 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobustSpeechFlow: Learning Robust Text-to-Speech Trajectories via Augmentation-based Contrastive Flow Matching
May 21, 2026While flow-matching text-to-speech (TTS) achieves strong zero-shot speaker similarity and naturalness, it remains susceptible to content fidelity issues, particularly skip and repeat errors from imperfect alignment. We propose RobustSpeechFlow, a training strategy that improves alignment robustness by extending contrastive flow matching with length-preserving repeat and skip latent augmentations. Requiring no external aligners or preference data, our method directly penalizes realistic failure modes and readily integrates into existing pipelines. On Seed-TTS-eval, it reduces the word error rate (WER) from 1.44 to 1.38 using only 0.06B parameters. On our ZERO500 benchmark, it delivers consistent intelligibility improvements across diverse speaker and prosody conditions; at NFE=24, it reduces English character error rate (CER) from 0.48\% to 0.35\% and Korean CER from 0.81\% to 0.57\%. Audio samples: https://robustspeechflow.github.io/
SupertonicTTS: Towards Highly Scalable and Efficient Text-to-Speech System
Mar 29, 2025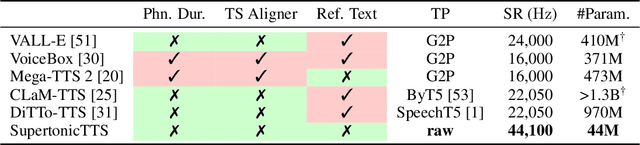
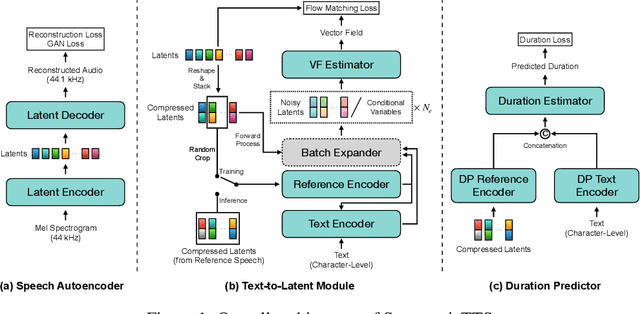

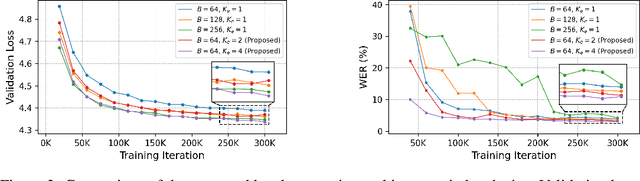
We present a novel text-to-speech (TTS) system, namely SupertonicTTS, for improved scalability and efficiency in speech synthesis. SupertonicTTS is comprised of three components: a speech autoencoder for continuous latent representation, a text-to-latent module leveraging flow-matching for text-to-latent mapping, and an utterance-level duration predictor. To enable a lightweight architecture, we employ a low-dimensional latent space, temporal compression of latents, and ConvNeXt blocks. We further simplify the TTS pipeline by operating directly on raw character-level text and employing cross-attention for text-speech alignment, thus eliminating the need for grapheme-to-phoneme (G2P) modules and external aligners. In addition, we introduce context-sharing batch expansion that accelerates loss convergence and stabilizes text-speech alignment. Experimental results demonstrate that SupertonicTTS achieves competitive performance while significantly reducing architectural complexity and computational overhead compared to contemporary TTS models. Audio samples demonstrating the capabilities of SupertonicTTS are available at: https://supertonictts.github.io/.
DualSpeech: Enhancing Speaker-Fidelity and Text-Intelligibility Through Dual Classifier-Free Guidance
Aug 27, 2024


Text-to-Speech (TTS) models have advanced significantly, aiming to accurately replicate human speech's diversity, including unique speaker identities and linguistic nuances. Despite these advancements, achieving an optimal balance between speaker-fidelity and text-intelligibility remains a challenge, particularly when diverse control demands are considered. Addressing this, we introduce DualSpeech, a TTS model that integrates phoneme-level latent diffusion with dual classifier-free guidance. This approach enables exceptional control over speaker-fidelity and text-intelligibility. Experimental results demonstrate that by utilizing the sophisticated control, DualSpeech surpasses existing state-of-the-art TTS models in performance. Demos are available at https://bit.ly/48Ewoib.
Varianceflow: High-Quality and Controllable Text-to-Speech using Variance Information via Normalizing Flow
Feb 27, 2023



There are two types of methods for non-autoregressive text-to-speech models to learn the one-to-many relationship between text and speech effectively. The first one is to use an advanced generative framework such as normalizing flow (NF). The second one is to use variance information such as pitch or energy together when generating speech. For the second type, it is also possible to control the variance factors by adjusting the variance values provided to a model. In this paper, we propose a novel model called VarianceFlow combining the advantages of the two types. By modeling the variance with NF, VarianceFlow predicts the variance information more precisely with improved speech quality. Also, the objective function of NF makes the model use the variance information and the text in a disentangled manner resulting in more precise variance control. In experiments, VarianceFlow shows superior performance over other state-of-the-art TTS models both in terms of speech quality and controllability.
NANSY++: Unified Voice Synthesis with Neural Analysis and Synthesis
Nov 17, 2022Various applications of voice synthesis have been developed independently despite the fact that they generate "voice" as output in common. In addition, most of the voice synthesis models still require a large number of audio data paired with annotated labels (e.g., text transcription and music score) for training. To this end, we propose a unified framework of synthesizing and manipulating voice signals from analysis features, dubbed NANSY++. The backbone network of NANSY++ is trained in a self-supervised manner that does not require any annotations paired with audio. After training the backbone network, we efficiently tackle four voice applications - i.e. voice conversion, text-to-speech, singing voice synthesis, and voice designing - by partially modeling the analysis features required for each task. Extensive experiments show that the proposed framework offers competitive advantages such as controllability, data efficiency, and fast training convergence, while providing high quality synthesis. Audio samples: tinyurl.com/8tnsy3uc.
Avocodo: Generative Adversarial Network for Artifact-free Vocoder
Jun 28, 2022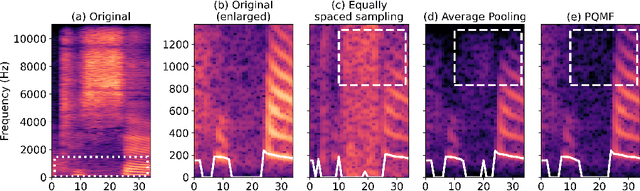
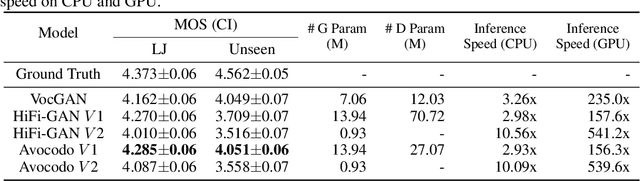
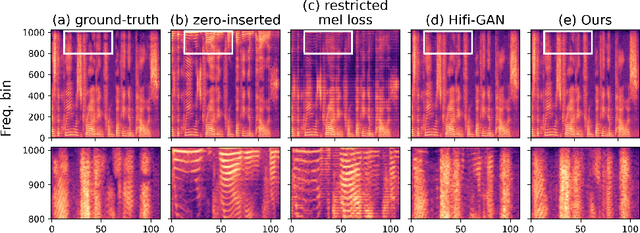
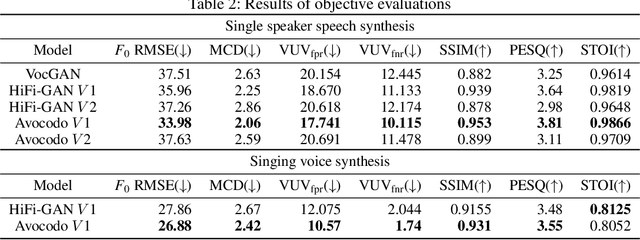
Neural vocoders based on the generative adversarial neural network (GAN) have been widely used due to their fast inference speed and lightweight networks while generating high-quality speech waveforms. Since the perceptually important speech components are primarily concentrated in the low-frequency band, most of the GAN-based neural vocoders perform multi-scale analysis that evaluates downsampled speech waveforms. This multi-scale analysis helps the generator improve speech intelligibility. However, in preliminary experiments, we observed that the multi-scale analysis which focuses on the low-frequency band causes unintended artifacts, e.g., aliasing and imaging artifacts, and these artifacts degrade the synthesized speech waveform quality. Therefore, in this paper, we investigate the relationship between these artifacts and GAN-based neural vocoders and propose a GAN-based neural vocoder, called Avocodo, that allows the synthesis of high-fidelity speech with reduced artifacts. We introduce two kinds of discriminators to evaluate waveforms in various perspectives: a collaborative multi-band discriminator and a sub-band discriminator. We also utilize a pseudo quadrature mirror filter bank to obtain downsampled multi-band waveforms while avoiding aliasing. The experimental results show that Avocodo outperforms conventional GAN-based neural vocoders in both speech and singing voice synthesis tasks and can synthesize artifact-free speech. Especially, Avocodo is even capable to reproduce high-quality waveforms of unseen speakers.
Hierarchical and Multi-Scale Variational Autoencoder for Diverse and Natural Non-Autoregressive Text-to-Speech
Apr 08, 2022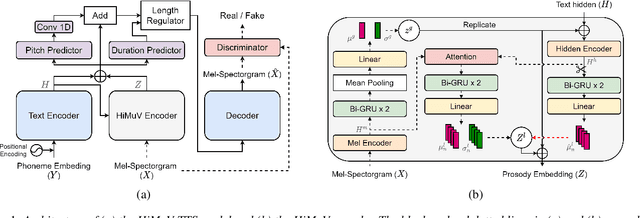
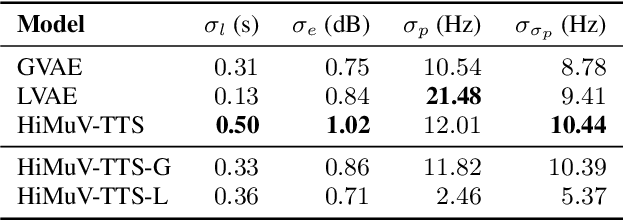
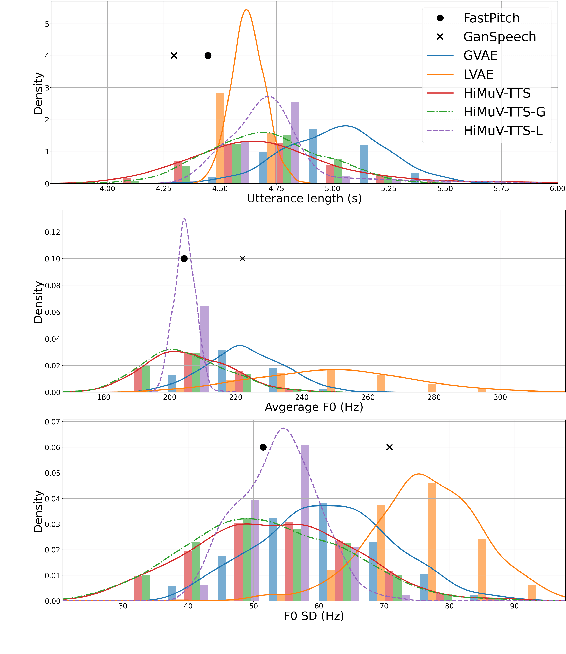
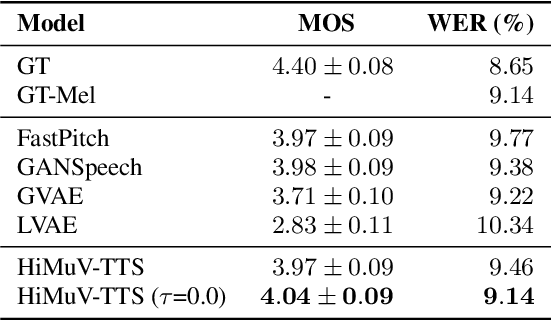
This paper proposes a hierarchical and multi-scale variational autoencoder-based non-autoregressive text-to-speech model (HiMuV-TTS) to generate natural speech with diverse speaking styles. Recent advances in non-autoregressive TTS (NAR-TTS) models have significantly improved the inference speed and robustness of synthesized speech. However, the diversity of speaking styles and naturalness are needed to be improved. To solve this problem, we propose the HiMuV-TTS model that first determines the global-scale prosody and then determines the local-scale prosody via conditioning on the global-scale prosody and the learned text representation. In addition, we improve the quality of speech by adopting the adversarial training technique. Experimental results verify that the proposed HiMuV-TTS model can generate more diverse and natural speech as compared to TTS models with single-scale variational autoencoders, and can represent different prosody information in each scale.
GANSpeech: Adversarial Training for High-Fidelity Multi-Speaker Speech Synthesis
Jun 29, 2021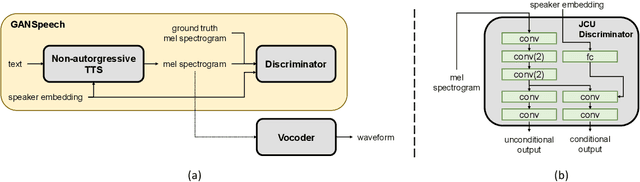


Recent advances in neural multi-speaker text-to-speech (TTS) models have enabled the generation of reasonably good speech quality with a single model and made it possible to synthesize the speech of a speaker with limited training data. Fine-tuning to the target speaker data with the multi-speaker model can achieve better quality, however, there still exists a gap compared to the real speech sample and the model depends on the speaker. In this work, we propose GANSpeech, which is a high-fidelity multi-speaker TTS model that adopts the adversarial training method to a non-autoregressive multi-speaker TTS model. In addition, we propose simple but efficient automatic scaling methods for feature matching loss used in adversarial training. In the subjective listening tests, GANSpeech significantly outperformed the baseline multi-speaker FastSpeech and FastSpeech2 models, and showed a better MOS score than the speaker-specific fine-tuned FastSpeech2.
VocGAN: A High-Fidelity Real-time Vocoder with a Hierarchically-nested Adversarial Network
Jul 30, 2020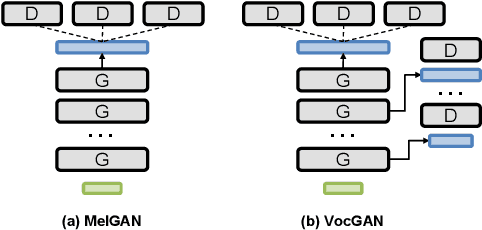
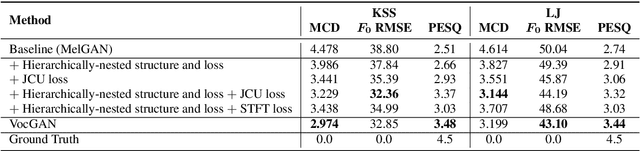
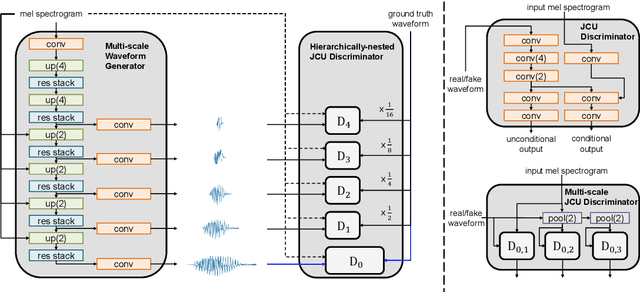
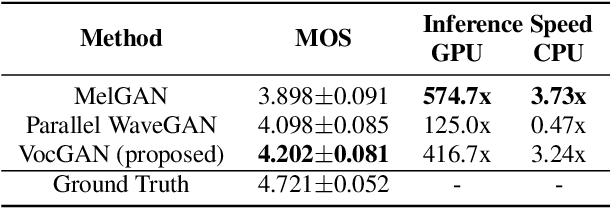
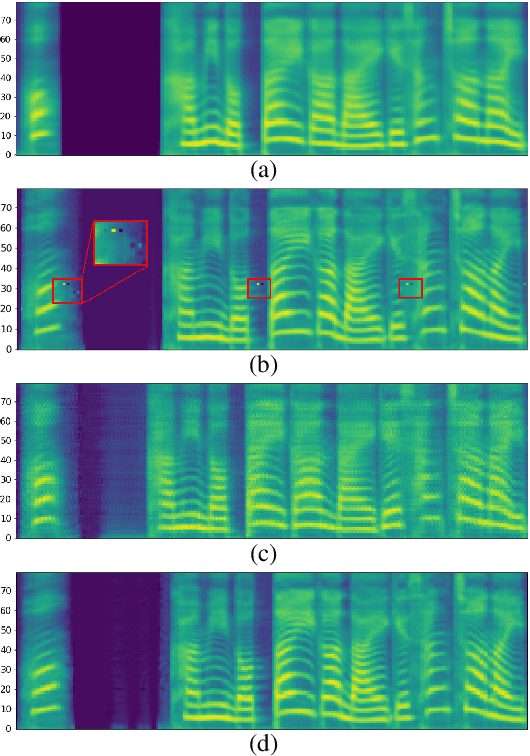
We present a novel high-fidelity real-time neural vocoder called VocGAN. A recently developed GAN-based vocoder, MelGAN, produces speech waveforms in real-time. However, it often produces a waveform that is insufficient in quality or inconsistent with acoustic characteristics of the input mel spectrogram. VocGAN is nearly as fast as MelGAN, but it significantly improves the quality and consistency of the output waveform. VocGAN applies a multi-scale waveform generator and a hierarchically-nested discriminator to learn multiple levels of acoustic properties in a balanced way. It also applies the joint conditional and unconditional objective, which has shown successful results in high-resolution image synthesis. In experiments, VocGAN synthesizes speech waveforms 416.7x faster on a GTX 1080Ti GPU and 3.24x faster on a CPU than real-time. Compared with MelGAN, it also exhibits significantly improved quality in multiple evaluation metrics including mean opinion score (MOS) with minimal additional overhead. Additionally, compared with Parallel WaveGAN, another recently developed high-fidelity vocoder, VocGAN is 6.98x faster on a CPU and exhibits higher MOS.