 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransfer Learning Framework for Low-Resource Text-to-Speech using a Large-Scale Unlabeled Speech Corpus
Paper and Code
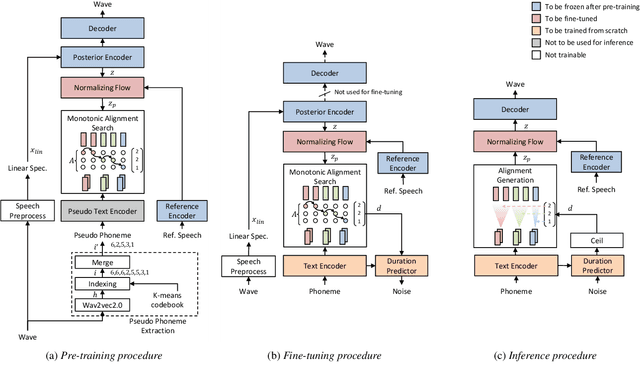
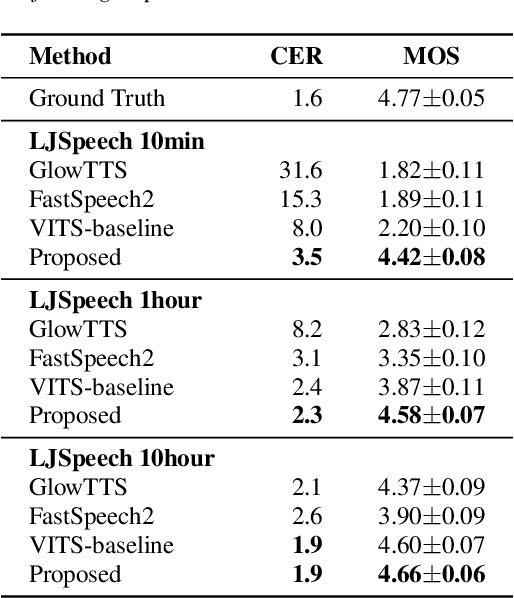
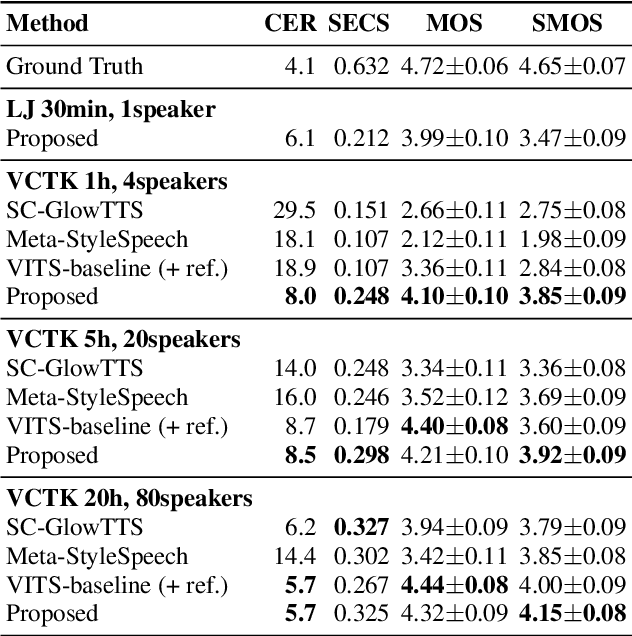
Training a text-to-speech (TTS) model requires a large scale text labeled speech corpus, which is troublesome to collect. In this paper, we propose a transfer learning framework for TTS that utilizes a large amount of unlabeled speech dataset for pre-training. By leveraging wav2vec2.0 representation, unlabeled speech can highly improve performance, especially in the lack of labeled speech. We also extend the proposed method to zero-shot multi-speaker TTS (ZS-TTS). The experimental results verify the effectiveness of the proposed method in terms of naturalness, intelligibility, and speaker generalization. We highlight that the single speaker TTS model fine-tuned on the only 10 minutes of labeled dataset outperforms the other baselines, and the ZS-TTS model fine-tuned on the only 30 minutes of single speaker dataset can generate the voice of the arbitrary speaker, by pre-training on unlabeled multi-speaker speech corpus.