 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobustSpeechFlow: Learning Robust Text-to-Speech Trajectories via Augmentation-based Contrastive Flow Matching
May 21, 2026While flow-matching text-to-speech (TTS) achieves strong zero-shot speaker similarity and naturalness, it remains susceptible to content fidelity issues, particularly skip and repeat errors from imperfect alignment. We propose RobustSpeechFlow, a training strategy that improves alignment robustness by extending contrastive flow matching with length-preserving repeat and skip latent augmentations. Requiring no external aligners or preference data, our method directly penalizes realistic failure modes and readily integrates into existing pipelines. On Seed-TTS-eval, it reduces the word error rate (WER) from 1.44 to 1.38 using only 0.06B parameters. On our ZERO500 benchmark, it delivers consistent intelligibility improvements across diverse speaker and prosody conditions; at NFE=24, it reduces English character error rate (CER) from 0.48\% to 0.35\% and Korean CER from 0.81\% to 0.57\%. Audio samples: https://robustspeechflow.github.io/
SupertonicTTS: Towards Highly Scalable and Efficient Text-to-Speech System
Mar 29, 2025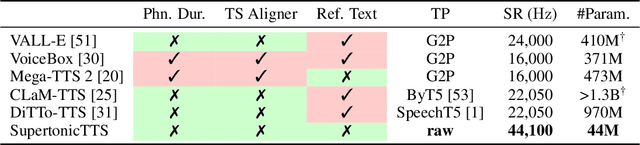
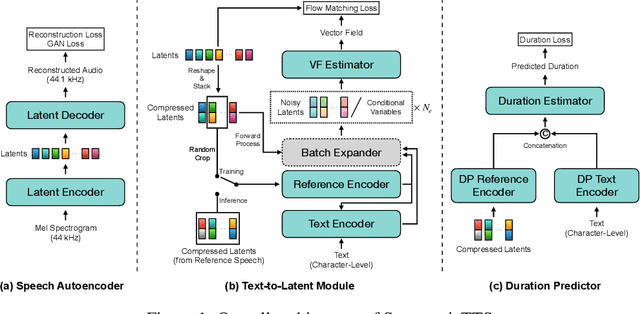

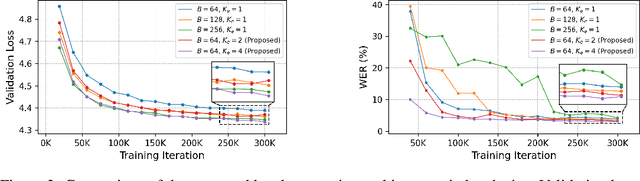
We present a novel text-to-speech (TTS) system, namely SupertonicTTS, for improved scalability and efficiency in speech synthesis. SupertonicTTS is comprised of three components: a speech autoencoder for continuous latent representation, a text-to-latent module leveraging flow-matching for text-to-latent mapping, and an utterance-level duration predictor. To enable a lightweight architecture, we employ a low-dimensional latent space, temporal compression of latents, and ConvNeXt blocks. We further simplify the TTS pipeline by operating directly on raw character-level text and employing cross-attention for text-speech alignment, thus eliminating the need for grapheme-to-phoneme (G2P) modules and external aligners. In addition, we introduce context-sharing batch expansion that accelerates loss convergence and stabilizes text-speech alignment. Experimental results demonstrate that SupertonicTTS achieves competitive performance while significantly reducing architectural complexity and computational overhead compared to contemporary TTS models. Audio samples demonstrating the capabilities of SupertonicTTS are available at: https://supertonictts.github.io/.
GIST-AiTeR System for the Diarization Task of the 2022 VoxCeleb Speaker Recognition Challenge
Oct 06, 2022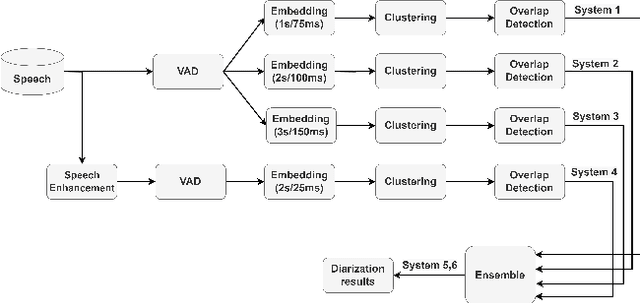
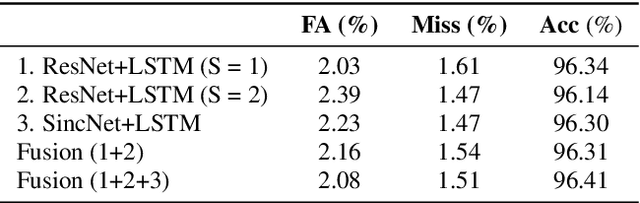
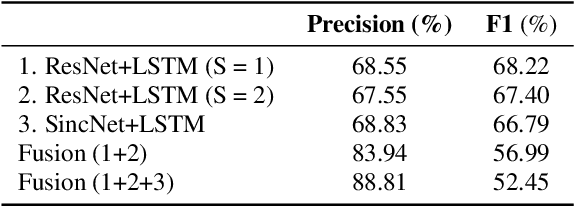

This report describes the submission system of the GIST-AiTeR team at the 2022 VoxCeleb Speaker Recognition Challenge (VoxSRC) Track 4. Our system mainly includes speech enhancement, voice activity detection , multi-scaled speaker embedding, probabilistic linear discriminant analysis-based speaker clustering, and overlapped speech detection models. We first construct four different diarization systems according to different model combinations with the best experimental efforts. Our final submission is an ensemble system of all the four systems and achieves a diarization error rate of 5.12% on the challenge evaluation set, ranked third at the diarization track of the challenge.
Auxiliary Loss of Transformer with Residual Connection for End-to-End Speaker Diarization
Oct 15, 2021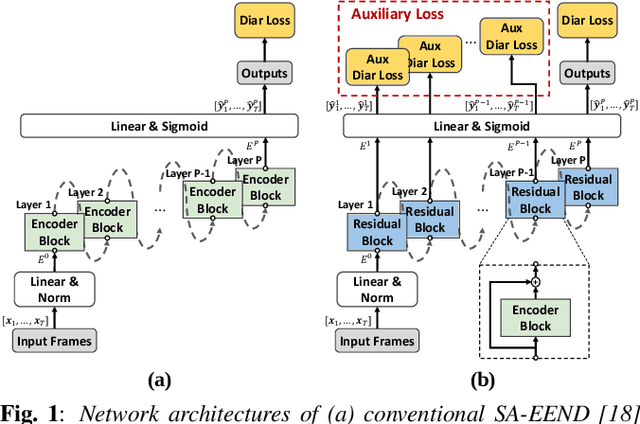
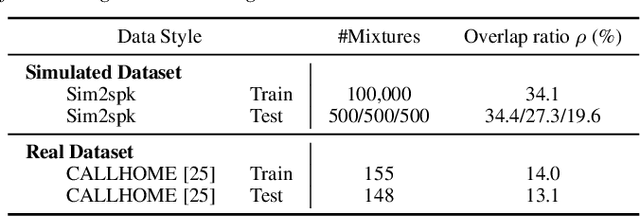
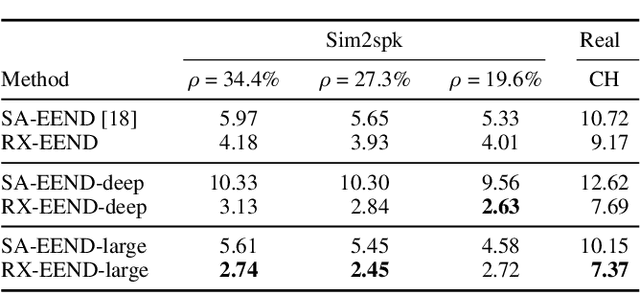
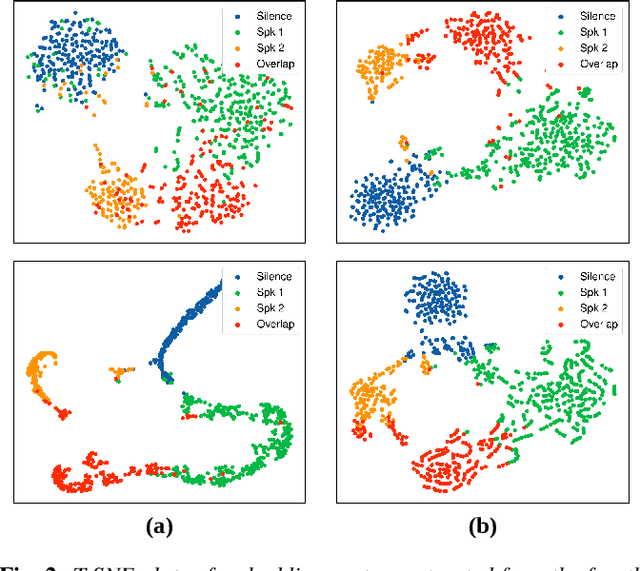
End-to-end neural diarization (EEND) with self-attention directly predicts speaker labels from inputs and enables the handling of overlapped speech. Although the EEND outperforms clustering-based speaker diarization (SD), it cannot be further improved by simply increasing the number of encoder blocks because the last encoder block is dominantly supervised compared with lower blocks. This paper proposes a new residual auxiliary EEND (RX-EEND) learning architecture for transformers to enforce the lower encoder blocks to learn more accurately. The auxiliary loss is applied to the output of each encoder block, including the last encoder block. The effect of auxiliary loss on the learning of the encoder blocks can be further increased by adding a residual connection between the encoder blocks of the EEND. Performance evaluation and ablation study reveal that the auxiliary loss in the proposed RX-EEND provides relative reductions in the diarization error rate (DER) by 50.3% and 21.0% on the simulated and CALLHOME (CH) datasets, respectively, compared with self-attentive EEND (SA-EEND). Furthermore, the residual connection used in RX-EEND further relatively reduces the DER by 8.1% for CH dataset.