 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVarianceflow: High-Quality and Controllable Text-to-Speech using Variance Information via Normalizing Flow
Feb 27, 2023



There are two types of methods for non-autoregressive text-to-speech models to learn the one-to-many relationship between text and speech effectively. The first one is to use an advanced generative framework such as normalizing flow (NF). The second one is to use variance information such as pitch or energy together when generating speech. For the second type, it is also possible to control the variance factors by adjusting the variance values provided to a model. In this paper, we propose a novel model called VarianceFlow combining the advantages of the two types. By modeling the variance with NF, VarianceFlow predicts the variance information more precisely with improved speech quality. Also, the objective function of NF makes the model use the variance information and the text in a disentangled manner resulting in more precise variance control. In experiments, VarianceFlow shows superior performance over other state-of-the-art TTS models both in terms of speech quality and controllability.
Multimodal Speech Emotion Recognition using Cross Attention with Aligned Audio and Text
Jul 26, 2022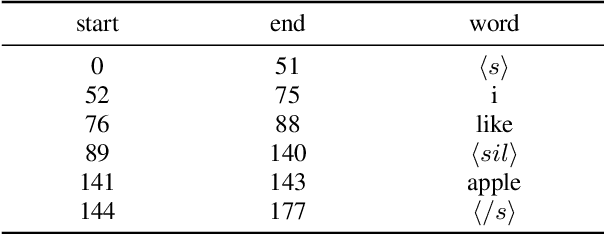
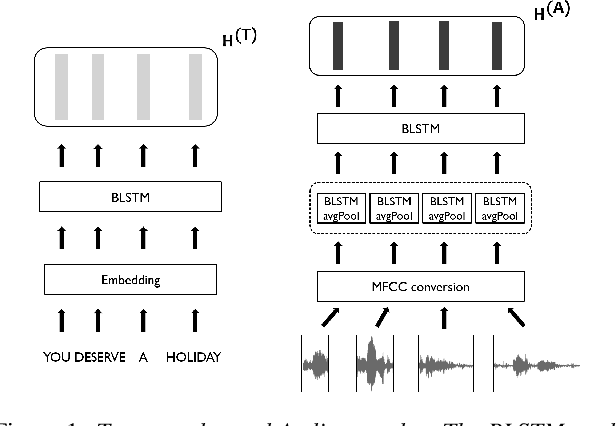
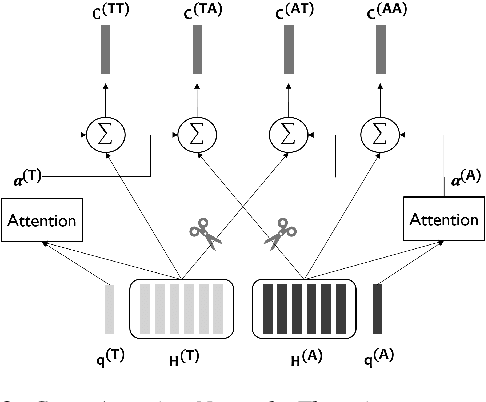
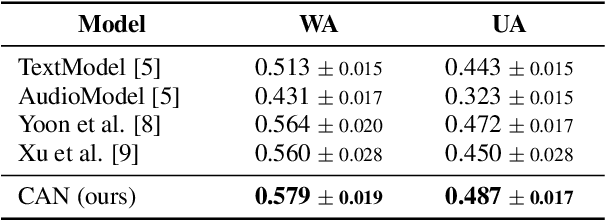
In this paper, we propose a novel speech emotion recognition model called Cross Attention Network (CAN) that uses aligned audio and text signals as inputs. It is inspired by the fact that humans recognize speech as a combination of simultaneously produced acoustic and textual signals. First, our method segments the audio and the underlying text signals into equal number of steps in an aligned way so that the same time steps of the sequential signals cover the same time span in the signals. Together with this technique, we apply the cross attention to aggregate the sequential information from the aligned signals. In the cross attention, each modality is aggregated independently by applying the global attention mechanism onto each modality. Then, the attention weights of each modality are applied directly to the other modality in a crossed way, so that the CAN gathers the audio and text information from the same time steps based on each modality. In the experiments conducted on the standard IEMOCAP dataset, our model outperforms the state-of-the-art systems by 2.66% and 3.18% relatively in terms of the weighted and unweighted accuracy.
* 5 pages, accepted by INTERSPEECH 2020
Statistical inference with implicit SGD: proximal Robbins-Monro vs. Polyak-Ruppert
Jun 28, 2022
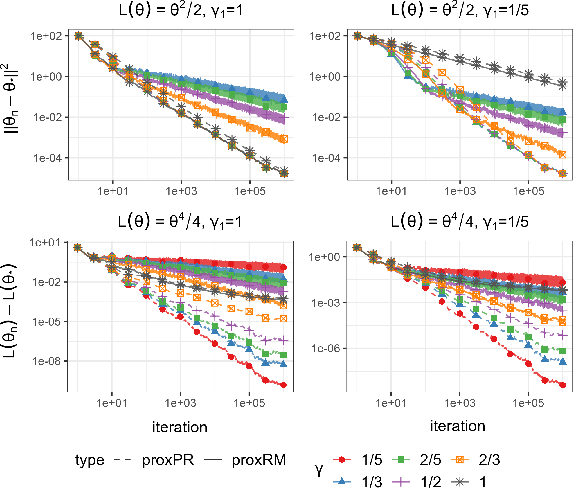
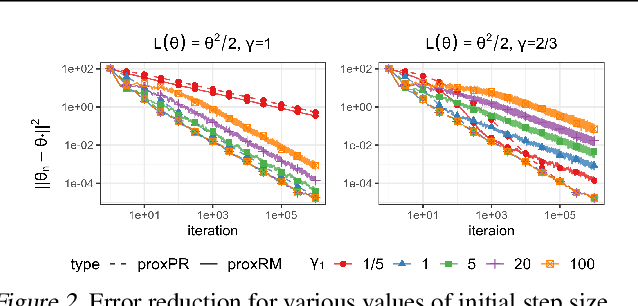
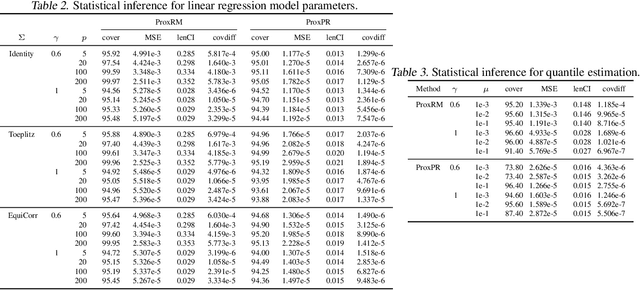
The implicit stochastic gradient descent (ISGD), a proximal version of SGD, is gaining interest in the literature due to its stability over (explicit) SGD. In this paper, we conduct an in-depth analysis of the two modes of ISGD for smooth convex functions, namely proximal Robbins-Monro (proxRM) and proximal Poylak-Ruppert (proxPR) procedures, for their use in statistical inference on model parameters. Specifically, we derive non-asymptotic point estimation error bounds of both proxRM and proxPR iterates and their limiting distributions, and propose on-line estimators of their asymptotic covariance matrices that require only a single run of ISGD. The latter estimators are used to construct valid confidence intervals for the model parameters. Our analysis is free of the generalized linear model assumption that has limited the preceding analyses, and employs feasible procedures. Our on-line covariance matrix estimators appear to be the first of this kind in the ISGD literature.
Fast and Accurate Deep Bidirectional Language Representations for Unsupervised Learning
Apr 17, 2020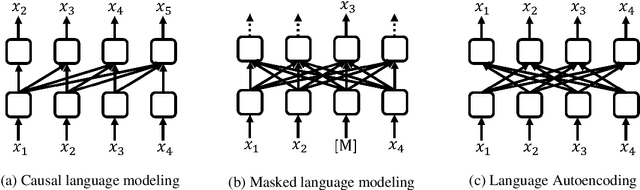
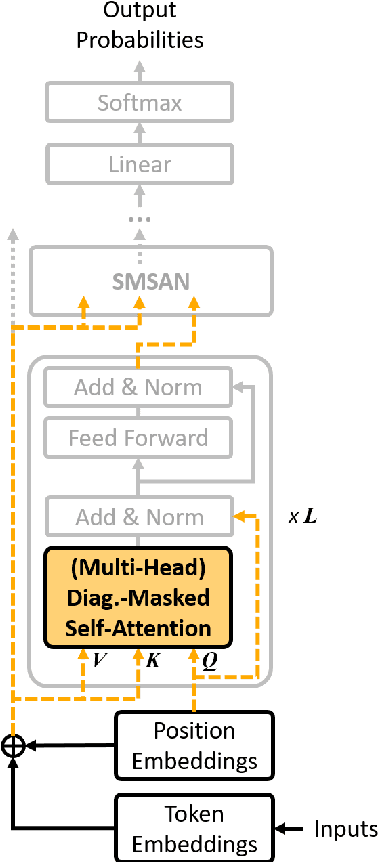
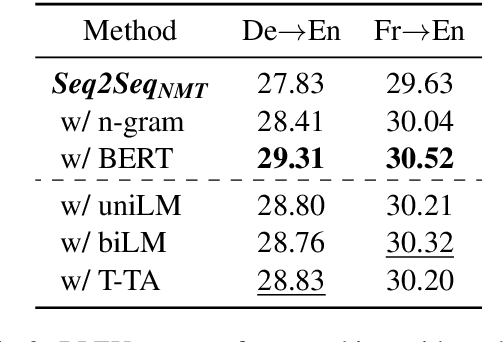
Even though BERT achieves successful performance improvements in various supervised learning tasks, applying BERT for unsupervised tasks still holds a limitation that it requires repetitive inference for computing contextual language representations. To resolve the limitation, we propose a novel deep bidirectional language model called Transformer-based Text Autoencoder (T-TA). The T-TA computes contextual language representations without repetition and has benefits of the deep bidirectional architecture like BERT. In run-time experiments on CPU environments, the proposed T-TA performs over six times faster than the BERT-based model in the reranking task and twelve times faster in the semantic similarity task. Furthermore, the T-TA shows competitive or even better accuracies than those of BERT on the above tasks.
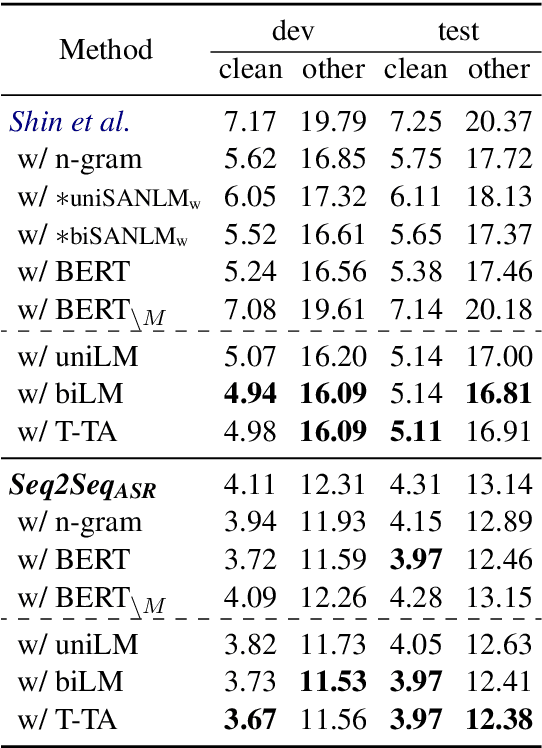
Effective Sentence Scoring Method using Bidirectional Language Model for Speech Recognition
May 16, 2019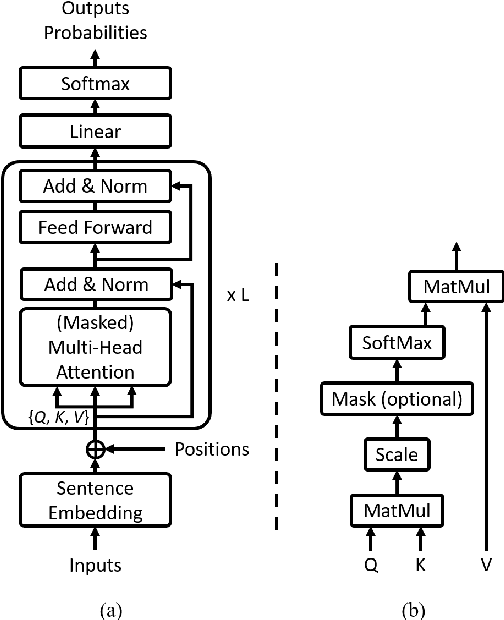
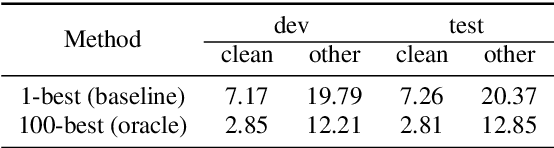
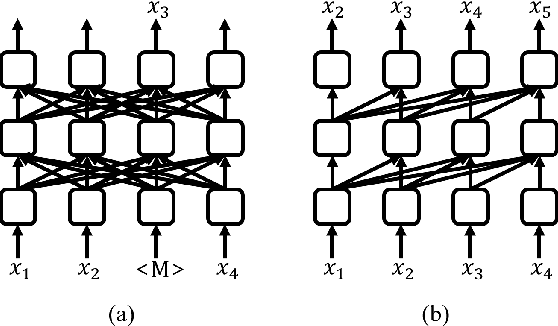
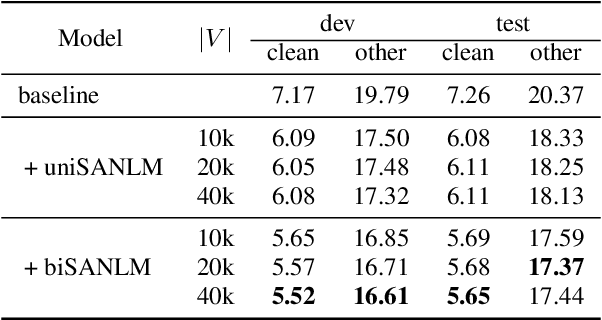
In automatic speech recognition, many studies have shown performance improvements using language models (LMs). Recent studies have tried to use bidirectional LMs (biLMs) instead of conventional unidirectional LMs (uniLMs) for rescoring the $N$-best list decoded from the acoustic model. In spite of their theoretical benefits, the biLMs have not given notable improvements compared to the uniLMs in their experiments. This is because their biLMs do not consider the interaction between the two directions. In this paper, we propose a novel sentence scoring method considering the interaction between the past and the future words on the biLM. Our experimental results on the LibriSpeech corpus show that the biLM with the proposed sentence scoring outperforms the uniLM for the $N$-best list rescoring, consistently and significantly in all experimental conditions. The analysis of WERs by word position demonstrates that the biLM is more robust than the uniLM especially when a recognized sentence is short or a misrecognized word is at the beginning of the sentence.