 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttentive activation function for improving end-to-end spoofing countermeasure systems
May 03, 2022
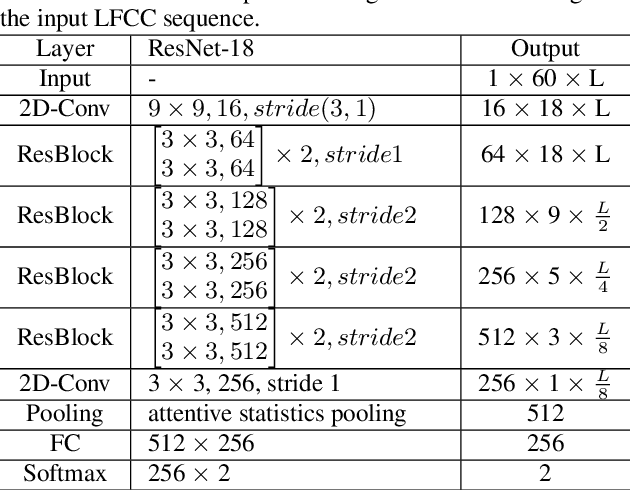
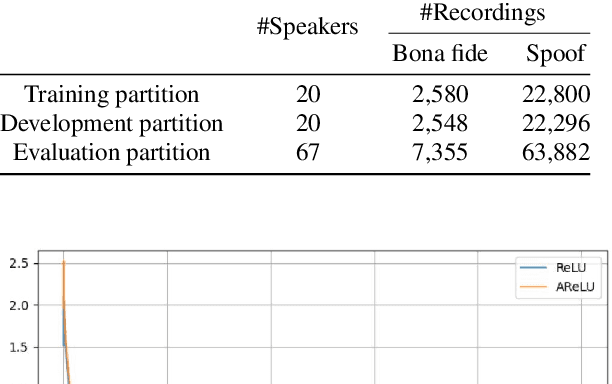
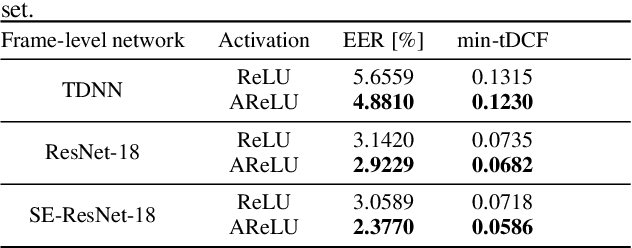
The main objective of the spoofing countermeasure system is to detect the artifacts within the input speech caused by the speech synthesis or voice conversion process. In order to achieve this, we propose to adopt an attentive activation function, more specifically attention rectified linear unit (AReLU) to the end-to-end spoofing countermeasure system. Since the AReLU employs the attention mechanism to boost the contribution of relevant input features while suppressing the irrelevant ones, introducing AReLU can help the countermeasure system to focus on the features related to the artifacts. The proposed framework was experimented on the logical access (LA) task of ASVSpoof2019 dataset, and outperformed the systems using the standard non-learnable activation functions.
Robust Speech Representation Learning via Flow-based Embedding Regularization
Dec 07, 2021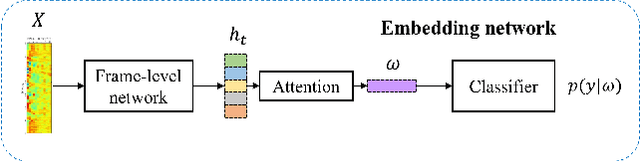

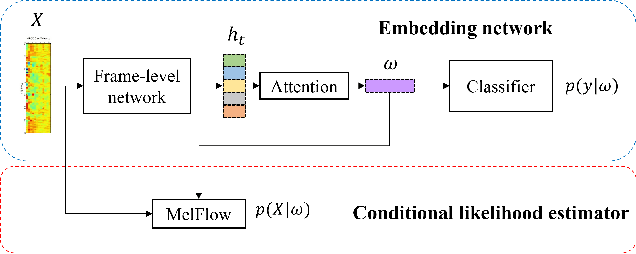
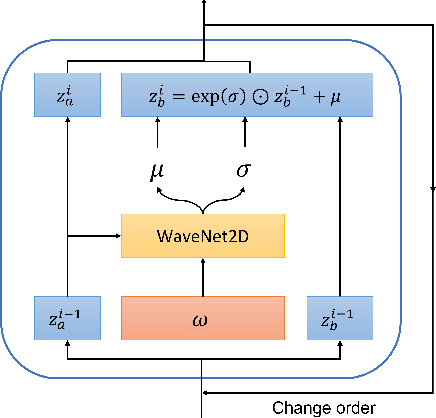
Over the recent years, various deep learning-based methods were proposed for extracting a fixed-dimensional embedding vector from speech signals. Although the deep learning-based embedding extraction methods have shown good performance in numerous tasks including speaker verification, language identification and anti-spoofing, their performance is limited when it comes to mismatched conditions due to the variability within them unrelated to the main task. In order to alleviate this problem, we propose a novel training strategy that regularizes the embedding network to have minimum information about the nuisance attributes. To achieve this, our proposed method directly incorporates the information bottleneck scheme into the training process, where the mutual information is estimated using the main task classifier and an auxiliary normalizing flow network. The proposed method was evaluated on different speech processing tasks and showed improvement over the standard training strategy in all experimentation.
Deep Reinforcement Learning for Optimal Stopping with Application in Financial Engineering
May 19, 2021


Optimal stopping is the problem of deciding the right time at which to take a particular action in a stochastic system, in order to maximize an expected reward. It has many applications in areas such as finance, healthcare, and statistics. In this paper, we employ deep Reinforcement Learning (RL) to learn optimal stopping policies in two financial engineering applications: namely option pricing, and optimal option exercise. We present for the first time a comprehensive empirical evaluation of the quality of optimal stopping policies identified by three state of the art deep RL algorithms: double deep Q-learning (DDQN), categorical distributional RL (C51), and Implicit Quantile Networks (IQN). In the case of option pricing, our findings indicate that in a theoretical Black-Schole environment, IQN successfully identifies nearly optimal prices. On the other hand, it is slightly outperformed by C51 when confronted to real stock data movements in a put option exercise problem that involves assets from the S&P500 index. More importantly, the C51 algorithm is able to identify an optimal stopping policy that achieves 8% more out-of-sample returns than the best of four natural benchmark policies. We conclude with a discussion of our findings which should pave the way for relevant future research.