 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupertonicTTS: Towards Highly Scalable and Efficient Text-to-Speech System
Mar 29, 2025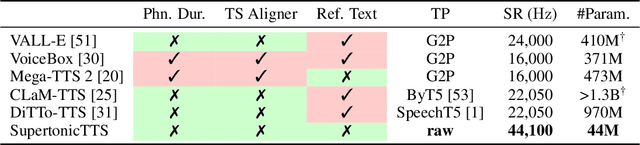
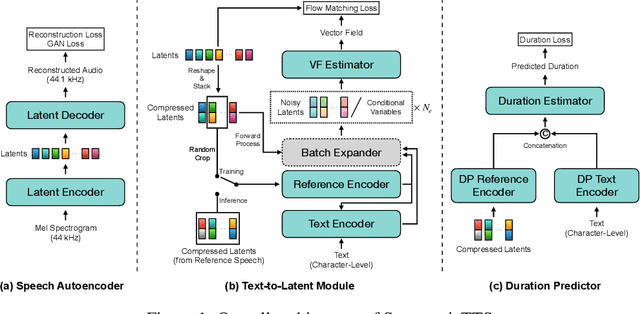

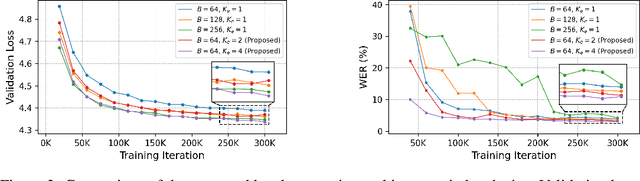
We present a novel text-to-speech (TTS) system, namely SupertonicTTS, for improved scalability and efficiency in speech synthesis. SupertonicTTS is comprised of three components: a speech autoencoder for continuous latent representation, a text-to-latent module leveraging flow-matching for text-to-latent mapping, and an utterance-level duration predictor. To enable a lightweight architecture, we employ a low-dimensional latent space, temporal compression of latents, and ConvNeXt blocks. We further simplify the TTS pipeline by operating directly on raw character-level text and employing cross-attention for text-speech alignment, thus eliminating the need for grapheme-to-phoneme (G2P) modules and external aligners. In addition, we introduce context-sharing batch expansion that accelerates loss convergence and stabilizes text-speech alignment. Experimental results demonstrate that SupertonicTTS achieves competitive performance while significantly reducing architectural complexity and computational overhead compared to contemporary TTS models. Audio samples demonstrating the capabilities of SupertonicTTS are available at: https://supertonictts.github.io/.
Temporal Knowledge Distillation for On-device Audio Classification
Oct 27, 2021



Improving the performance of on-device audio classification models remains a challenge given the computational limits of the mobile environment. Many studies leverage knowledge distillation to boost predictive performance by transferring the knowledge from large models to on-device models. However, most lack the essence of the temporal information which is crucial to audio classification tasks, or similar architecture is often required. In this paper, we propose a new knowledge distillation method designed to incorporate the temporal knowledge embedded in attention weights of large models to on-device models. Our distillation method is applicable to various types of architectures, including the non-attention-based architectures such as CNNs or RNNs, without any architectural change during inference. Through extensive experiments on both an audio event detection dataset and a noisy keyword spotting dataset, we show that our proposed method improves the predictive performance across diverse on-device architectures.