 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGIST-AiTeR Speaker Diarization System for VoxCeleb Speaker Recognition Challenge (VoxSRC) 2023
Aug 25, 2023

This report describes the submission system by the GIST-AiTeR team for the VoxCeleb Speaker Recognition Challenge 2023 (VoxSRC-23) Track 4. Our submission system focuses on implementing diverse speaker diarization (SD) techniques, including ResNet293 and MFA-Conformer with different combinations of segment and hop length. Then, those models are combined into an ensemble model. The ResNet293 and MFA-Conformer models exhibited the diarization error rates (DERs) of 3.65% and 3.83% on VAL46, respectively. The submitted ensemble model provided a DER of 3.50% on VAL46, and consequently, it achieved a DER of 4.88% on the VoxSRC-23 test set.
Semi-supervsied Learning-based Sound Event Detection using Freuqency Dynamic Convolution with Large Kernel Attention for DCASE Challenge 2023 Task 4
Jun 10, 2023This report proposes a frequency dynamic convolution (FDY) with a large kernel attention (LKA)-convolutional recurrent neural network (CRNN) with a pre-trained bidirectional encoder representation from audio transformers (BEATs) embedding-based sound event detection (SED) model that employs a mean-teacher and pseudo-label approach to address the challenge of limited labeled data for DCASE 2023 Task 4. The proposed FDY with LKA integrates the FDY and LKA module to effectively capture time-frequency patterns, long-term dependencies, and high-level semantic information in audio signals. The proposed FDY with LKA-CRNN with a BEATs embedding network is initially trained on the entire DCASE 2023 Task 4 dataset using the mean-teacher approach, generating pseudo-labels for weakly labeled, unlabeled, and the AudioSet. Subsequently, the proposed SED model is retrained using the same pseudo-label approach. A subset of these models is selected for submission, demonstrating superior F1-scores and polyphonic SED score performance on the DCASE 2023 Challenge Task 4 validation dataset.
GIST-AiTeR System for the Diarization Task of the 2022 VoxCeleb Speaker Recognition Challenge
Oct 06, 2022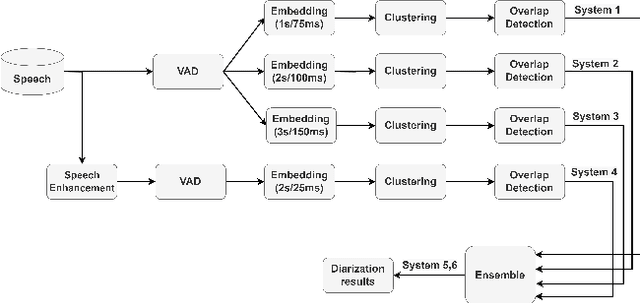
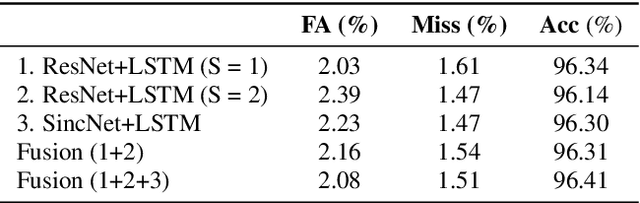
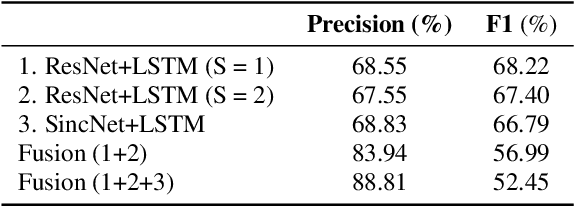

This report describes the submission system of the GIST-AiTeR team at the 2022 VoxCeleb Speaker Recognition Challenge (VoxSRC) Track 4. Our system mainly includes speech enhancement, voice activity detection , multi-scaled speaker embedding, probabilistic linear discriminant analysis-based speaker clustering, and overlapped speech detection models. We first construct four different diarization systems according to different model combinations with the best experimental efforts. Our final submission is an ensemble system of all the four systems and achieves a diarization error rate of 5.12% on the challenge evaluation set, ranked third at the diarization track of the challenge.
On Measuring Gender Bias in Translation of Gender-neutral Pronouns
May 28, 2019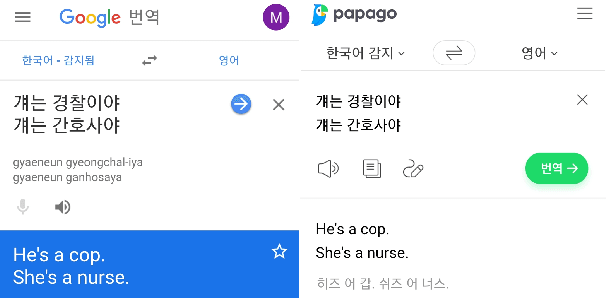
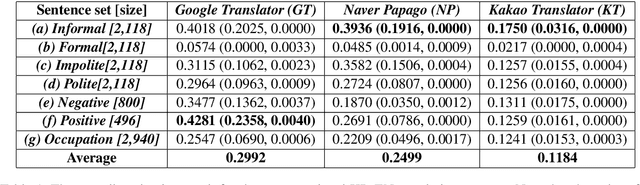
Ethics regarding social bias has recently thrown striking issues in natural language processing. Especially for gender-related topics, the need for a system that reduces the model bias has grown in areas such as image captioning, content recommendation, and automated employment. However, detection and evaluation of gender bias in the machine translation systems are not yet thoroughly investigated, for the task being cross-lingual and challenging to define. In this paper, we propose a scheme for making up a test set that evaluates the gender bias in a machine translation system, with Korean, a language with gender-neutral pronouns. Three word/phrase sets are primarily constructed, each incorporating positive/negative expressions or occupations; all the terms are gender-independent or at least not biased to one side severely. Then, additional sentence lists are constructed concerning formality of the pronouns and politeness of the sentences. With the generated sentence set of size 4,236 in total, we evaluate gender bias in conventional machine translation systems utilizing the proposed measure, which is termed here as translation gender bias index (TGBI). The corpus and the code for evaluation is available on-line.
Real-time Automatic Word Segmentation for User-generated Text
Oct 31, 2018
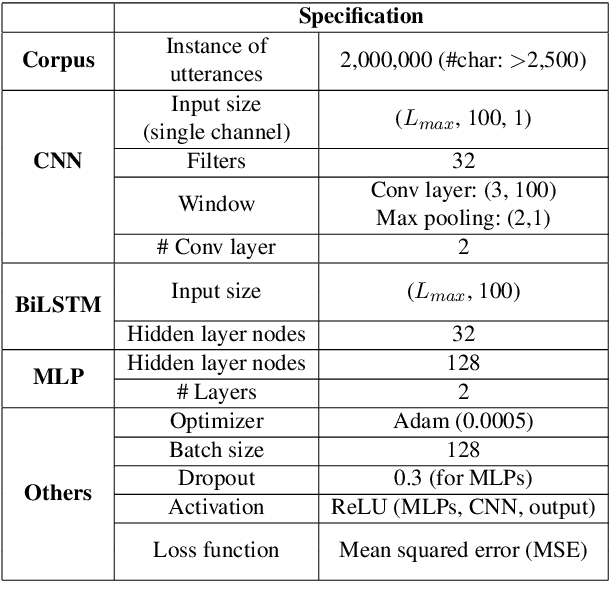
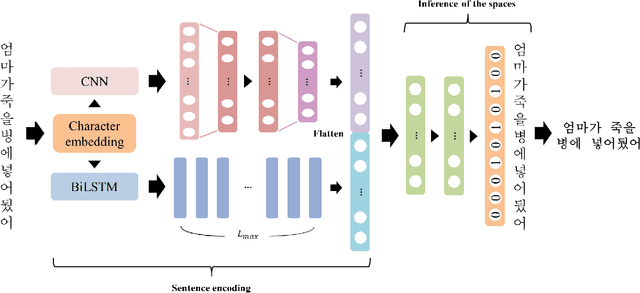
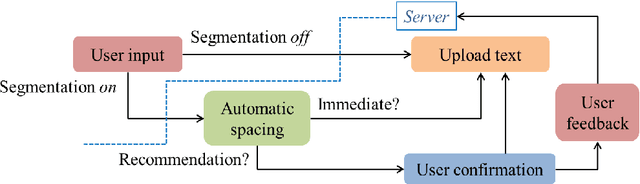
For readability and possibly for disambiguation, appropriate word segmentation is recommended for written text. In this paper, we propose a real-time assistive technology that utilizes an automatic segmentation. The language primarily investigated is Korean, a head-final language with the various morpho-syllabic blocks as a character set. The training scheme is fully neural network-based and extensible to other languages, as is implemented in this study for English. Besides, we show how the proposed system can be utilized in a web-based fine-tuning for a user-generated text. With a qualitative and quantitative comparison with widely used text processing toolkits, we show the reliability of the proposed system and how it fits with conversation-style and non-canonical texts. Demonstration for both languages is freely available online.