 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical and Multi-Scale Variational Autoencoder for Diverse and Natural Non-Autoregressive Text-to-Speech
Apr 08, 2022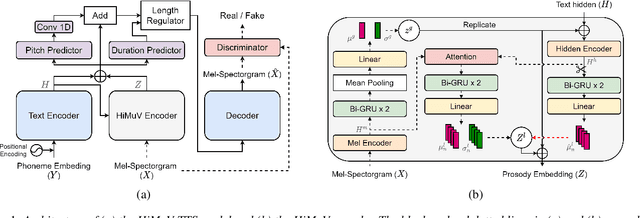
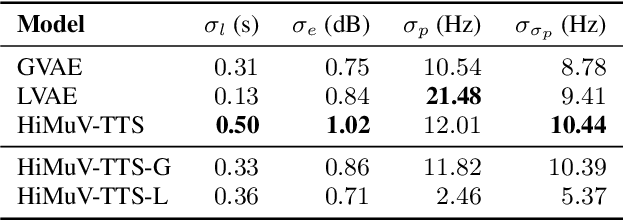
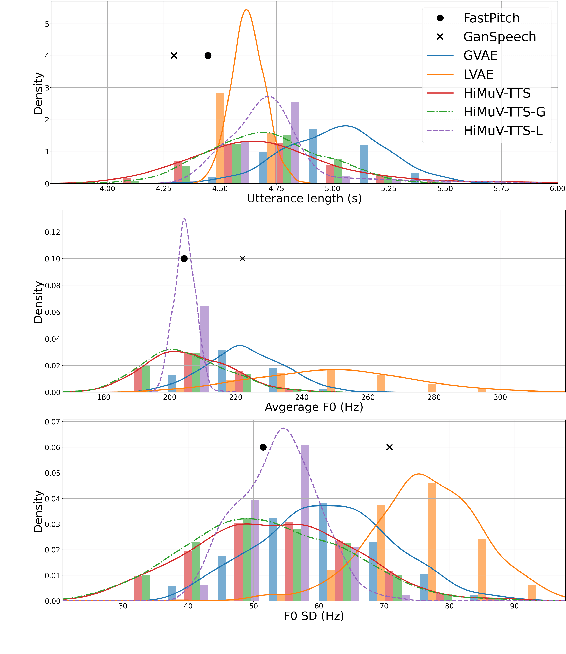
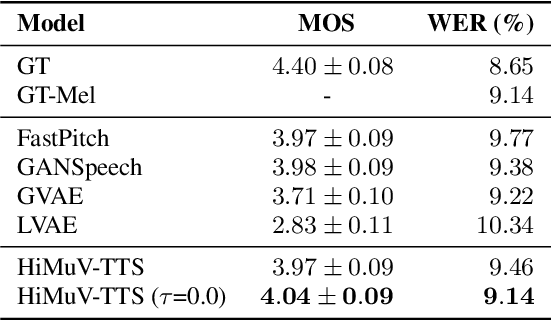
This paper proposes a hierarchical and multi-scale variational autoencoder-based non-autoregressive text-to-speech model (HiMuV-TTS) to generate natural speech with diverse speaking styles. Recent advances in non-autoregressive TTS (NAR-TTS) models have significantly improved the inference speed and robustness of synthesized speech. However, the diversity of speaking styles and naturalness are needed to be improved. To solve this problem, we propose the HiMuV-TTS model that first determines the global-scale prosody and then determines the local-scale prosody via conditioning on the global-scale prosody and the learned text representation. In addition, we improve the quality of speech by adopting the adversarial training technique. Experimental results verify that the proposed HiMuV-TTS model can generate more diverse and natural speech as compared to TTS models with single-scale variational autoencoders, and can represent different prosody information in each scale.
Hierarchical Context-Aware Transformers for Non-Autoregressive Text to Speech
Jun 29, 2021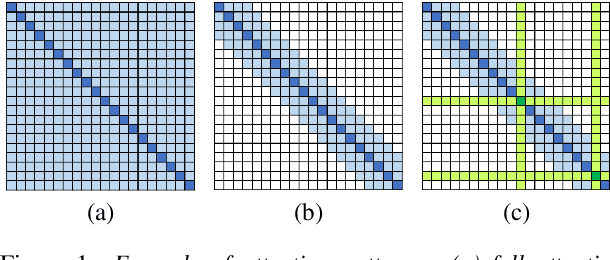
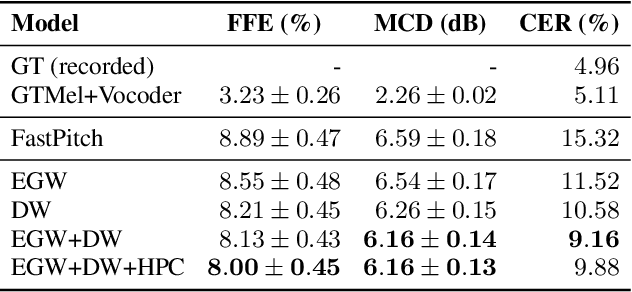
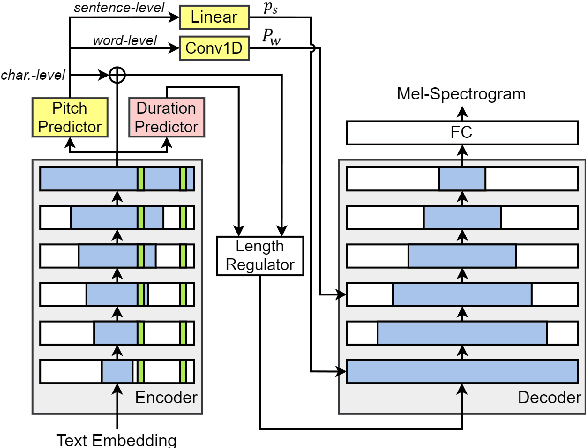
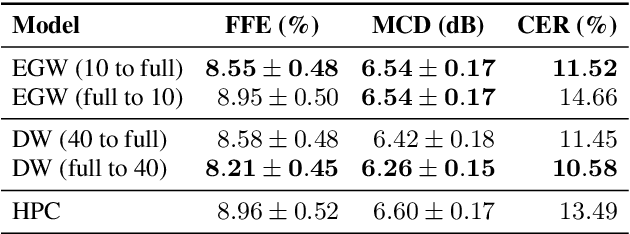
In this paper, we propose methods for improving the modeling performance of a Transformer-based non-autoregressive text-to-speech (TNA-TTS) model. Although the text encoder and audio decoder handle different types and lengths of data (i.e., text and audio), the TNA-TTS models are not designed considering these variations. Therefore, to improve the modeling performance of the TNA-TTS model we propose a hierarchical Transformer structure-based text encoder and audio decoder that are designed to accommodate the characteristics of each module. For the text encoder, we constrain each self-attention layer so the encoder focuses on a text sequence from the local to the global scope. Conversely, the audio decoder constrains its self-attention layers to focus in the reverse direction, i.e., from global to local scope. Additionally, we further improve the pitch modeling accuracy of the audio decoder by providing sentence and word-level pitch as conditions. Various objective and subjective evaluations verified that the proposed method outperformed the baseline TNA-TTS.