 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegINR: Segment-wise Implicit Neural Representation for Sequence Alignment in Neural Text-to-Speech
Oct 07, 2024



We present SegINR, a novel approach to neural Text-to-Speech (TTS) that addresses sequence alignment without relying on an auxiliary duration predictor and complex autoregressive (AR) or non-autoregressive (NAR) frame-level sequence modeling. SegINR simplifies the process by converting text sequences directly into frame-level features. It leverages an optimal text encoder to extract embeddings, transforming each into a segment of frame-level features using a conditional implicit neural representation (INR). This method, named segment-wise INR (SegINR), models temporal dynamics within each segment and autonomously defines segment boundaries, reducing computational costs. We integrate SegINR into a two-stage TTS framework, using it for semantic token prediction. Our experiments in zero-shot adaptive TTS scenarios demonstrate that SegINR outperforms conventional methods in speech quality with computational efficiency.
High Fidelity Text-to-Speech Via Discrete Tokens Using Token Transducer and Group Masked Language Model
Jun 25, 2024
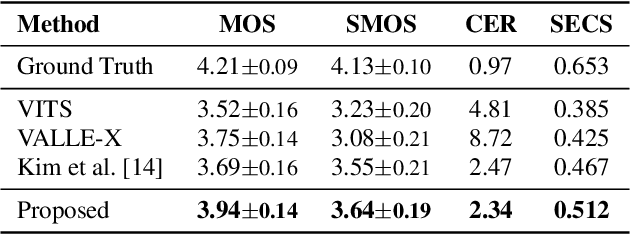
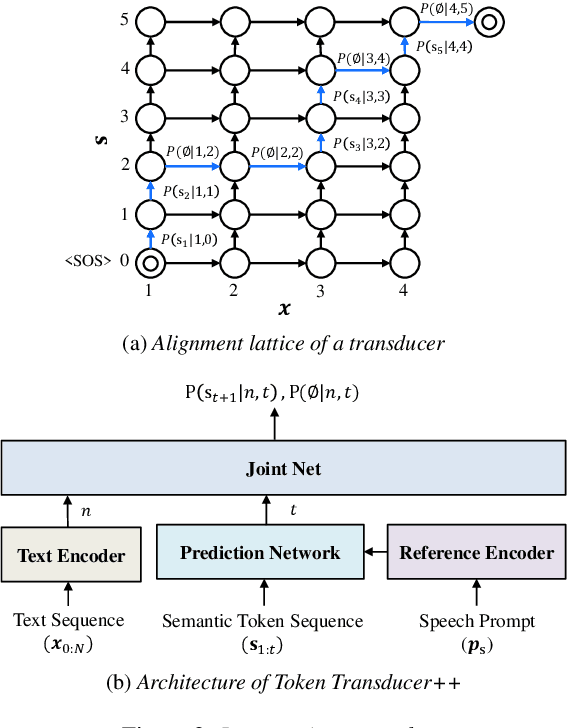

We propose a novel two-stage text-to-speech (TTS) framework with two types of discrete tokens, i.e., semantic and acoustic tokens, for high-fidelity speech synthesis. It features two core components: the Interpreting module, which processes text and a speech prompt into semantic tokens focusing on linguistic contents and alignment, and the Speaking module, which captures the timbre of the target voice to generate acoustic tokens from semantic tokens, enriching speech reconstruction. The Interpreting stage employs a transducer for its robustness in aligning text to speech. In contrast, the Speaking stage utilizes a Conformer-based architecture integrated with a Grouped Masked Language Model (G-MLM) to boost computational efficiency. Our experiments verify that this innovative structure surpasses the conventional models in the zero-shot scenario in terms of speech quality and speaker similarity.
Utilizing Neural Transducers for Two-Stage Text-to-Speech via Semantic Token Prediction
Jan 03, 2024

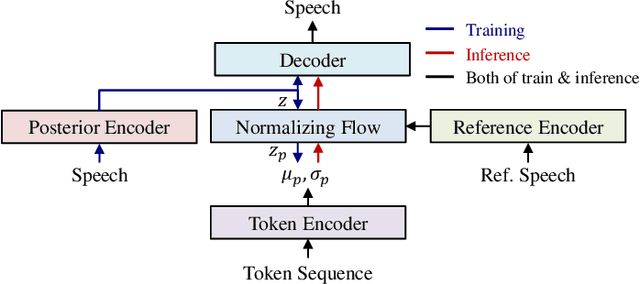

We propose a novel text-to-speech (TTS) framework centered around a neural transducer. Our approach divides the whole TTS pipeline into semantic-level sequence-to-sequence (seq2seq) modeling and fine-grained acoustic modeling stages, utilizing discrete semantic tokens obtained from wav2vec2.0 embeddings. For a robust and efficient alignment modeling, we employ a neural transducer named token transducer for the semantic token prediction, benefiting from its hard monotonic alignment constraints. Subsequently, a non-autoregressive (NAR) speech generator efficiently synthesizes waveforms from these semantic tokens. Additionally, a reference speech controls temporal dynamics and acoustic conditions at each stage. This decoupled framework reduces the training complexity of TTS while allowing each stage to focus on semantic and acoustic modeling. Our experimental results on zero-shot adaptive TTS demonstrate that our model surpasses the baseline in terms of speech quality and speaker similarity, both objectively and subjectively. We also delve into the inference speed and prosody control capabilities of our approach, highlighting the potential of neural transducers in TTS frameworks.
Efficient Parallel Audio Generation using Group Masked Language Modeling
Jan 02, 2024



We present a fast and high-quality codec language model for parallel audio generation. While SoundStorm, a state-of-the-art parallel audio generation model, accelerates inference speed compared to autoregressive models, it still suffers from slow inference due to iterative sampling. To resolve this problem, we propose Group-Masked Language Modeling~(G-MLM) and Group Iterative Parallel Decoding~(G-IPD) for efficient parallel audio generation. Both the training and sampling schemes enable the model to synthesize high-quality audio with a small number of iterations by effectively modeling the group-wise conditional dependencies. In addition, our model employs a cross-attention-based architecture to capture the speaker style of the prompt voice and improves computational efficiency. Experimental results demonstrate that our proposed model outperforms the baselines in prompt-based audio generation.
Latent Filling: Latent Space Data Augmentation for Zero-shot Speech Synthesis
Oct 05, 2023Previous works in zero-shot text-to-speech (ZS-TTS) have attempted to enhance its systems by enlarging the training data through crowd-sourcing or augmenting existing speech data. However, the use of low-quality data has led to a decline in the overall system performance. To avoid such degradation, instead of directly augmenting the input data, we propose a latent filling (LF) method that adopts simple but effective latent space data augmentation in the speaker embedding space of the ZS-TTS system. By incorporating a consistency loss, LF can be seamlessly integrated into existing ZS-TTS systems without the need for additional training stages. Experimental results show that LF significantly improves speaker similarity while preserving speech quality.
SNAC: Speaker-normalized affine coupling layer in flow-based architecture for zero-shot multi-speaker text-to-speech
Nov 30, 2022Zero-shot multi-speaker text-to-speech (ZSM-TTS) models aim to generate a speech sample with the voice characteristic of an unseen speaker. The main challenge of ZSM-TTS is to increase the overall speaker similarity for unseen speakers. One of the most successful speaker conditioning methods for flow-based multi-speaker text-to-speech (TTS) models is to utilize the functions which predict the scale and bias parameters of the affine coupling layers according to the given speaker embedding vector. In this letter, we improve on the previous speaker conditioning method by introducing a speaker-normalized affine coupling (SNAC) layer which allows for unseen speaker speech synthesis in a zero-shot manner leveraging a normalization-based conditioning technique. The newly designed coupling layer explicitly normalizes the input by the parameters predicted from a speaker embedding vector while training, enabling an inverse process of denormalizing for a new speaker embedding at inference. The proposed conditioning scheme yields the state-of-the-art performance in terms of the speech quality and speaker similarity in a ZSM-TTS setting.
An Empirical Study on L2 Accents of Cross-lingual Text-to-Speech Systems via Vowel Space
Nov 06, 2022With the recent developments in cross-lingual Text-to-Speech (TTS) systems, L2 (second-language, or foreign) accent problems arise. Moreover, running a subjective evaluation for such cross-lingual TTS systems is troublesome. The vowel space analysis, which is often utilized to explore various aspects of language including L2 accents, is a great alternative analysis tool. In this study, we apply the vowel space analysis method to explore L2 accents of cross-lingual TTS systems. Through the vowel space analysis, we observe the three followings: a) a parallel architecture (Glow-TTS) is less L2-accented than an auto-regressive one (Tacotron); b) L2 accents are more dominant in non-shared vowels in a language pair; and c) L2 accents of cross-lingual TTS systems share some phenomena with those of human L2 learners. Our findings imply that it is necessary for TTS systems to handle each language pair differently, depending on their linguistic characteristics such as non-shared vowels. They also hint that we can further incorporate linguistics knowledge in developing cross-lingual TTS systems.
Into-TTS : Intonation Template based Prosody Control System
Apr 04, 2022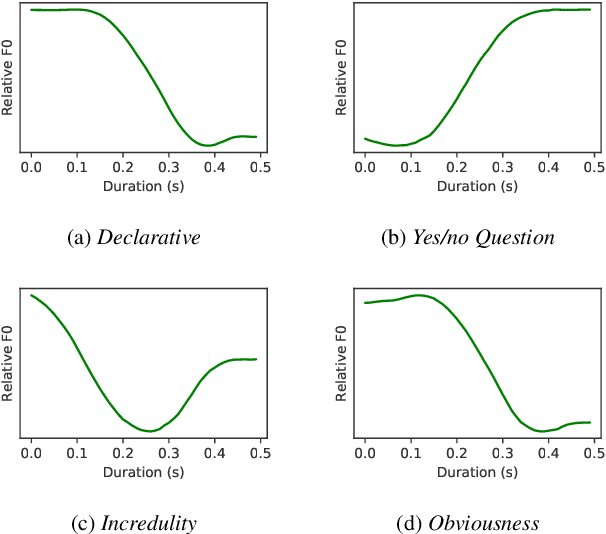

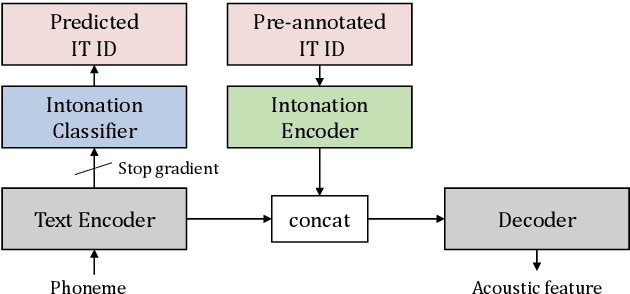
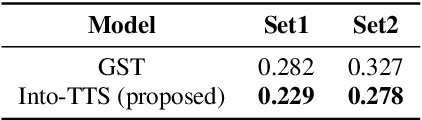
Intonations take an important role in delivering the intention of the speaker. However, current end-to-end TTS systems often fail to model proper intonations. To alleviate this problem, we propose a novel, intuitive method to synthesize speech in different intonations using predefined intonation templates. Prior to the acoustic model training, speech data are automatically grouped into intonation templates by k-means clustering, according to their sentence-final F0 contour. Two proposed modules are added to the end-to-end TTS framework: intonation classifier and intonation encoder. The intonation classifier recommends a suitable intonation template to the given text. The intonation encoder, attached to the text encoder output, synthesizes speech abiding the requested intonation template. Main contributions of our paper are: (a) an easy-to-use intonation control system covering a wide range of users; (b) better performance in wrapping speech in a requested intonation with improved pitch distance and MOS; and (c) feasibility to future integration between TTS and NLP, TTS being able to utilize contextual information. Audio samples are available at https://srtts.github.io/IntoTTS.
Transfer Learning Framework for Low-Resource Text-to-Speech using a Large-Scale Unlabeled Speech Corpus
Mar 29, 2022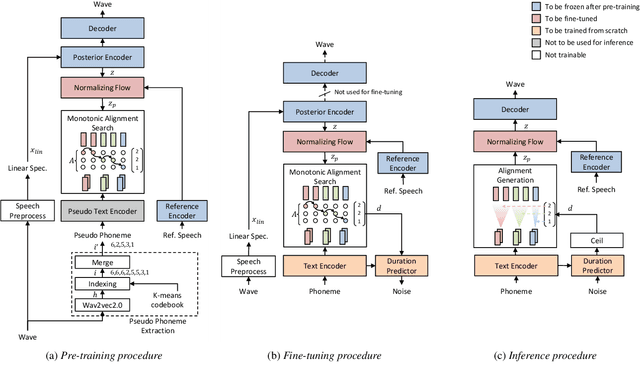
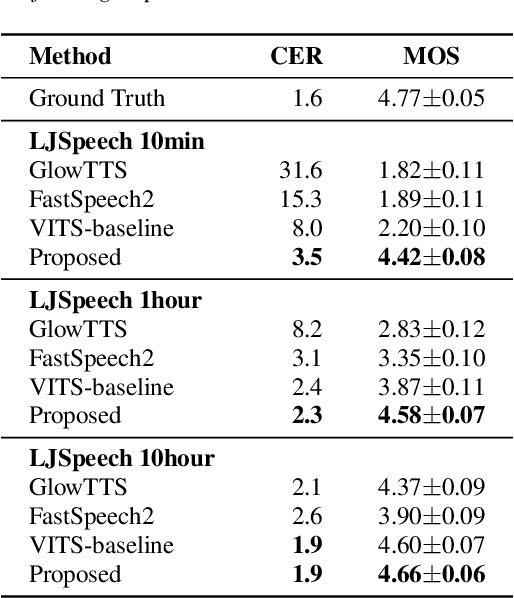
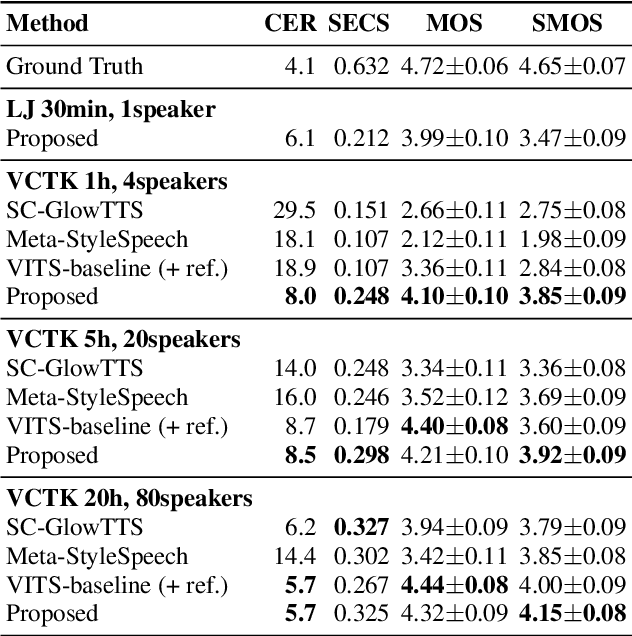
Training a text-to-speech (TTS) model requires a large scale text labeled speech corpus, which is troublesome to collect. In this paper, we propose a transfer learning framework for TTS that utilizes a large amount of unlabeled speech dataset for pre-training. By leveraging wav2vec2.0 representation, unlabeled speech can highly improve performance, especially in the lack of labeled speech. We also extend the proposed method to zero-shot multi-speaker TTS (ZS-TTS). The experimental results verify the effectiveness of the proposed method in terms of naturalness, intelligibility, and speaker generalization. We highlight that the single speaker TTS model fine-tuned on the only 10 minutes of labeled dataset outperforms the other baselines, and the ZS-TTS model fine-tuned on the only 30 minutes of single speaker dataset can generate the voice of the arbitrary speaker, by pre-training on unlabeled multi-speaker speech corpus.
SoftFlow: Probabilistic Framework for Normalizing Flow on Manifolds
Jun 09, 2020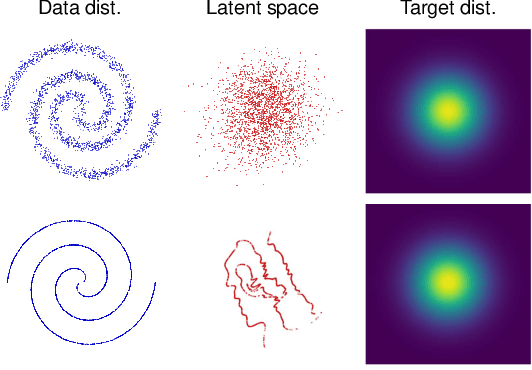
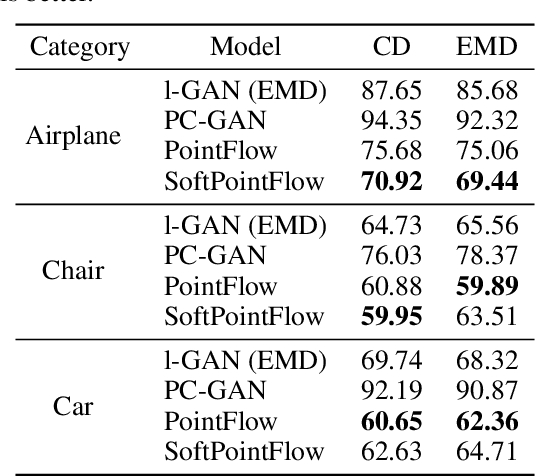
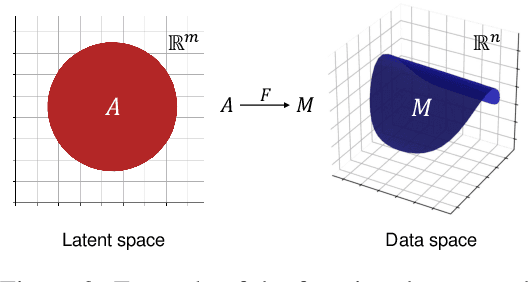

Flow-based generative models are composed of invertible transformations between two random variables of the same dimension. Therefore, flow-based models cannot be adequately trained if the dimension of the data distribution does not match that of the underlying target distribution. In this paper, we propose SoftFlow, a probabilistic framework for training normalizing flows on manifolds. To sidestep the dimension mismatch problem, SoftFlow estimates a conditional distribution of the perturbed input data instead of learning the data distribution directly. We experimentally show that SoftFlow can capture the innate structure of the manifold data and generate high-quality samples unlike the conventional flow-based models. Furthermore, we apply the proposed framework to 3D point clouds to alleviate the difficulty of forming thin structures for flow-based models. The proposed model for 3D point clouds, namely SoftPointFlow, can estimate the distribution of various shapes more accurately and achieves state-of-the-art performance in point cloud generation.