 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttentive activation function for improving end-to-end spoofing countermeasure systems
May 03, 2022
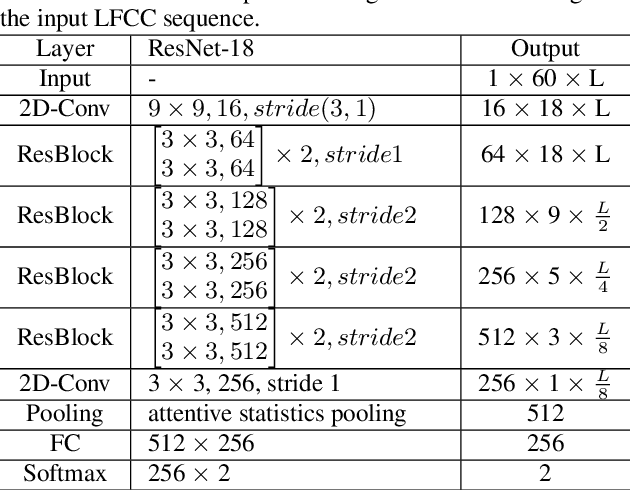
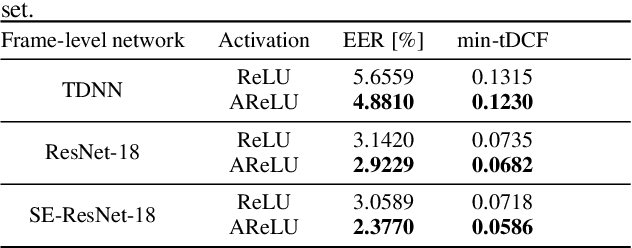
The main objective of the spoofing countermeasure system is to detect the artifacts within the input speech caused by the speech synthesis or voice conversion process. In order to achieve this, we propose to adopt an attentive activation function, more specifically attention rectified linear unit (AReLU) to the end-to-end spoofing countermeasure system. Since the AReLU employs the attention mechanism to boost the contribution of relevant input features while suppressing the irrelevant ones, introducing AReLU can help the countermeasure system to focus on the features related to the artifacts. The proposed framework was experimented on the logical access (LA) task of ASVSpoof2019 dataset, and outperformed the systems using the standard non-learnable activation functions.
Robust Speech Representation Learning via Flow-based Embedding Regularization
Dec 07, 2021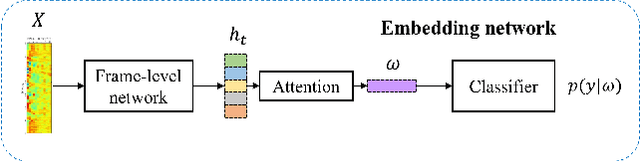

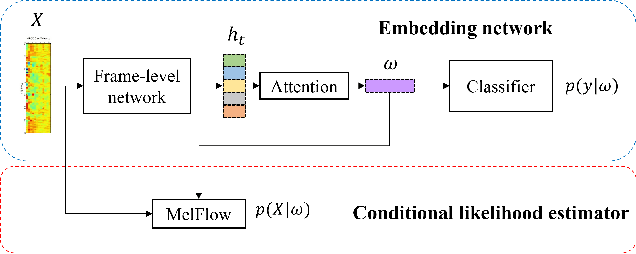
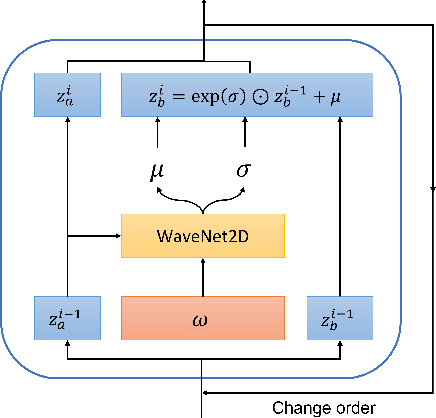
Over the recent years, various deep learning-based methods were proposed for extracting a fixed-dimensional embedding vector from speech signals. Although the deep learning-based embedding extraction methods have shown good performance in numerous tasks including speaker verification, language identification and anti-spoofing, their performance is limited when it comes to mismatched conditions due to the variability within them unrelated to the main task. In order to alleviate this problem, we propose a novel training strategy that regularizes the embedding network to have minimum information about the nuisance attributes. To achieve this, our proposed method directly incorporates the information bottleneck scheme into the training process, where the mutual information is estimated using the main task classifier and an auxiliary normalizing flow network. The proposed method was evaluated on different speech processing tasks and showed improvement over the standard training strategy in all experimentation.
Continuous Monitoring of Blood Pressure with Evidential Regression
Feb 26, 2021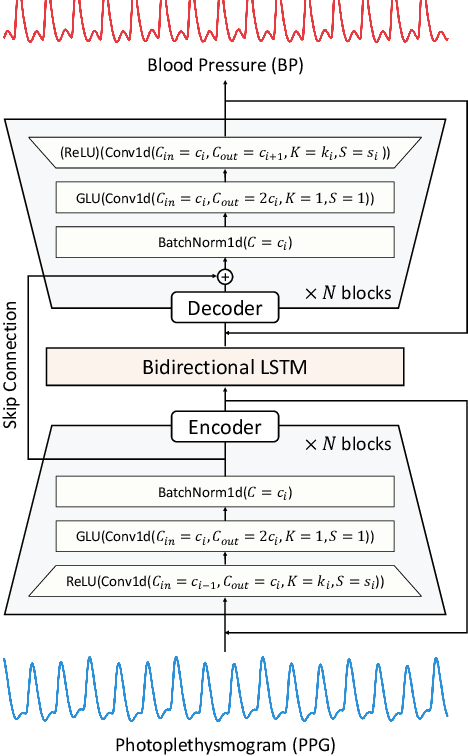
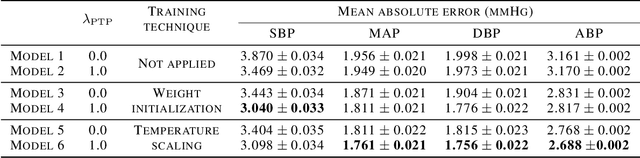
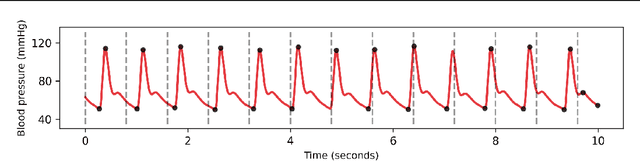
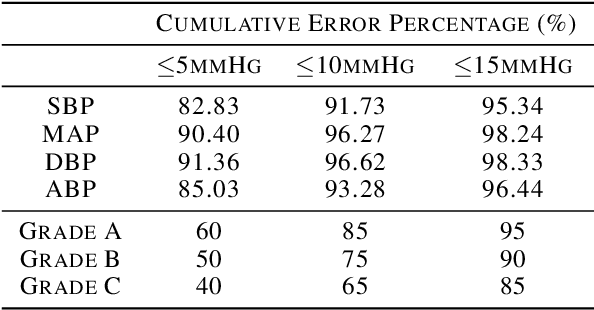
Photoplethysmogram (PPG) signal-based blood pressure (BP) estimation is a promising candidate for modern BP measurements, as PPG signals can be easily obtained from wearable devices in a non-invasive manner, allowing quick BP measurement. However, the performance of existing machine learning-based BP measuring methods still fall behind some BP measurement guidelines and most of them provide only point estimates of systolic blood pressure (SBP) and diastolic blood pressure (DBP). In this paper, we present a cutting-edge method which is capable of continuously monitoring BP from the PPG signal and satisfies healthcare criteria such as the Association for the Advancement of Medical Instrumentation (AAMI) and the British Hypertension Society (BHS) standards. Furthermore, the proposed method provides the reliability of the predicted BP by estimating its uncertainty to help diagnose medical condition based on the model prediction. Experiments on the MIMIC II database verify the state-of-the-art performance of the proposed method under several metrics and its ability to accurately represent uncertainty in prediction.
WaveNODE: A Continuous Normalizing Flow for Speech Synthesis
Jul 02, 2020
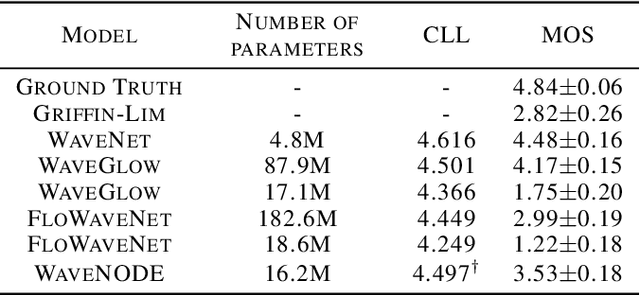
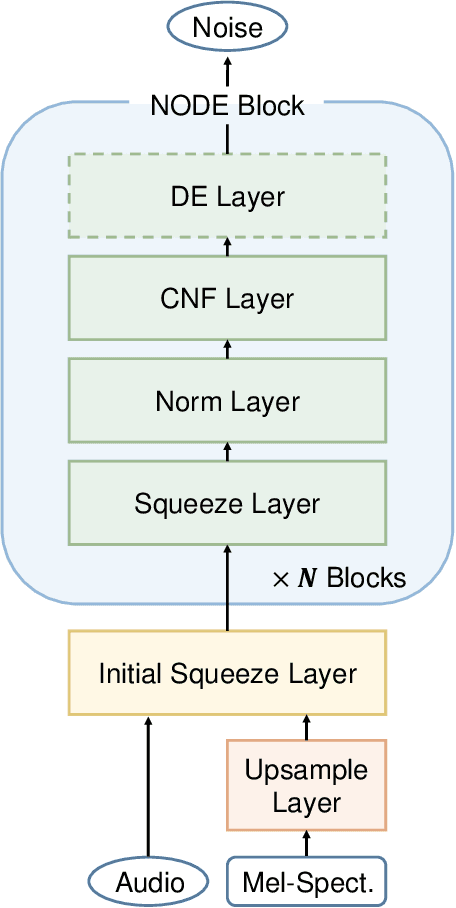

In recent years, various flow-based generative models have been proposed to generate high-fidelity waveforms in real-time. However, these models require either a well-trained teacher network or a number of flow steps making them memory-inefficient. In this paper, we propose a novel generative model called WaveNODE which exploits a continuous normalizing flow for speech synthesis. Unlike the conventional models, WaveNODE places no constraint on the function used for flow operation, thus allowing the usage of more flexible and complex functions. Moreover, WaveNODE can be optimized to maximize the likelihood without requiring any teacher network or auxiliary loss terms. We experimentally show that WaveNODE achieves comparable performance with fewer parameters compared to the conventional flow-based vocoders.
SoftFlow: Probabilistic Framework for Normalizing Flow on Manifolds
Jun 09, 2020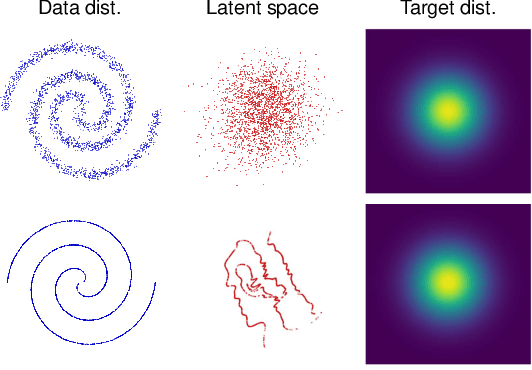
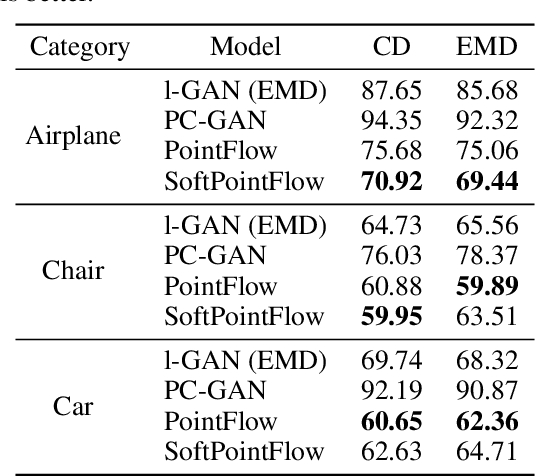
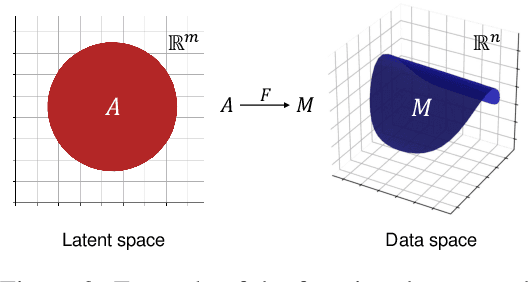

Flow-based generative models are composed of invertible transformations between two random variables of the same dimension. Therefore, flow-based models cannot be adequately trained if the dimension of the data distribution does not match that of the underlying target distribution. In this paper, we propose SoftFlow, a probabilistic framework for training normalizing flows on manifolds. To sidestep the dimension mismatch problem, SoftFlow estimates a conditional distribution of the perturbed input data instead of learning the data distribution directly. We experimentally show that SoftFlow can capture the innate structure of the manifold data and generate high-quality samples unlike the conventional flow-based models. Furthermore, we apply the proposed framework to 3D point clouds to alleviate the difficulty of forming thin structures for flow-based models. The proposed model for 3D point clouds, namely SoftPointFlow, can estimate the distribution of various shapes more accurately and achieves state-of-the-art performance in point cloud generation.
Disambiguating Speech Intention via Audio-Text Co-attention Framework: A Case of Prosody-semantics Interface
Oct 21, 2019
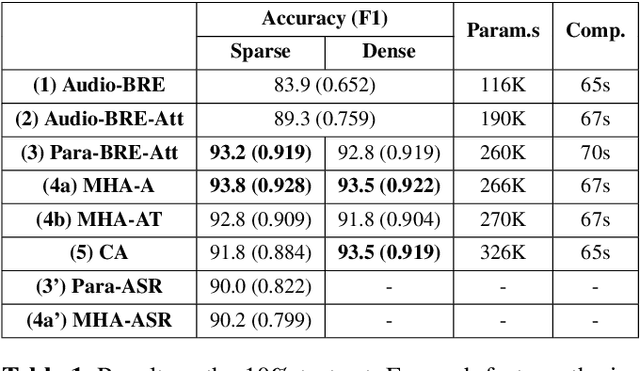
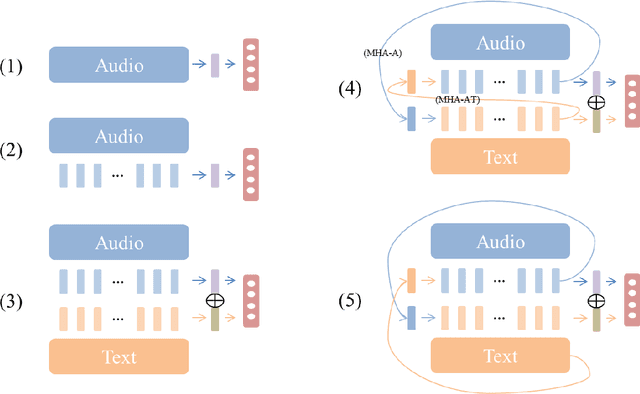
Understanding the intention of an utterance is challenging for some prosody-sensitive cases, especially when it is in the written form. The main concern is to detect the directivity or rhetoricalness of an utterance and to distinguish the type of question. Since it is inevitable to face both the issues regarding prosody and semantics, the identification is expected to benefit from the observations of human language processing mechanism. In this paper, we combat the task with attentive recurrent neural networks that exploit acoustic and textual features, using a manually created speech corpus that incorporates only the syntactically ambiguous utterances which require prosody for disambiguation. We found out that co-attention frameworks on audio-text data, namely multi-hop attention and cross-attention, can perform better than previously suggested speech-based/text-aided networks. By this, we infer that understanding the genuine intention of the ambiguous utterances incorporates recognizing the interaction between auditory and linguistic processes.
Real-time Automatic Word Segmentation for User-generated Text
Oct 31, 2018
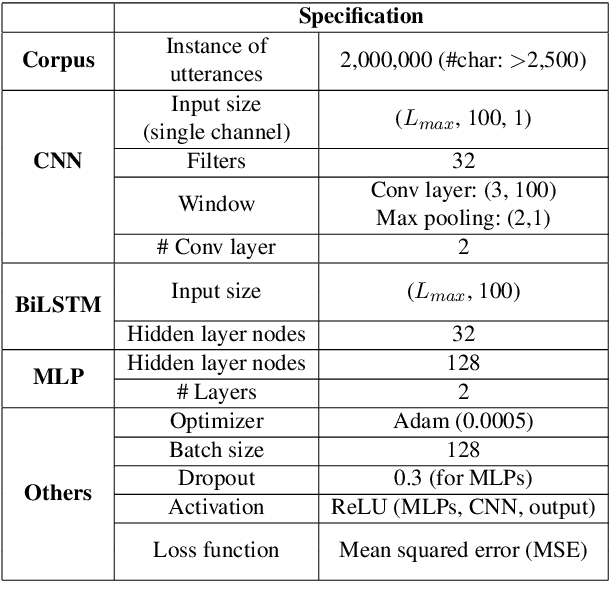
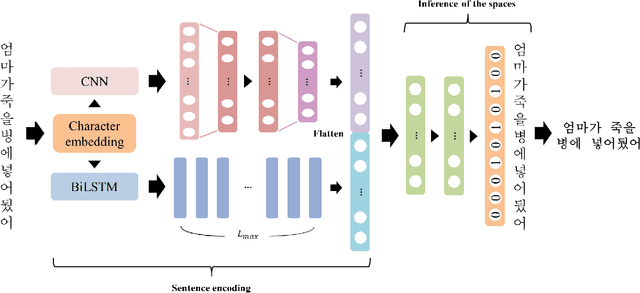
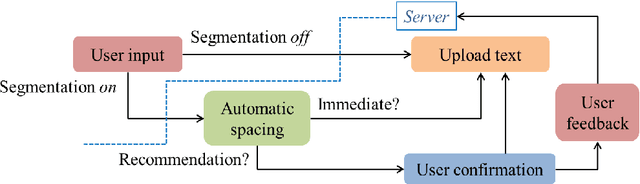
For readability and possibly for disambiguation, appropriate word segmentation is recommended for written text. In this paper, we propose a real-time assistive technology that utilizes an automatic segmentation. The language primarily investigated is Korean, a head-final language with the various morpho-syllabic blocks as a character set. The training scheme is fully neural network-based and extensible to other languages, as is implemented in this study for English. Besides, we show how the proposed system can be utilized in a web-based fine-tuning for a user-generated text. With a qualitative and quantitative comparison with widely used text processing toolkits, we show the reliability of the proposed system and how it fits with conversation-style and non-canonical texts. Demonstration for both languages is freely available online.
Structured Argument Extraction of Korean Question and Command
Oct 10, 2018

Intention identification and slot filling is a core issue in dialog management. However, due to the non-canonicality of the spoken language, it is difficult to extract the content automatically from the conversation-style utterances. This is much harder for languages like Korean and Japanese since the agglutination between morphemes make it difficult for the machines to parse the sentence and understand the intention. In order to suggest a guideline to this problem, inspired by the neural summarization systems introduced recently, we propose a structured annotation scheme for Korean questions/commands which is widely applicable to the field of argument extraction. For further usage, the corpus is additionally tagged with general-linguistic syntactical informations.