 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVocGAN: A High-Fidelity Real-time Vocoder with a Hierarchically-nested Adversarial Network
Paper and Code
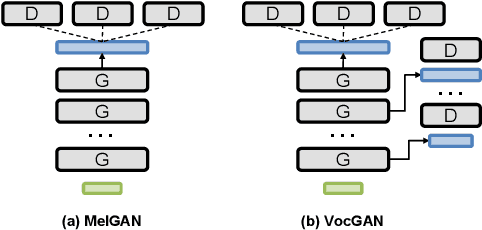
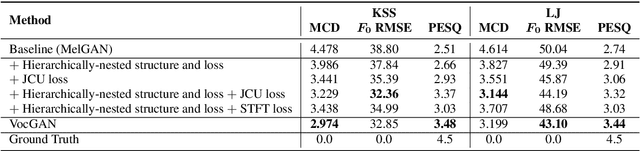
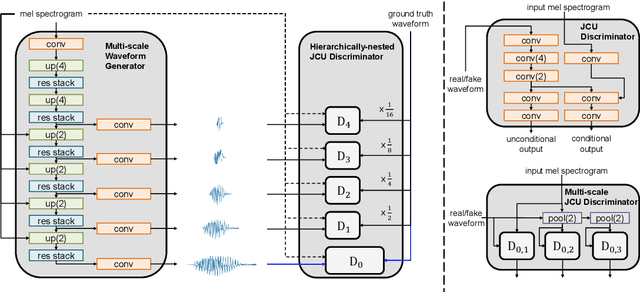
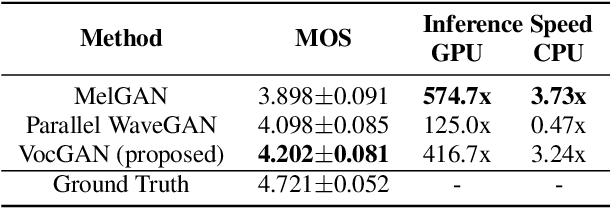
We present a novel high-fidelity real-time neural vocoder called VocGAN. A recently developed GAN-based vocoder, MelGAN, produces speech waveforms in real-time. However, it often produces a waveform that is insufficient in quality or inconsistent with acoustic characteristics of the input mel spectrogram. VocGAN is nearly as fast as MelGAN, but it significantly improves the quality and consistency of the output waveform. VocGAN applies a multi-scale waveform generator and a hierarchically-nested discriminator to learn multiple levels of acoustic properties in a balanced way. It also applies the joint conditional and unconditional objective, which has shown successful results in high-resolution image synthesis. In experiments, VocGAN synthesizes speech waveforms 416.7x faster on a GTX 1080Ti GPU and 3.24x faster on a CPU than real-time. Compared with MelGAN, it also exhibits significantly improved quality in multiple evaluation metrics including mean opinion score (MOS) with minimal additional overhead. Additionally, compared with Parallel WaveGAN, another recently developed high-fidelity vocoder, VocGAN is 6.98x faster on a CPU and exhibits higher MOS.