 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast and Accurate Deep Bidirectional Language Representations for Unsupervised Learning
Paper and Code
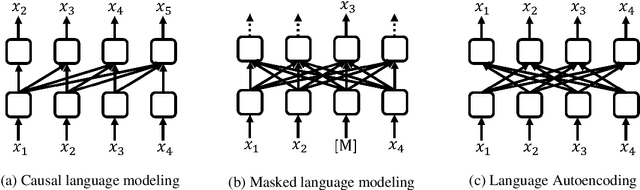
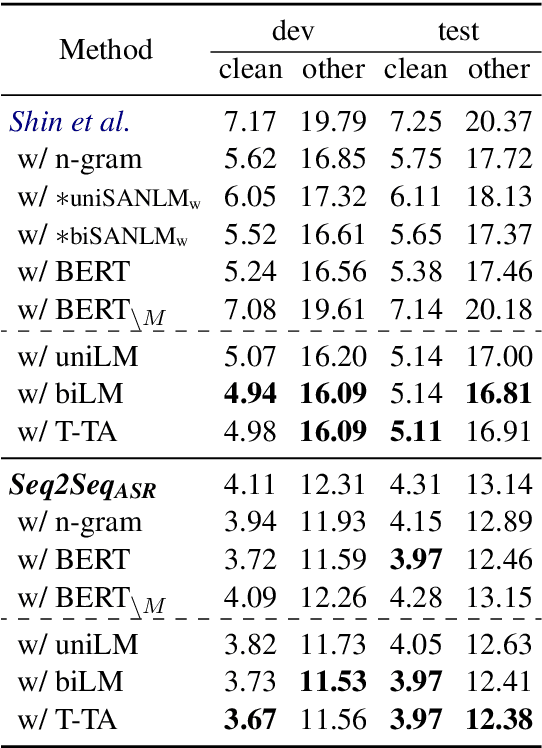
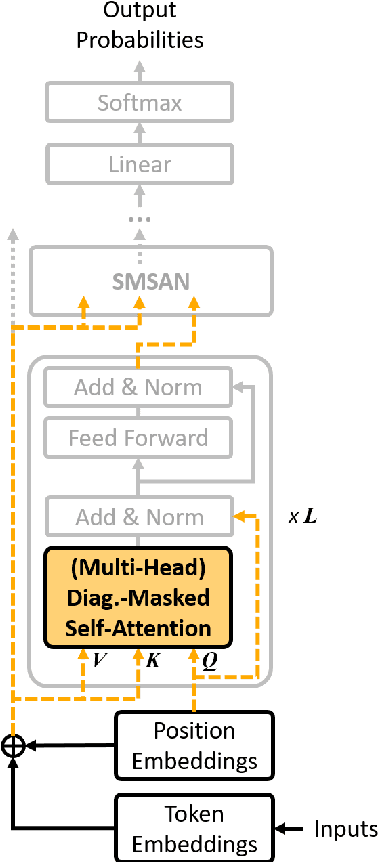
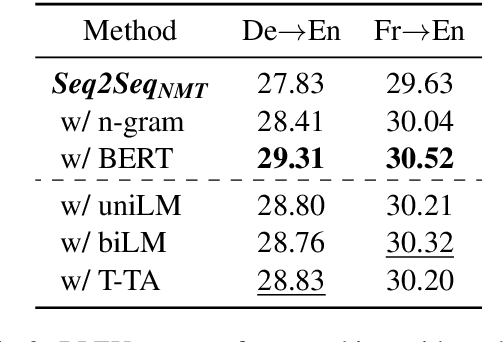
Even though BERT achieves successful performance improvements in various supervised learning tasks, applying BERT for unsupervised tasks still holds a limitation that it requires repetitive inference for computing contextual language representations. To resolve the limitation, we propose a novel deep bidirectional language model called Transformer-based Text Autoencoder (T-TA). The T-TA computes contextual language representations without repetition and has benefits of the deep bidirectional architecture like BERT. In run-time experiments on CPU environments, the proposed T-TA performs over six times faster than the BERT-based model in the reranking task and twelve times faster in the semantic similarity task. Furthermore, the T-TA shows competitive or even better accuracies than those of BERT on the above tasks.