization and ReLU-like activation functions can experience instability during the early stages of training due to the high gradient induced by temporal gradient explosion. We explain how ReLU reduces variance more than expected, and how batch normalization amplifies the gradient during recovery, which causes gradient explosion while forward propagation remains stable. Additionally, we discuss how the dynamics of a deep neural network change during training and how the correlation between inputs can alleviate this problem. Lastly, we propose a better adaptive learning rate algorithm inspired by second-order optimization algorithms, which outperforms existing learning rate scaling methods in large batch training and can also replace WarmUp in small batch training.
Capsule Networks Need an Improved Routing Algorithm
Jul 31, 2019



In capsule networks, the routing algorithm connects capsules in consecutive layers, enabling the upper-level capsules to learn higher-level concepts by combining the concepts of the lower-level capsules. Capsule networks are known to have a few advantages over conventional neural networks, including robustness to 3D viewpoint changes and generalization capability. However, some studies have reported negative experimental results. Nevertheless, the reason for this phenomenon has not been analyzed yet. We empirically analyzed the effect of five different routing algorithms. The experimental results show that the routing algorithms do not behave as expected and often produce results that are worse than simple baseline algorithms that assign the connection strengths uniformly or randomly. We also show that, in most cases, the routing algorithms do not change the classification result but polarize the link strengths, and the polarization can be extreme when they continue to repeat without stopping. In order to realize the true potential of the capsule network, it is essential to develop an improved routing algorithm.
Overcoming Catastrophic Forgetting by Neuron-level Plasticity Control
Jul 31, 2019



To address the issue of catastrophic forgetting in neural networks, we propose a novel, simple, and effective solution called neuron-level plasticity control (NPC). While learning a new task, the proposed method preserves the knowledge for the previous tasks by controlling the plasticity of the network at the neuron level. NPC estimates the importance value of each neuron and consolidates important \textit{neurons} by applying lower learning rates, rather than restricting individual connection weights to stay close to certain values. The experimental results on the incremental MNIST (iMNIST) and incremental CIFAR100 (iCIFAR100) datasets show that neuron-level consolidation is substantially more effective compared to the connection-level consolidation approaches.