 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePS-TTS: Phonetic Synchronization in Text-to-Speech for Achieving Natural Automated Dubbing
Apr 14, 2026Recently, artificial intelligence-based dubbing technology has advanced, enabling automated dubbing (AD) to convert the source speech of a video into target speech in different languages. However, natural AD still faces synchronization challenges such as duration and lip-synchronization (lip-sync), which are crucial for preserving the viewer experience. Therefore, this paper proposes a synchronization method for AD processes that paraphrases translated text, comprising two steps: isochrony for timing constraints and phonetic synchronization (PS) to preserve lip-sync. First, we achieve isochrony by paraphrasing the translated text with a language model, ensuring the target speech duration matches that of the source speech. Second, we introduce PS, which employs dynamic time warping (DTW) with local costs of vowel distances measured from training data so that the target text composes vowels with pronunciations similar to source vowels. Third, we extend this approach to PSComet, which jointly considers semantic and phonetic similarity to preserve meaning better. The proposed methods are incorporated into text-to-speech systems, PS-TTS and PS-Comet TTS. The performance evaluation using Korean and English lip-reading datasets and a voice-actor dubbing dataset demonstrates that both systems outperform TTS without PS on several objective metrics and outperform voice actors in Korean-to-English and English-to-Korean dubbing. We extend the experiments to French, testing all pairs among these languages to evaluate cross-linguistic applicability. Across all language pairs, PS-Comet performed best, balancing lip-sync accuracy with semantic preservation, confirming that PS-Comet achieves more accurate lip-sync with semantic preservation than PS alone.
MolDA: Molecular Understanding and Generation via Large Language Diffusion Model
Apr 07, 2026Large Language Models (LLMs) have significantly advanced molecular discovery, but existing multimodal molecular architectures fundamentally rely on autoregressive (AR) backbones. This strict left-to-right inductive bias is sub-optimal for generating chemically valid molecules, as it struggles to account for non-local global constraints (e.g., ring closures) and often accumulates structural errors during sequential generation. To address these limitations, we propose MolDA (Molecular language model with masked Diffusion with mAsking), a novel multimodal framework that replaces the conventional AR backbone with a discrete Large Language Diffusion Model. MolDA extracts comprehensive structural representations using a hybrid graph encoder, which captures both local and global topologies, and aligns them into the language token space via a Q-Former. Furthermore, we mathematically reformulate Molecular Structure Preference Optimization specifically for the masked diffusion. Through bidirectional iterative denoising, MolDA ensures global structural coherence, chemical validity, and robust reasoning across molecule generation, captioning, and property prediction.
Unlocking Robust Semantic Segmentation Performance via Label-only Elastic Deformations against Implicit Label Noise
Aug 14, 2025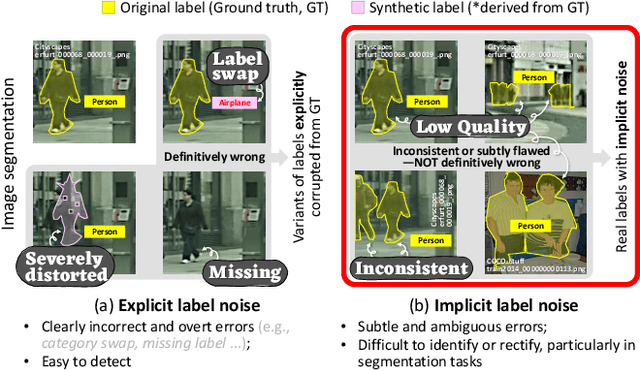
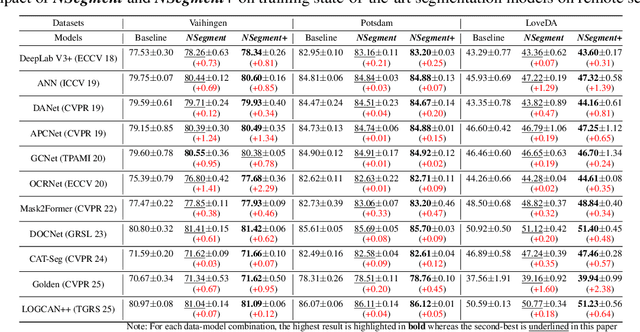


While previous studies on image segmentation focus on handling severe (or explicit) label noise, real-world datasets also exhibit subtle (or implicit) label imperfections. These arise from inherent challenges, such as ambiguous object boundaries and annotator variability. Although not explicitly present, such mild and latent noise can still impair model performance. Typical data augmentation methods, which apply identical transformations to the image and its label, risk amplifying these subtle imperfections and limiting the model's generalization capacity. In this paper, we introduce NSegment+, a novel augmentation framework that decouples image and label transformations to address such realistic noise for semantic segmentation. By introducing controlled elastic deformations only to segmentation labels while preserving the original images, our method encourages models to focus on learning robust representations of object structures despite minor label inconsistencies. Extensive experiments demonstrate that NSegment+ consistently improves performance, achieving mIoU gains of up to +2.29, +2.38, +1.75, and +3.39 in average on Vaihingen, LoveDA, Cityscapes, and PASCAL VOC, respectively-even without bells and whistles, highlighting the importance of addressing implicit label noise. These gains can be further amplified when combined with other training tricks, including CutMix and Label Smoothing.
Performance Improvement of Language-Queried Audio Source Separation Based on Caption Augmentation From Large Language Models for DCASE Challenge 2024 Task 9
Jun 17, 2024We present a prompt-engineering-based text-augmentation approach applied to a language-queried audio source separation (LASS) task. To enhance the performance of LASS, the proposed approach utilizes large language models (LLMs) to generate multiple captions corresponding to each sentence of the training dataset. To this end, we first perform experiments to identify the most effective prompts for caption augmentation with a smaller number of captions. A LASS model trained with these augmented captions demonstrates improved performance on the DCASE 2024 Task 9 validation set compared to that trained without augmentation. This study highlights the effectiveness of LLM-based caption augmentation in advancing language-queried audio source separation.
GIST-AiTeR Speaker Diarization System for VoxCeleb Speaker Recognition Challenge (VoxSRC) 2023
Aug 25, 2023

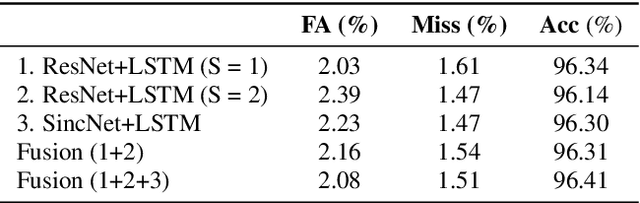
This report describes the submission system by the GIST-AiTeR team for the VoxCeleb Speaker Recognition Challenge 2023 (VoxSRC-23) Track 4. Our submission system focuses on implementing diverse speaker diarization (SD) techniques, including ResNet293 and MFA-Conformer with different combinations of segment and hop length. Then, those models are combined into an ensemble model. The ResNet293 and MFA-Conformer models exhibited the diarization error rates (DERs) of 3.65% and 3.83% on VAL46, respectively. The submitted ensemble model provided a DER of 3.50% on VAL46, and consequently, it achieved a DER of 4.88% on the VoxSRC-23 test set.
Semi-supervsied Learning-based Sound Event Detection using Freuqency Dynamic Convolution with Large Kernel Attention for DCASE Challenge 2023 Task 4
Jun 10, 2023This report proposes a frequency dynamic convolution (FDY) with a large kernel attention (LKA)-convolutional recurrent neural network (CRNN) with a pre-trained bidirectional encoder representation from audio transformers (BEATs) embedding-based sound event detection (SED) model that employs a mean-teacher and pseudo-label approach to address the challenge of limited labeled data for DCASE 2023 Task 4. The proposed FDY with LKA integrates the FDY and LKA module to effectively capture time-frequency patterns, long-term dependencies, and high-level semantic information in audio signals. The proposed FDY with LKA-CRNN with a BEATs embedding network is initially trained on the entire DCASE 2023 Task 4 dataset using the mean-teacher approach, generating pseudo-labels for weakly labeled, unlabeled, and the AudioSet. Subsequently, the proposed SED model is retrained using the same pseudo-label approach. A subset of these models is selected for submission, demonstrating superior F1-scores and polyphonic SED score performance on the DCASE 2023 Challenge Task 4 validation dataset.
GIST-AiTeR System for the Diarization Task of the 2022 VoxCeleb Speaker Recognition Challenge
Oct 06, 2022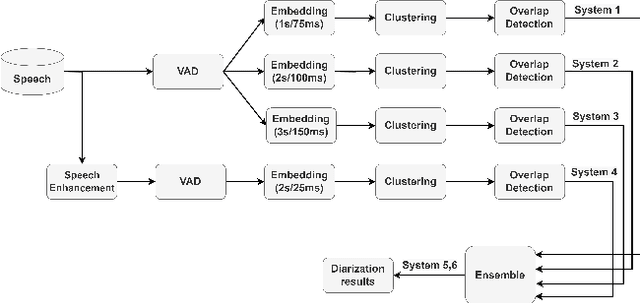
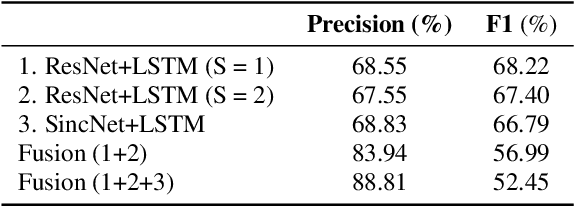

This report describes the submission system of the GIST-AiTeR team at the 2022 VoxCeleb Speaker Recognition Challenge (VoxSRC) Track 4. Our system mainly includes speech enhancement, voice activity detection , multi-scaled speaker embedding, probabilistic linear discriminant analysis-based speaker clustering, and overlapped speech detection models. We first construct four different diarization systems according to different model combinations with the best experimental efforts. Our final submission is an ensemble system of all the four systems and achieves a diarization error rate of 5.12% on the challenge evaluation set, ranked third at the diarization track of the challenge.
Auxiliary Loss of Transformer with Residual Connection for End-to-End Speaker Diarization
Oct 15, 2021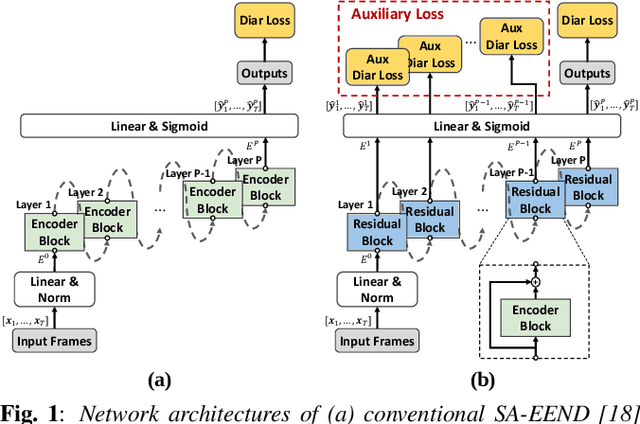
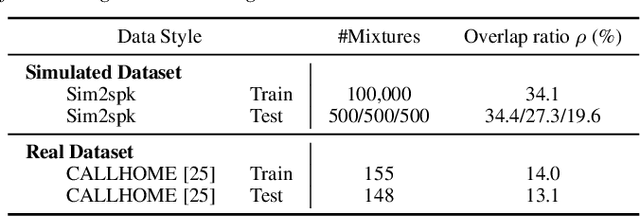
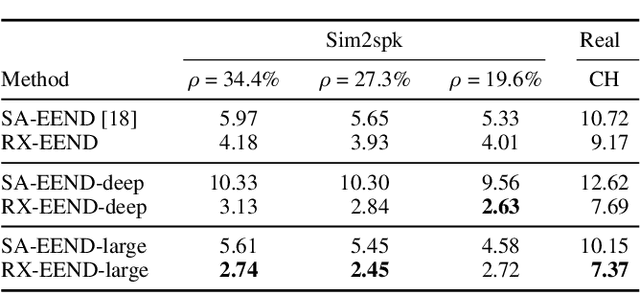
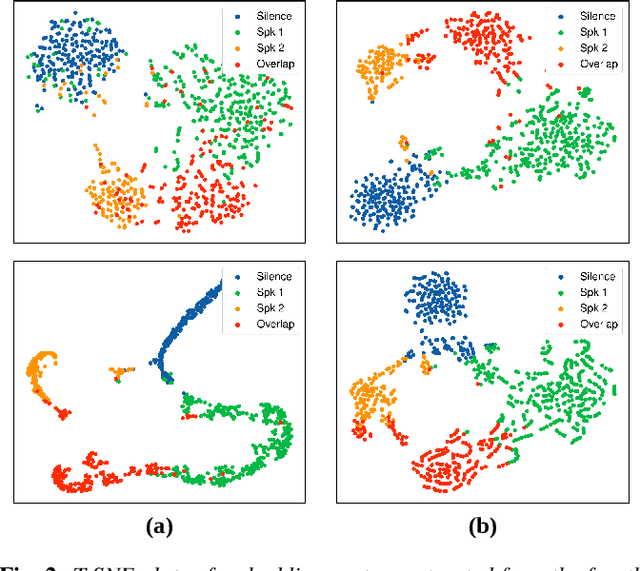
End-to-end neural diarization (EEND) with self-attention directly predicts speaker labels from inputs and enables the handling of overlapped speech. Although the EEND outperforms clustering-based speaker diarization (SD), it cannot be further improved by simply increasing the number of encoder blocks because the last encoder block is dominantly supervised compared with lower blocks. This paper proposes a new residual auxiliary EEND (RX-EEND) learning architecture for transformers to enforce the lower encoder blocks to learn more accurately. The auxiliary loss is applied to the output of each encoder block, including the last encoder block. The effect of auxiliary loss on the learning of the encoder blocks can be further increased by adding a residual connection between the encoder blocks of the EEND. Performance evaluation and ablation study reveal that the auxiliary loss in the proposed RX-EEND provides relative reductions in the diarization error rate (DER) by 50.3% and 21.0% on the simulated and CALLHOME (CH) datasets, respectively, compared with self-attentive EEND (SA-EEND). Furthermore, the residual connection used in RX-EEND further relatively reduces the DER by 8.1% for CH dataset.
Self-training with noisy student model and semi-supervised loss function for dcase 2021 challenge task 4
Jul 06, 2021
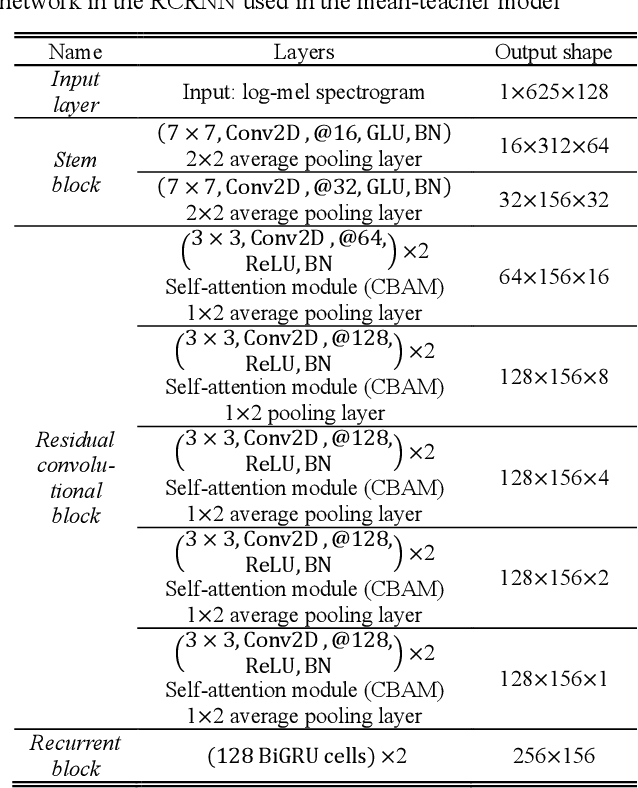

This report proposes a polyphonic sound event detection (SED) method for the DCASE 2021 Challenge Task 4. The proposed SED model consists of two stages: a mean-teacher model for providing target labels regarding weakly labeled or unlabeled data and a self-training-based noisy student model for predicting strong labels for sound events. The mean-teacher model, which is based on the residual convolutional recurrent neural network (RCRNN) for the teacher and student model, is first trained using all the training data from a weakly labeled dataset, an unlabeled dataset, and a strongly labeled synthetic dataset. Then, the trained mean-teacher model predicts the strong label to each of the weakly labeled and unlabeled datasets, which is brought to the noisy student model in the second stage of the proposed SED model. Here, the structure of the noisy student model is identical to the RCRNN-based student model of the mean-teacher model in the first stage. Then, it is self-trained by adding feature noises, such as time-frequency shift, mixup, SpecAugment, and dropout-based model noise. In addition, a semi-supervised loss function is applied to train the noisy student model, which acts as label noise injection. The performance of the proposed SED model is evaluated on the validation set of the DCASE 2021 Challenge Task 4, and then, several ensemble models that combine five-fold validation models with different hyperparameters of the semi-supervised loss function are finally selected as our final models.