Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGIST-AiTeR System for the Diarization Task of the 2022 VoxCeleb Speaker Recognition Challenge
Paper and Code
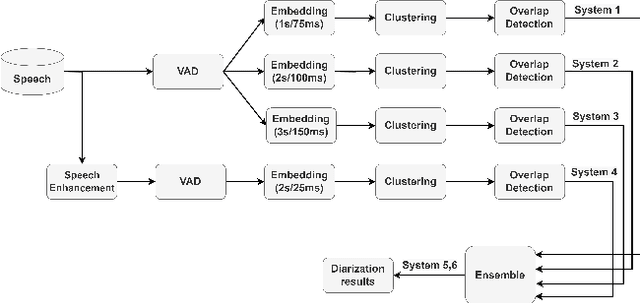
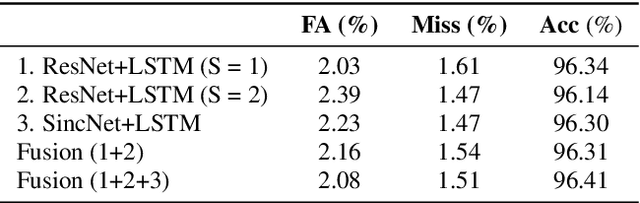
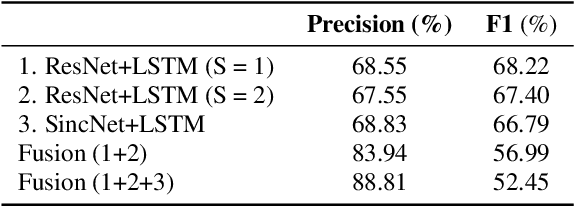

This report describes the submission system of the GIST-AiTeR team at the 2022 VoxCeleb Speaker Recognition Challenge (VoxSRC) Track 4. Our system mainly includes speech enhancement, voice activity detection , multi-scaled speaker embedding, probabilistic linear discriminant analysis-based speaker clustering, and overlapped speech detection models. We first construct four different diarization systems according to different model combinations with the best experimental efforts. Our final submission is an ensemble system of all the four systems and achieves a diarization error rate of 5.12% on the challenge evaluation set, ranked third at the diarization track of the challenge.
* 2022 VoxSRC Track4
View paper on