 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-time Automatic Word Segmentation for User-generated Text
Paper and Code

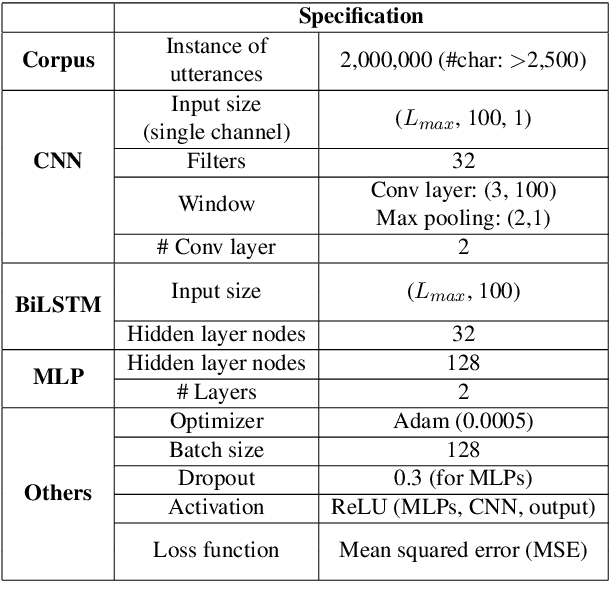
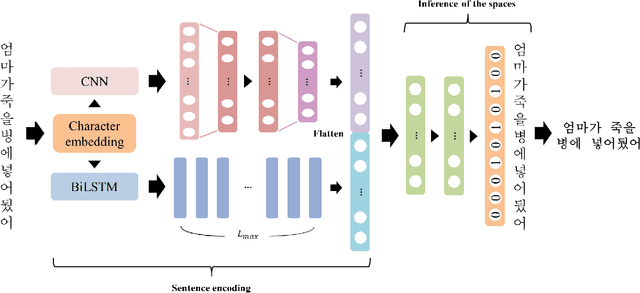
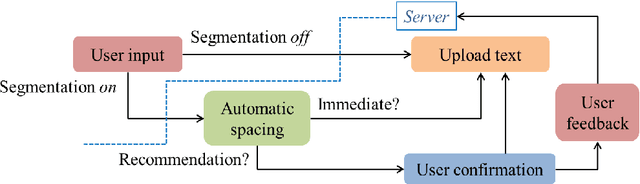
For readability and possibly for disambiguation, appropriate word segmentation is recommended for written text. In this paper, we propose a real-time assistive technology that utilizes an automatic segmentation. The language primarily investigated is Korean, a head-final language with the various morpho-syllabic blocks as a character set. The training scheme is fully neural network-based and extensible to other languages, as is implemented in this study for English. Besides, we show how the proposed system can be utilized in a web-based fine-tuning for a user-generated text. With a qualitative and quantitative comparison with widely used text processing toolkits, we show the reliability of the proposed system and how it fits with conversation-style and non-canonical texts. Demonstration for both languages is freely available online.