 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Speech Representation Learning via Flow-based Embedding Regularization
Paper and Code
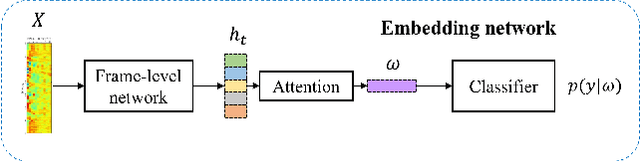

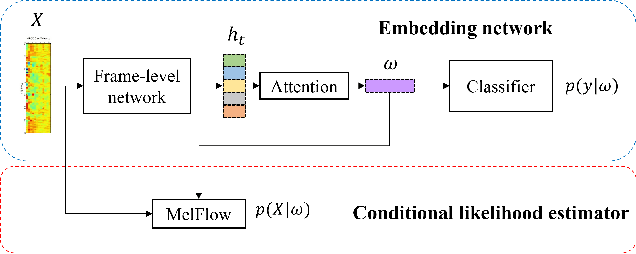
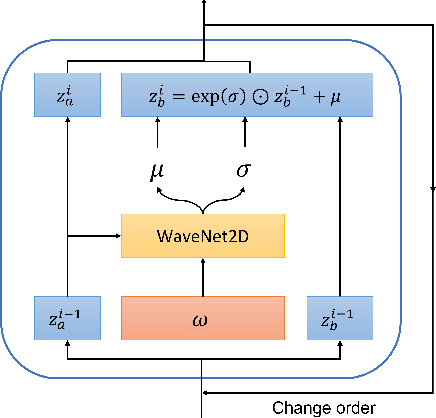
Over the recent years, various deep learning-based methods were proposed for extracting a fixed-dimensional embedding vector from speech signals. Although the deep learning-based embedding extraction methods have shown good performance in numerous tasks including speaker verification, language identification and anti-spoofing, their performance is limited when it comes to mismatched conditions due to the variability within them unrelated to the main task. In order to alleviate this problem, we propose a novel training strategy that regularizes the embedding network to have minimum information about the nuisance attributes. To achieve this, our proposed method directly incorporates the information bottleneck scheme into the training process, where the mutual information is estimated using the main task classifier and an auxiliary normalizing flow network. The proposed method was evaluated on different speech processing tasks and showed improvement over the standard training strategy in all experimentation.