 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuxiliary Loss of Transformer with Residual Connection for End-to-End Speaker Diarization
Paper and Code
Oct 15, 2021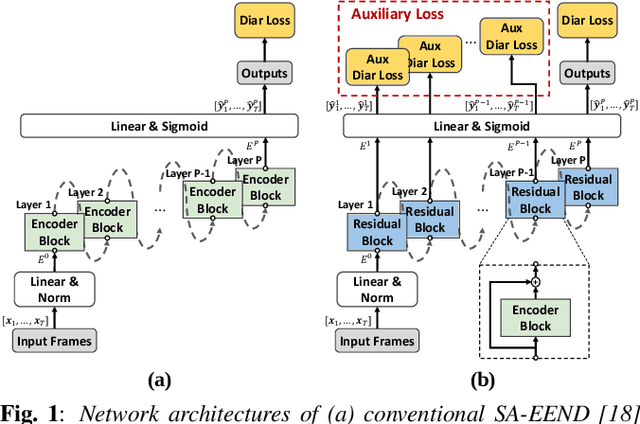
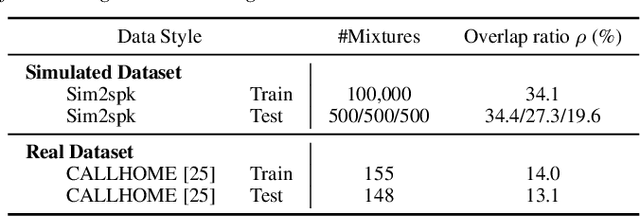
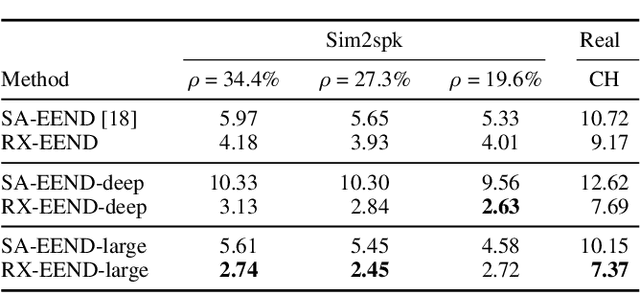
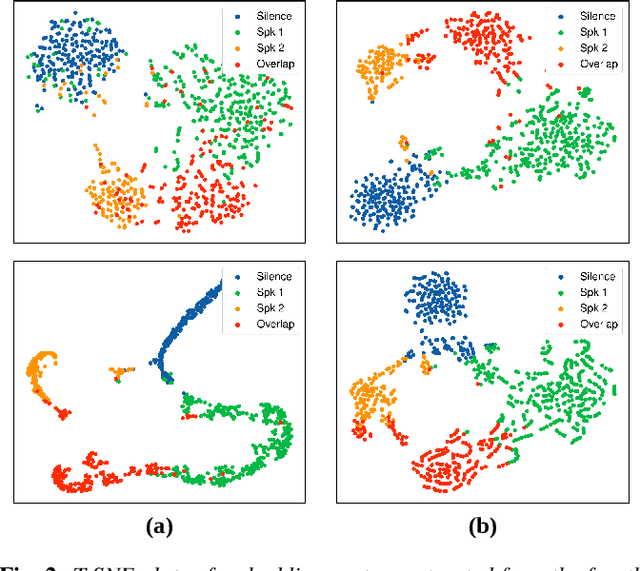
End-to-end neural diarization (EEND) with self-attention directly predicts speaker labels from inputs and enables the handling of overlapped speech. Although the EEND outperforms clustering-based speaker diarization (SD), it cannot be further improved by simply increasing the number of encoder blocks because the last encoder block is dominantly supervised compared with lower blocks. This paper proposes a new residual auxiliary EEND (RX-EEND) learning architecture for transformers to enforce the lower encoder blocks to learn more accurately. The auxiliary loss is applied to the output of each encoder block, including the last encoder block. The effect of auxiliary loss on the learning of the encoder blocks can be further increased by adding a residual connection between the encoder blocks of the EEND. Performance evaluation and ablation study reveal that the auxiliary loss in the proposed RX-EEND provides relative reductions in the diarization error rate (DER) by 50.3% and 21.0% on the simulated and CALLHOME (CH) datasets, respectively, compared with self-attentive EEND (SA-EEND). Furthermore, the residual connection used in RX-EEND further relatively reduces the DER by 8.1% for CH dataset.